รีวิว DGX Spark โคตรพลัง AI Super Computer บนโต๊ะทำงาน
By Arnon Puitrakul - 08 มิถุนายน 2026

เรื่องของเรื่องคือ เมื่อไม่นานมานี้ Google เปิดตัว Gemini 3.5 Flash ที่เขาบอกว่า มันฉลาดพอ ๆ กับ Gemini 3.1 Pro แต่เร็วกว่า เราก็ลองมาใช้ดู ปรากฏว่าฉลาดและเร็วจริง ไม่จ้อจี้ แต่มันกิน Token จนติด Limit ใน 30 นาทีแค่นั้น เลยคิดว่า น่าจะซื้อ AI Computer มาเพื่อทำงานอยู่นะ เลยจัดมาเลย กับ DGX Spark
Nvidia DGX Spark คืออะไร ?
หากพูดถึง Nvidia DGX System บางคนอาจจะไม่ได้รู้จัก Product นี้ของ Nvidia เท่าไหร่ เพราะน่าจะคุ้นเคยกับพวก RTX Product Line ที่เป็น GPU สำหรับใช้งานเพื่อการเล่นเกม หรือ RTX Pro สำหรับงานกลุ่ม Workstation มากกว่า แต่จริง ๆ แล้ว Nvidia เขาน่ากลัวกว่านั้นเยอะในโลกของ Super Computer เพราะเขามี DGX System
DGX System เป็น Product Line ที่เกิดมาเพื่องานทางด้าน Super Computing ใช้ในด้านพวก Scientifics Research และ AI Development เป็นหลัก ตัวแรกออกมาในรุ่น DGX-1 เมื่อปี 2016 มีหลายบริษัทซื้อไปใช้งานเยอะมาก และมันก็ได้รับการพัฒนาขึ้นมาเรื่อย ๆ จนเป็น DGX A100, H100, H200, GB300 รุ่นใหม่แรงขึ้นเรื่อย ๆ แต่ทั้งหมดนี้มันถูกออกแบบมาเพื่อทำงานใน Server ขนาดใหญ่ อยู่ในห้อง Server หรือ Data Centre เท่านั้น
จน Nvidia เปิดตัว Project Digit ออกมา ที่เขาบอกว่า เป็น Compacted AI Super Computer ที่เครื่องเล็กเท่า Mini PC แต่ให้พลังในการประมวลผล 1 PFLOPs ไปเลย สุดท้ายก็ออกขายจริงในชื่อ Nvidia DGX Spark
นอกจากที่ Nvidia จะปล่อย Refernece Version ทำเป็นเหมือนเครื่อง DGX ย่อส่วนน่ารัก ๆ เขายังปล่อยให้ OEM เอา SoC อย่าง GB10 ที่อยู่ในเครื่อง Reference Version ไปผลิตเป็นเครื่องของตัวเองได้ ทำให้เครื่องที่ออกมาในแต่ละ Brand จะมีสเปกเท่ากันทั้งหมดทุกอย่าง แม้แต่ Port การเชื่อมต่อ จนไปถึง CPU, GPU ข้างในทั้งหมดเลย จะมี Variance แค่ SSD ขนาด 1 และ 4 TB โดยเครื่องที่เราซื้อมาในวันนี้จะเป็นเครื่องจาก MSI ในรุ่น NVIDIA DGX Spark MSI EdgeXpert ที่ใส่ SSD มาให้ 4 TB
แกะกล่อง

ทุกคนคิดว่า คอมพิวเตอร์ราคาเกือบ 150k บาท กล่องจะเป็นยังไง ก็หน้าตาแบบนี้เลย ทำจากกระดาษทั่ว ๆ ไปนี่แหละ เป็นเรื่องธรรมชาติของพวก Enterprise Hardware ที่เขาไม่เอางบมาลงกับ Packaging เยอะ เพราะสุดท้ายก็โยนทิ้งอยู่ดี ด้านหน้ามีการพิมพ์บอกว่าเป็น EdgeXpert Series AI Supercomputer เข้าใจว่า MSI ทำมาเพื่อ Mini AI Computer เลย ด้านบนซ้ายมือ เราซื้อจาก Advice เลยมีสติ๊กเกอร์แปะอยู่ และด้านล่าง มีสติ๊กเกอร์บอกว่าไส้ในเป็น Nvidia Hardware อยู่

ด้านหน้ากล่องมีสติ๊กเกอร์แปะอยู่เต็มไปหมด

ตรงสติ๊กเกอร์ของ Nvidia มีการแปะบอกพวก Feature ต่าง ๆ ของเจ้าเครื่องนี้ด้วย ตั้งแต่ว่า ด้านในใช้ GB10 Superchip ที่เดี๋ยวเราจะมาคุยกันว่า มันคืออะไร กับมี RAM มาในตัว 128GB, มี ConnectX-7 NIC และรันโดย Nvidia DGX OS

เปิดกล่องออกมา เราจะเจอกับพวกคู่มือการใช้งาน และอุปกรณ์ต่าง ๆ อยู่ในกล่องหมด

เริ่มจากคู่มือ ที่ด้านล่างเขาจะมีรหัสผ่านสำหรับการ Headless Setup มาให้เรา เพราะเครื่องนี้ เราสามารถเสียบเมาส์ Keyboard และจอเพื่อตั้งค่าเครื่องได้ หรือ เราจะทำ Headless Setup แค่เสียบ Power และ Network ต่อ WiFi Hotspot และเริ่มการตั้งค่าได้เลย ที่ให้ดูได้ เพราะเรา Reset ค่า Factory Reset ใหม่แล้ว WiFi จะไม่ได้เป็นรหัสผ่านนี้แล้ว

อันนี้เป็น Adapter ที่ปลายด้านนึงจะเป็นหัว USB-C ปกติเลย ใช่แล้ว เราสามารถจ่ายไฟให้ DGX Spark ได้เพียงแค่การใช้สาย USB-C เท่านั้นเลย แต่เราจะเห็นว่า Adapter มีขนาดใหญ่มาก

ถ้าเราลองดูที่ Adapter ดี ๆ มันสามารถจ่ายไฟได้สูงสุด 48V/5A เท่ากับ 240W เลยทีเดียว ซึ่งมันก็ไม่น่าแปลกเท่าไหร่ที่ Adapter จะใหญ่ขนาดนี้ กับเขาเลือกใช้ของ Delta เป็น Brand ที่เราว่าโอเคเลย เท่าที่เราใช้งานมาวาง Adapter ไว้ในที่ ๆ อากาศไม่ค่อยถ่ายเทมากเท่าไหร่ และโหลดเครื่องหนัก ๆ ตัว Adapter มันไม่ได้ร้อนเท่าไหร่ ถือว่าโอเคเลย

พอเราใช้กระแสไม่เยอะมาก สายไฟที่แถมมา เลยไม่ได้มีความหนาอะไรมากมาย แต่จับดูแล้ว รู้สึกว่า เป็นสายที่คุณภาพใช้ได้เลย ถ้าไม่ทำอะไรแปลก ๆ ไม่น่าจะละลายเลย นี่แหละครับ คอมพิวเตอร์ราคาเกือบ 150k มีเท่านี้เลยจบละ
Nvidia DGX Spark

มาที่พระเอกของเรา อย่าง DGX Spark กันบ้าง ถ้าเราไปลองหาในท้องตลาดดู เราจะเจอ DGX Spark ที่ผลิตโดยหลาย Brand มาก ๆ เช่น Dell และ Lenovo ไส้ในทั้งหมด รวมถึงพวก Port การเชื่อมต่อต่าง ๆ เหมือนกันทั้งหมด แต่ต่างกันที่หน้าตา วัสดุ และเดาว่า การระบายความร้อนด้วย สำหรับเครื่องนี้เป็นของ MSI ใน EdgeXpert Series เปิดกล่องมา มันก็จะอยู่ในโฟมกันรอยอย่างดีเลย

ตัว Body เครื่องจะทำจากโลหะสีดำทั้งหมด ด้านบนจะมีรูระบายความร้อนเล็ก ๆ อยู่ด้านบนแค่นั้นเลย เรียบ ๆ

ตัวเครื่องขนาดเล็กมาก ๆ เล็กพอ ๆ กับมือเราเท่านั้นเอง เรียกว่าขนาดเท่ากับพวก Mini PC ที่เราเห็นกันทั่ว ๆ ไปที่ Mounting อยู่หลังจออะไรพวกนั้นได้เลย แต่ใครจะรู้ว่า ภายในนั้น Pack ของโหดอย่าง GB10 Superchip เข้าไปด้วย

เห็นถือเครื่องได้แบบนี้ เพราะตัวเครื่องมันไม่ได้หนักเลย อ่านจากสเปกเขาบอกว่า หนักเพียงแค่ 1.2 กิโลกรัมเท่านั้น จะเอาไป Mount ติดตั้งตรงไหน คิดว่าน่าจะง่ายมาก ๆ เราทดลอง 3D Print Mounting สำหรับใส่ใน Microrack ด้วย PLA บาง ๆ หน่อย ตัวเครื่องก็อยู่ได้สบาย ๆ

ด้านข้างจะออกแบบมา เหมือนด้านบนเป๊ะ ๆ คือ ส่วนหน้าจะมีรูสำหรับระบายอากาศเล็ก ๆ เดาว่า มันไม่ได้คิดมาเพื่อระบายอากาศขนาดนั้นหรอก รูเล็กนิดเดียวเอง

ด้านหน้า จะทำมาเป็นครึ่ง ๆ ครึ่งบนจะมี Logo MSI สีขาวสกรีนอยู่ และด้านล่างจะเป็นตะแกรงสำหรับให้อากาศผ่านเข้าไปเพื่อระบายความร้อนของตัวเครื่อง พออากาศมันเข้าจากด้านหน้า และส่วนหน้า ๆ มีรูอยู่ เลยคิดว่า มันไม่น่าจะเป็นส่วนที่ระบายความร้อน หรือดึงอากาศให้เข้าได้มากเท่าไหร่ ส่วนใหญ่ น่าจะออกแบบให้อากาศเดินทางเดียว จากหน้าไปหลัง

ด้านหลังแบ่งเป็น 2 ส่วนบนล่าง เหมือนด้านหน้าเลย ด้านบนจะเป็นรูสำหรับระบายความร้อน ถ้าเรามองเข้าไปข้างใน เราจะเห็น Heatsink อยู่ ก็คือ ลมเย็นจะถูกดูดเข้าจากด้านหน้าผ่าน Heatsink เอาความร้อนออกทางด้านหลัง
ส่วนด้านล่างเป็นส่วนสำหรับการเชื่อมต่อเป็นหลัก เริ่มจากซ้ายไปขวา จะเป็นปุ่มสำหรับเปิดปิดเครื่องซึ่งส่วนใหญ่เราจะไม่ได้ใช้ แค่เราเสียบปลั๊กเครื่องจะเปิดติดเองอยู่แล้ว ต่อไปเป็น USB-C ทั้งหมด 4 ช่อง ช่องแรกที่อยู่นอกวงกลมจะเขียนว่า PD IN สำหรับเสียบไฟเข้า และอีก 3 ช่องจะเป็น USB 3.2 Gen2x2 ที่ความเร็ว 20 Gbps สำหรับเสียบอุปกรณ์เพิ่มเติม, HDMI สำหรับเสียบออกหน้าจอ, 10 GbE สำหรับเสียบออก Network และสุดท้าย Port หน้าตาแปลก ๆ นี่คือ ConnectX-7 ที่ออกหัวละ 200G สำหรับเชื่อมต่อ DGX Spark หลาย ๆ เครื่องเข้าด้วยกันเป็น Cluster อาจจะเสียบตรง 2 เครื่องเข้าด้วยกัน หรือถ้าอยากไปสุดกว่านั้น เราสามารถซื้อ Infiniband Switch แบบเดียวกับที่เราใช้ใน Supercomputer มาต่อกันเป็น Cluster ขนาดใหญ่กว่านั้นได้ แต่ Switch ตัวนึง ก็...... น่าจะแพงกว่าเครื่องนี้หลายเท่าแล้ว

ด้านหลัง ตรงกลางจะเป็นช่องสำหรับระบายอากาศอีกส่วนนึง เดาว่าสำหรับ SSD ที่อยู่แถว ๆ นั้นพอดี เพราะต้องอย่าลืมว่า หากเราโหลด Model ขนาดใหญ่เข้า ๆ ออก ๆ ไม่แปลกที่ SSD จะร้อนเลย การมีช่องระบายอากาศแบบนี้ไว้ ก็ดีเหมือนกัน และเขายังมีเท้าที่ทำจากยางสำหรับกันลื่นไว้ด้วย

ในแต่ละขา เราจะเห็นว่ามันมีสกรูสำหรับยึดไว้ทั้ง 4 เท้าเลย โดยที่หากเราต้องการแกะตัวเครื่องออกมา Upgrade SSD หรือซ่อมบำรุงต่าง ๆ เราจะต้องไขสกรูส่วนนี้ออกไป

ปัญหาคือ ที่ด้านซ้ายบน มันมี Void Sticker แปะอยู่ด้วยอะสิ ถ้าแกะ ประกันจะขาดทันที ทำให้เราค่อนข้างสงสัยว่า เขาไม่อยากให้เรา Upgrade SSD เองเลยเหรอ คิดอีกมุมคือ มันก็จริงแหละ เพราะ MSI เอง เขามีขาย 2 Model ข้างในเหมือนกันทุกอย่าง รุ่นนึง SSD 1 TB อีกรุ่น 4 TB ถ้าให้แกะได้ ก็แค่ไปซื้อ SSD 4 TB มาใส่แทน แล้วใช้ Recovery Media ของ Nvidia Install ก็จบแล้ว จะขาย 4 TB ออกได้ยังไง หลัก ๆ ตัวเครื่องจะมีเท่านี้เลย ไม่มีอะไรเท่าไหร่ เน้นเสียบ ตั้ง แล้วลืมไปเลย ใช้อย่างเดียวพอ
เจาะลึก GB10 เบื้องหลังสมองอันทรงพลัง
ภายในตัวเครื่อง ไม่ว่าจะเป็น DGX Spark ที่ผลิตโดย OEM เจ้าไหนก็ตาม จะใช้งานไส้ในตัวเดียวกัน นั่นคือ GB10 ซึ่งมันไม่ใช่ GPU บ้าน ๆ ที่เราเห็นได้ตามคอมเล่นเกมทั่ว ๆ ไป ที่เน้นด้านการทำ 3D Rendering แต่ GB10 ที่ถูกคิดมาเฉพาะกับ Tensor Workloads และการย้ายข้อมูลขนาดใหญ่ไปมาระหว่าง Memory และ Computing
ถ้าเราดูโฆษณาที่ Nvidia เคลมบอกว่า นี่นะ GB10 สามารถคำนวณได้เร็วในระดับ 1 PFLOPS ไปเลยนะ แต่... มันมีเขียนตัวเล็ก ๆ อยู่ด้านล่างว่า สำหรับ FP4 Data Type เท่านั้น
เมื่อก่อน เวลาเราพูดถึง Computing Performance เรามักจะอ้างอิงที่ FP32 หรือ FP16 เป็นหลัก แต่การที่ Nvidia นำเสนอตัวเลข Performance ผ่านเลนส์ของ FP4 มันกำลังบอกเรามั้ยว่า ทิศทางของ AI ในอนาคต เรากำลังจะก้าวไปสู่วันที่ Throughput และ Density ของข้อมูล สำคัญกว่าความละเอียดของตัวเลขเกินความจำเป็น
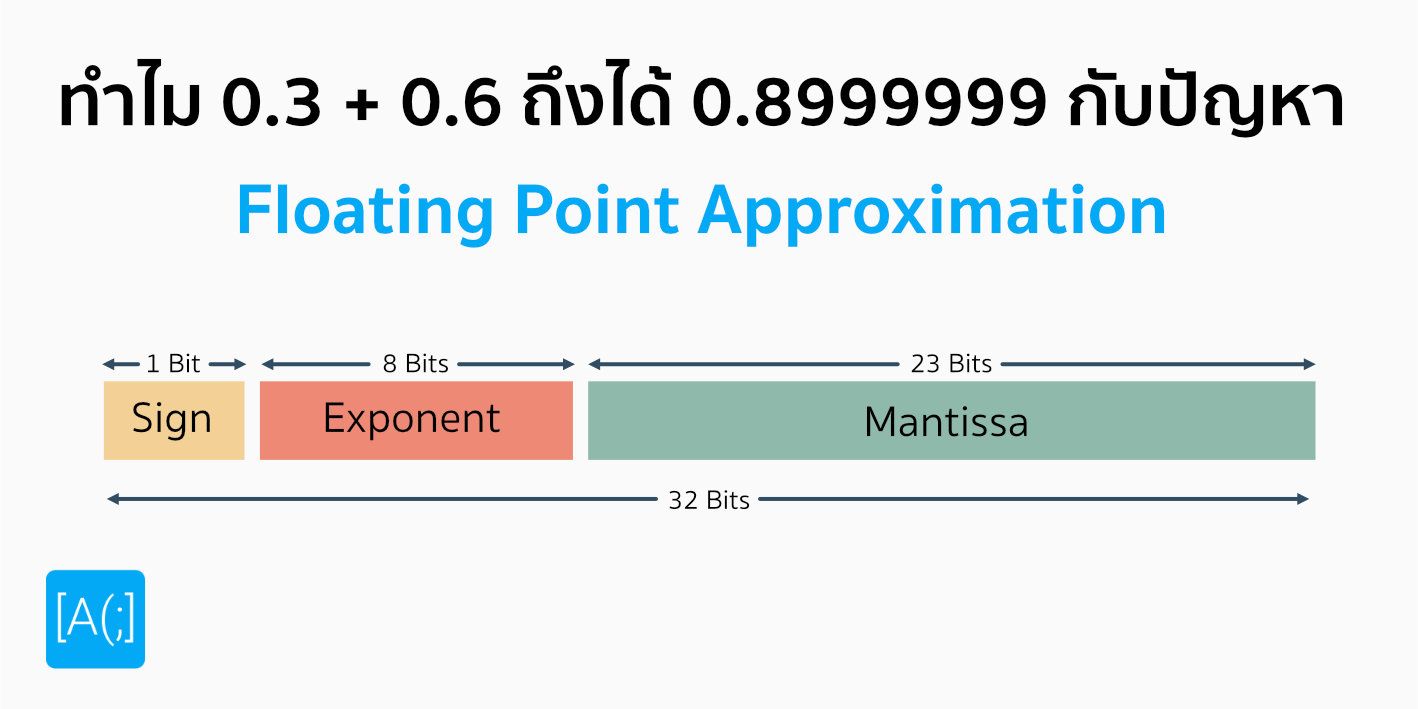
และเพื่อทำให้การทำงานเร็วขึ้น Nvidia ยังคิด Data Type สำหรับการทำ Quantisation ของตัวเองคือ NVFP4 เจ้านี่มันออกแบบมาฉลาดมาก ๆ มันไม่ใช่แค่การตัด Bit ออกดื้อ ๆ (เราเคยเขียนเรื่อง วิธีการที่คอมพิวเตอร์เก็บทศนิยมแบบปกติไว้ก่อนหน้านี้แล้ว) แต่มันทำงานด้วยกลไกพิเศษที่ช่วยรักษา Dynamic Range ของค่าเอาไว้ดีกว่า แม้จะใช้จำนวน Bit ในการจัดเก็บน้อยมาก ๆ
พอ DGX Spark รองรับ NVFP4 อย่างเต็มรูปแบบ นั่นหมายความว่ามันสามารถทำงานได้เร็วกว่าเดิม มี Throughput ที่สูงขึ้น, ลดการใช้งาน Memory นั่นหมายความว่า จำนวนข้อมูลที่ต้องวิ่งข้ามไปมาก็จะน้อยลง หรือกลับกัน ถ้าวิ่งได้เท่าเดิม เราจะสามารถส่งข้อมูลได้มากขึ้นในหนึ่งหน่วยเวลา ดังนั้นตัวเลข 1 PFLOPS ไม่ใช่ตัวเลขที่ โฆษณาเกินจริงเท่าไหร่ แต่มันคือการบอกว่า ถ้าเราใช้ Precision ที่ถูกต้อง เครื่องจะมอบพลังการทำงานได้ถึงระดับ PetaFLOPS เลยละ
ซึ่งมันเป็นเรื่องสำคัญมาก ๆ สำหรับงานด้าน Inference และการรัน Agentic Workflows ที่เน้นความเร็วในการต่อ และรองรับ Context ขนาดใหญ่
Nvidia DGX OS และการ Setup ครั้งแรก
DGX Spark ทุกเครื่องจะมาพร้อมกับ DGX OS ที่ไส้ในเป็น Ubuntu Linux ที่ติดตั้ง Software Stack และ Driver สำหรับการทำงานกับ Nvidia Hardware เรียกว่า กะเอาให้เปิดเครื่องมาใช้งานได้เลย โดยไม่ต้องติดตั้งพวก Driver อะไรให้ยุ่งยากเลย โดยเฉพาะเมื่อหลายปีก่อนที่ การจะติดตั้ง Nvidia GPU Driver ลงใน Ubuntu เป็นเรื่องที่ปวดหัวมาก
การ Setup DGX Spark ทำได้ง่ายกว่าที่คิดมาก ๆ สำหรับการติดตั้งรอบนี้ เราจะทำแบบ Headless หรือคือเสียบแค่ Power และ Network และใช้อุปกรณ์อื่นเข้าไป Config แทน เมื่อเราเสียบและรอสักพัก เราจะเจอ WiFi SSID ตามชื่อที่อยู่หน้าคู่มือ เมื่อเราเชื่อมต่อมันจะเด้งหน้า Captive Portal บอก URL ให้เรา Config เครื่องนี้
เปิดขึ้นมา เราจะเจอกับหน้าต้อนรับสวย ๆ เราจะเห็นเลยว่า เขาบอกว่า Welcome to EdgeXpert มันคือ Distribution สำหรับ MSI เครื่องนี้โดยเฉพาะเลย แต่ว่า จริง ๆ แล้ว เราสามารถ Recover โดยใช้ Media ของ Nvidia เอง Logo ของ MSI ก็จะหายไป กลายเป็น Software ตัวเดียวกับ DGX Spark ตัวที่ Nvidia ทำ
ขั้นตอนแรก มันจะให้เราสร้าง Account ให้เรียบร้อย ขั้นตอนนี้แหละ ที่ทำให้เรารู้ว่า เราสามารถใช้ Boot Media ของ Nvidia ได้ เราตั้งรหัสผ่านยาวเกินไปหน่อย ปรากฏ Login ไม่ได้ ต้อง Recover ด้วย Media ใหม่หมดเลย
ต่อไป มันจะให้เราเชื่อมต่อ WiFi สำหรับเครื่องที่ไม่ได้เสียบสาย Network เข้ามา
จากนั้นตัวเครื่อง มันจะทำการ Update พวก Software ต่าง ๆ ให้เราหมดเลย
เมื่อเสร็จแล้วเครื่องจะบอกว่า การติดตั้งเสร็จเรียบร้อย พอเรากด Getting Started มันจะเด้งไปที่หน้าคู่มือของ Nvidia Spark ที่ในนั้นจะมีพวก Cookbook สำหรับการติดตั้ง Software หรือ SDK สำหรับการทำงานให้เราเลย
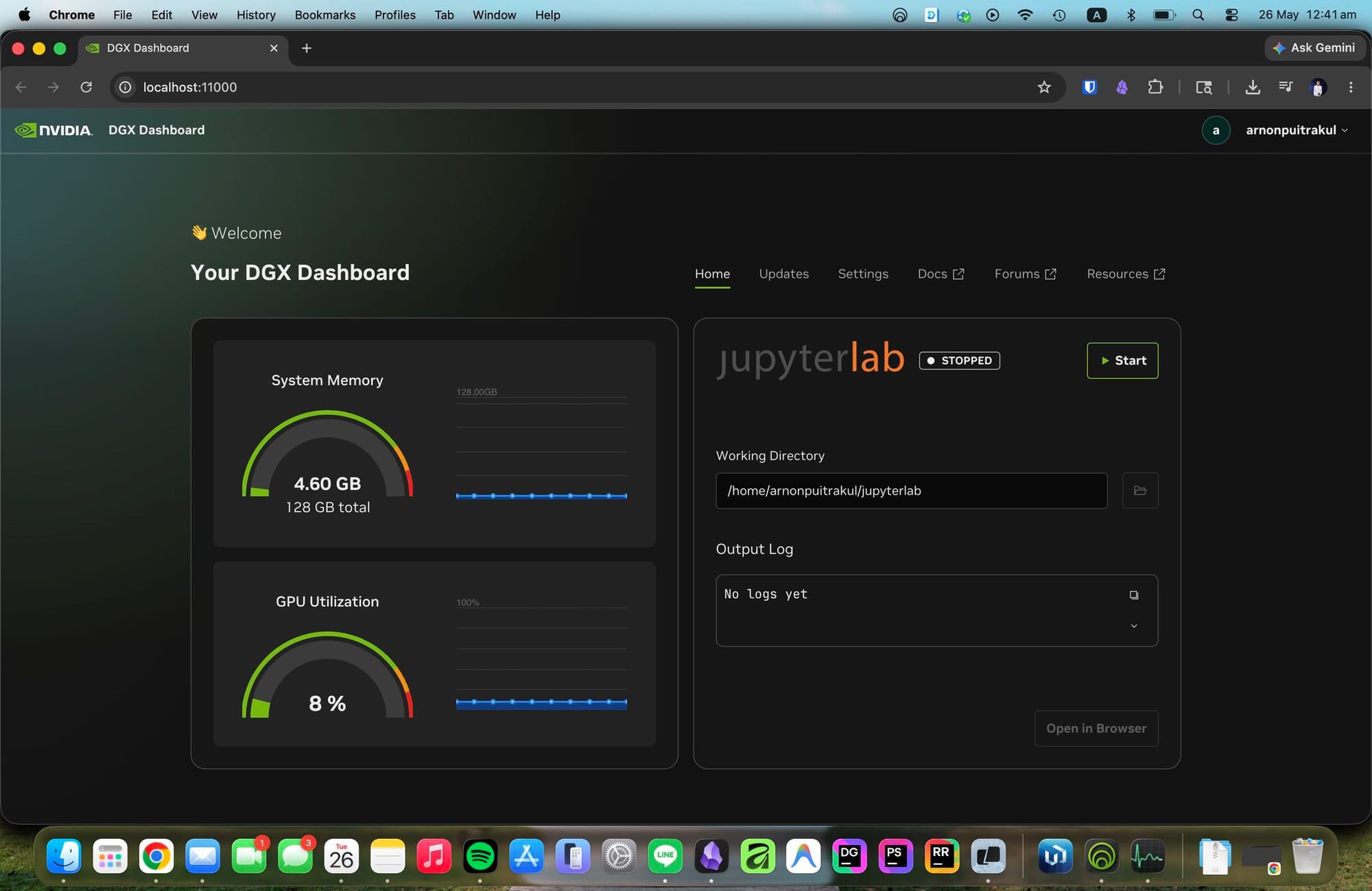
สุดท้าย Nvidia มี DGX Dashboard มาให้ จะเป็นโปรแกรมที่บอกพวก Stat ของเครื่อง และการ Update Software ต่าง ๆ
Setting Up
ส่วนของการ Implement เราเน้นไปที่การใช้งาน Chat และ Agent ให้กับสมาชิกภายในบ้านของเราเป็นหลัก ทำให้การ Setup มันจะไม่ใช่แค่การเปิด Terminal ทิ้งไว้ แต่เราจะสร้าง Service Layer ขึ้นมาครอบเพื่อให้บริการกับสมาชิกภายในบ้าน โดยเราจะให้มี Service ของทั้ง Chat และ Agent ได้เลย
Layer ล่างสุดคือ Inference Software ตอนแรกสุดเราใช้ Ollama แล้วได้ Performance แย่มาก ๆ ไว้จะไปเล่าในส่วนของ Performance เราเลยเปลี่ยนมาใช้ vLLM ซึ่งมันค่อนข้าง Optimise มาสำหรับ Nvidia Hardware ได้ดีมาก ๆ ซึ่งการ Setup เอาจริง ๆ ไม่ได้ง่ายขนาดนั้น กว่าจะทำได้ก็ใช้เวลาสักพักอยู่ ยังไม่นับเรื่องการรีด Performance ออกมาอีก แต่สุดท้ายก็ทำให้เราสามารถรัน Qwen3-Coder-Next-AWQ-4bit พร้อมกับ cyankiwi/gemma-4-26B-A4B-it-AWQ-4bit ได้ใน Memory Budget ที่เรามี และได้ Performance ที่ดีมากพอ ณ วันนี้ (อนาคตไม่แน่ อาจจะเปลี่ยน Model ตามไปเรื่อย ๆ ตัวไหนที่ Benchmark ดูดี ก็น่าเอามารันใช้เอง)
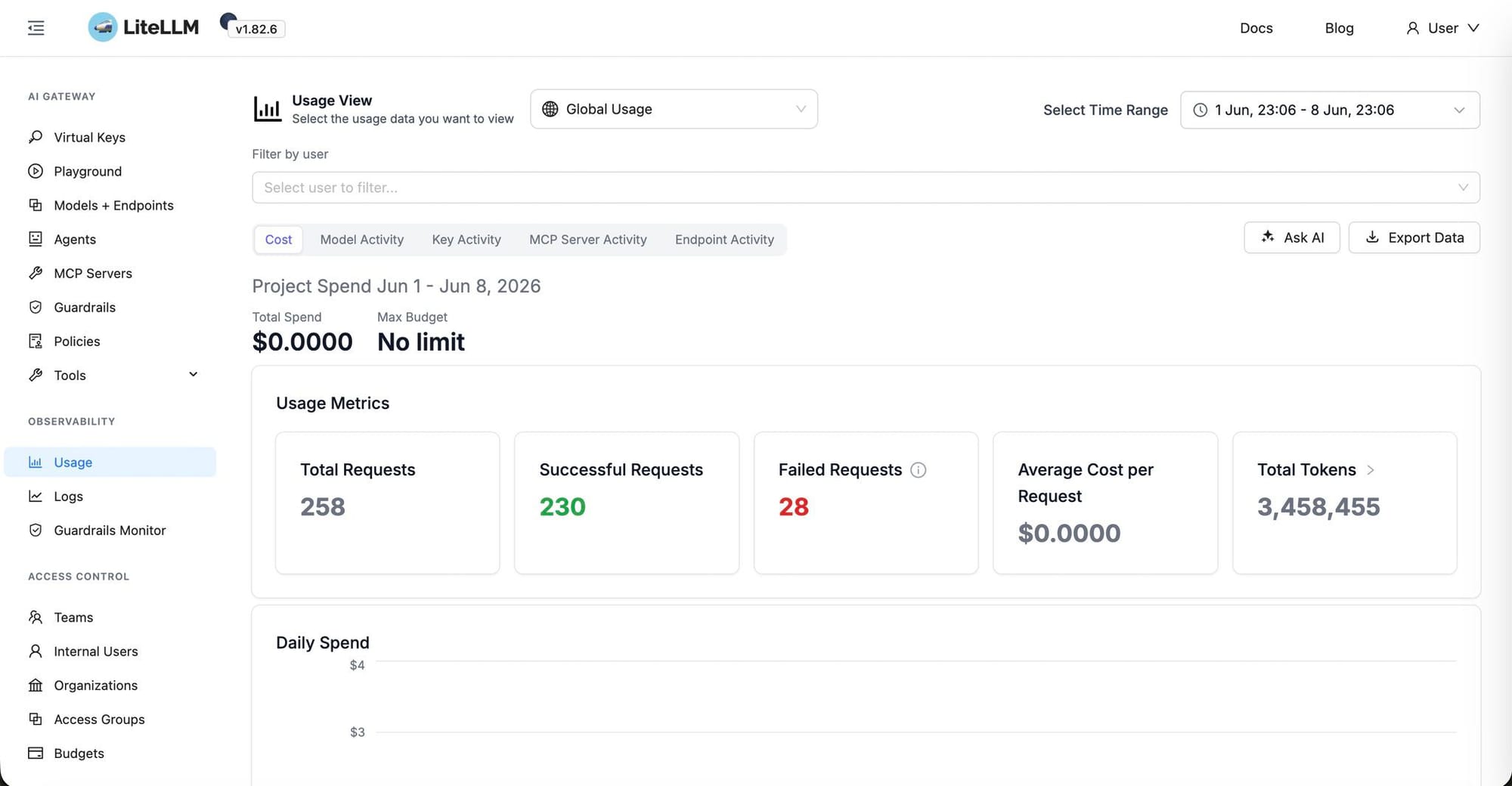
แต่ปัญหาคือ vLLM ไม่มีระบบ Server สำหรับ Management ใด ๆ ทั้งสิ้น เป็นเพียงแค่ Inference Service เท่านั้น ดังนั้น เราจะต้องมี Proxy มาคั่นกลางเพื่อให้เราสามารถจัดการ Model และเพิ่มความปลอดภัยไม่ให้คนอื่นเข้ามาใช้งานเครื่องเรามั่วซั่วด้วย Token Authentication ตอนแรกเราลังเลระหว่าง OpenRouter กับ LiteLLM สุดท้าย ไป ๆ มา ๆ จำไม่ได้ว่า ทำไมเลือก LiteLLM เหมือนกัน แต่ผลที่ได้ออกมาก็โอเคเลยละ
Layer สูงขึ้นไปอีกคือ Application ที่มาเชื่อมต่อ สำหรับ Chat เราเลือกใช้ OpenWeb UI คิดว่า น่าจะเป็น Application ยอดฮิตสำหรับการทำงานลักษณะแบบนี้อยู่แล้ว เราแค่ Setup และให้ Access กับคนในบ้าน แต่ปัญหาต่อไปคือ การ Search ข้อมูลผ่าน Internet ซึ่งเราหาตัวที่ฟรีอยู่ ตอนแรกใช้ DDGS แต่มีปัญหาว่า มัน Search ได้บ้างไม่ได้บ้าง เราเลยลองไปหาดูคนแนะนำ SearXNG ที่เป็น Metasearch Engine มา เลยลอง Host ใช้งานดู ผลที่ได้คือ ยอดเยี่ยมเลยละ
อีก Application ที่เราใช้งาน สำหรับงาน Coding คือ Cline เป็น Agentic Coding Extension บน Visual Studio Code ซึ่งเราแค่เลือก Provider เป็น OpenAI Compatible และใส่ API Endpoint พร้อมกับ API Key และเลือก Model ก็จะใช้งานได้เลย แบบคนสวย ๆ
และสุดท้ายที่เราพึ่งมาลองใช้แล้วติดใจมากคือ Hermes Agent ด้วยความที่มันรองรับ OpenAI Compatible เหมือนกัน เราสามารถเลือก Provider เป็น Custom Endpoint แล้วใส่ Endpoint กับ Key ก็เป็นอันเสร็จสิ้นแค่นั้นเลยแบบง่าย ๆ แต่ย้ำว่า ตอนที่เราสร้าง vLLM Container สำหรับ Model ที่ใช้งานกับ Agent พวกนี้ เราจะต้องเผื่อ Context Length ให้มันเพิ่มหน่อยนะ เพราะถ้าสั้นไปมันรันไม่ได้ หรือถ้ารันได้ มันจะต้องเสียเวลา Compact Context บ่อยเกินไป เปลือง Token มาก ๆ
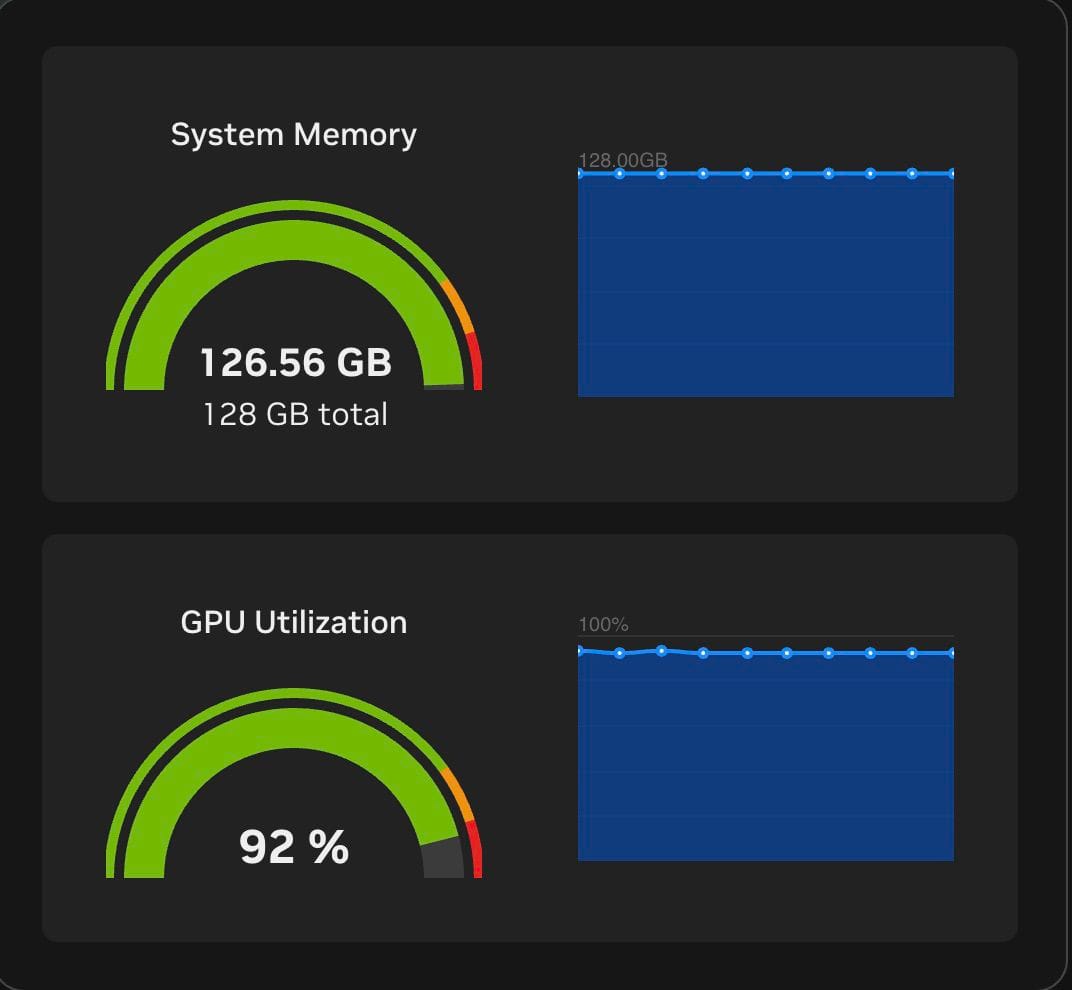
ผลที่ได้คือ หลังจาก Start Service Container ทั้งหมดแล้ว ก็คือเราใช้ RAM ไปแล้ว 126.56 GB เรียบร้อย ก็คือ มี Headroom เหลืออะไรเล็ก ๆ ได้อีกนิ๊ดเดียวแล้วละ ใช้คุ้มเกิ้น
เพิ่มเติมอีกนิด เรากำลังจะทำระบบกล้องวงจรปิดที่บ้านใหม่ เดินสาย UTP กันแบบฉ่ำ ๆ น่าจะเอา Frigate มารันเพิ่มด้วย ในนั้นคิดว่าจะรัน YOLOv9 ตัวเล็ก ๆ หน่อย ใช้กับ 1080p Video Feed สัก 10 ตัว คิดว่าน่าจะเหลือ ๆ ทำงานได้สบาย ๆ เลยละ (เมื่อหลายปีก่อน เราเอา RPi 2 มารันได้ 1 Stream แบบหน่วง ๆ หน่อยบน CPU แต่รอบนี้ใช้ GB10 บอกเลยว่า น่าสนุกสุด ๆ) ไว้เป็น Project ต่อในอนาคตละกันนะ
Performance : แรงไม่แรง อยู่ที่ Optimise
Nvidia เคลมว่า GB10 ที่อยู่ใน Spark เครื่องนี้ สามารถทำพลังการคำนวณได้ถึง 1 PFLOPS มันเท่ากับที่ DGX-1 ทำได้ในปี 2016 (แต่ใน Footprint ใหญ่กว่านี้เป็นสิบเท่า) ไม่แปลกที่ Nvidia จะเคลมว่า มันคือ AI Supercomputer ที่อยู่ในมือเรา
พอพูดแบบนี้ เราอาจจะคิดว่า มันต้องโคตรแรงมาก ๆ แรงกว่าพวก GPU ในตระกูล RTX ที่วางขายสำหรับเล่นเกมแน่ ๆ แต่จริง ๆ แล้ว ถ้าเราเอาสเปกมากางดู ความสามารถในการคำนวณจริง ๆ 1 PFLOPS บน FP4 ไม่ได้เป็นตัวที่แรงที่สุดเลยนะ หากเทียบจริง ๆ มันจะได้ประมาณ RTX 5070 และ RTX 5070 Super เท่านั้นเอง และถ้าไปเทียบกับพวก RTX 5090 อันนั้นโดดไป 3.35 PFLOPS บน FP4 หรือถ้าเทียบกับ Workstation & Server GPU ตัวดุ ๆ หน่อยอย่าง RTX6000 จะโดดไป 4 PFLOPS บน FP4 เช่นกัน ดังนั้น เราจะเห็นว่า จริง ๆ แล้ว มันไม่ได้เป็น Chip ที่แรงขนาดนั้นเลย แต่ถามว่า แล้วจุดเด่นมันอยู่ตรงไหนละ
คำตอบคือ Memory ของมัน ในตัว GB10 มี Unified Memory ขนาด 128GB ใส่มาให้เราเลย นั่นแปลว่า เราสามารถยัด Model ขนาดใหญ่มาก ๆ อย่าง GPT-OSS 120B เข้าไปได้สบาย ๆ เลย เท่าที่เราทดลอง เราสามารถยัด Model ขนาดสัก 30-40B แบบ Full-Precision หรือสักเกือบ ๆ 200B บน FP4 หรือ NVFP4 ได้ แต่เราคิดว่า ใช้จริงน่าจะอยู่สัก 70B แล้วเอาที่ ๆ เหลือไปใส่ Context Window กว้าง ๆ น่าจะคุ้มกว่าเยอะเลย
ตอนแรกสุด เราติดตั้ง Ollama ผลคือ Inference ที่โคตรช้ามาก ๆ ช้าจนแทบจะเรียกว่าใช้งานจริงไม่ได้เลย เรากำลังพูดถึง Inference Speed ที่ <10 tok/s เท่านั้นเอง แค่ว่า เวลาใช้งาน OpenWeb UI แล้วมันจะ Generate ชื่อ Title ยังใช้เวลาเป็นนาที นี่คือใช้ Gemma 4 26B Q8 แล้วนะมันยังไม่ไหวเลย เราเอา Model เดียวกันไปใช้กับ Hermes Agent ก็คือ นานจน Timed Out ไปเลย เราเลยไปหาข้อมูลในพวก Forum ของคนที่ใช้ Spark ปรากฏว่า Ollama ที่ใช้ Llama.cpp มันไม่ค่อย Optimise สำหรับ Spark สักเท่าไหร่ แต่ถ้าอยากได้สุดจริง ๆ เขาแนะนำ vLLM ปรากฏว่า พอมาใช้เท่านั้นแหละ โลกเปลี่ยนไปเลย ลื่นมาก ๆ เผลอ ๆ เร็วพอ ๆ กับ Pro Model ใน Frontier ได้เลย เรียกว่าใช้งานได้จริงเลยแหละ
เท่าที่เราทดลองใช้งาน Gemma 4 26B ใน OpenWeb UI เราสามารถทำ ความเร็วในการอัด Token ได้ 60-90 Token/s เลยทีเดียวซึ่งถือว่าสูงมาก ๆ จนเรียกว่าใช้งานได้จริงได้สบาย ๆ และเราได้ดูคลิปของ Alex Ziskind เขาเอาลองเอา Concurrent ยัดเข้าไป ปรากฏว่า มันทำ Throughput รวมได้สูงขึ้นอีก เราเลยเอาไปลองใช้งานกับ Sub-Agent ตอนแรกเราคิดว่า มันจะช้าลงเยอะมาก ๆ แบบ 50 Tok/s กับ 10 Tok/s อะไรแบบนั้น แต่จริง ๆ แล้วมันไปได้เยอะกว่านั้นมาก ๆ เรากำลังพูดถึง 42-48 Tok/s แทบจะไม่ลดเลย เร็วเหมือนเดิมเลย และผลของเราก็สอดคล้องกับ Ziskind เลยละ คิดว่า ถ้าอัด Concurrent เยอะกว่าที่ทดสอบตอนนี้ เราจะได้ Throughput ที่สูงมาก ๆ แน่ ๆ
แต่นี่ก็ยังไม่สุดนะ เพราะ GB10 มันทำงานอยู่บน Blackwell Architecture ที่ไส้ในมี 2nd Generation Transformer Engine ที่มันคำนวณพวก NVFP4 ได้โคตรเก่งมาก ๆ เรากำลังพูดถึง Throughput ที่ก้าวกระโดด 2-4 เท่า เมื่อเทียบกับ AWQ ที่เรากำลังใช้งานอยู่ตอนนี้ และ NVFP4 มันใช้เทคนิค Microscaling เพื่อรักษา Perplexity ของ Model ได้ดีมาก ๆ แม้จะเป็น 4-bit Quantisation ก็ตาม
ปัญหาคือ ณ วันที่เขียน เรายังไม่สามารถรัน Model ที่เป็น NVFP4 ได้จาก Official Image ของ vLLM แต่จะต้องใช้ Image ที่ Community ทำขึ้นมา ซึ่งเราทดลองใช้แล้ว มัน Config ยากกว่าที่ไว้เยอะมาก ๆ และบาง Model อาจจะรันได้ช้ากว่า Model ที่ใช้ AWQ ด้วยซ้ำ เราเลยยังคงมาใช้ AWQ อยู่เหมือนเดิม คาดหวังว่าตอน vLLM 0.23 ออกมา น่าจะแก้ปัญหานี้แล้วนะ ทำให้เรารัน NVFP4 ได้สักที ถึงตอนนั้นเราจะได้เห็น Tok/s แบบสุด ๆ สักที
ดังนั้นเราบอกเลยว่า จริง ๆ GB10 ที่ถึงจะบอกว่า มันแรงเพียงแค่ 1 FPLOPS แต่ตัวมันจริง ๆ ก็ไม่ได้ช้าอย่างที่หลายคนคิดเลย มันทำงานได้เร็วมาก ๆ แค่ว่า เราจะรีดพลังของมันออกมาได้แค่ไหน เราคิดว่าตอนนี้เราน่าจะรีดมันออกมาได้แค่ 40-60% เท่านั้นเอง มันน่าจะแรงได้มากกว่านี้แน่ ๆ มันต้องการ การ Optimise ที่มากกว่านี้เพื่อจะเอา Performance ซ่อนออกมาให้ได้ คิดว่าจะต้องรออีกสักหน่อย Software Stack จะ Mature มากกว่านี้หน่อย
Power & Thermal
หลายคนอาจจะคิดว่า Performance ขนาดนี้ มันน่าจะกินไฟ และร้อนมากแน่ ๆ ยิ่งบอกว่าเป็น Supercomputer อีก ร้อนกินไฟสุด ๆ ไปเลยแน่ ๆ แต่ ลองดู Adapter เขาก่อน ใส่มาแค่ 240W เท่านั้นแปลว่า ไม่ว่ายังไง โหลดไฟจะไม่เกิน 240W แน่ ๆ เท่าที่ได้ทดลองมา มันรันอย่างมากจริง ๆ ไม่เกิน 100-110W เท่านั้นเอง ซึ่งเอา Worst Case เลย รันกันไม่หยุดสักวินาทีเดียว 24 ชั่วโมง เราจะกินไฟประมาณ 2.64 kWh ถ้าคิดหน่วยละ 5.5 บาท จะได้ค่าไฟวันละ 14.52 บาทเท่านั้นเอง ถือว่าไม่ได้เยอะมากขนาดนั้นเลย
และถ้ามันกินไฟน้อย นั่นแปลว่า ความร้อนที่ออกมาก็น้อยด้วยเหมือนกัน เราสามารถเอาไปวางในห้องที่ไม่ต้องเปิดแอร์มันก็อยู่ได้สบาย ๆ เราวางไว้ในห้องชั้น 2 ของบ้าน และมี Synology NAS และ เครื่อง 3D Printer กำลังทำงานอยู่ ห้องร้อนประมาณ 34 องศา มันก็ยังทำงานได้อยู่แบบสบาย ๆ เลย ในช่วง Full Load กำลัง Generate Token แบบฉ่ำมาก ๆ สูงสุดเท่าที่เราเจอมาแค่ 80 องศาเท่านั้นเอง และถ้าเปิดแอร์นั่งอยู่ข้าง ๆ เลย จะอยู่ไม่เกิน 65 องศา และเสียงพัดลมเรียกว่า แทบไม่มีเลย เบากว่าเสียง HDD ที่ใส่อยู่ใน NAS เราซะอีก ดังนั้นไม่ต้องเป็นห่วงเรื่องนี้เลย
มันเกิดมาเพื่ออะไร ?
ถ้าเราเอาตัวเลขพลังของการคำนวณมากางเทียบกับพวก RTX GPU บอกเลยว่า สู้ไม่ได้แน่นอน ทำให้เราเกิดคำถามว่า มันเกิดมาเพื่ออะไร มันอยู่ตรงไหนของ Workflow การทำงานของเรา
เราว่าคำตอบมันอยู่ที่ สเกลงาน ในการเล่นเกม หรือรันงาน Graphic หนัก ๆ พลังในการ Compute คือ พระเอกของเรื่อง มันคือพลังในการคำนวณพวกแสงเงาในเสี้ยววินาที แต่ในโลกของ AI โดยเฉพาะ LLM พลังมันไม่ใช่พระเอกอีกต่อไปแล้ว
เพราะ LLM ไม่ได้สนใจแค่ว่า GPU เราจะคำนวณได้เร็วแค่ไหน แต่มันต้องเริ่มจากถามว่า เรายัด Model ขนาดใหญ่นี้ลงใน Memory ได้หรือไม่ ถ้า Model มีขนาดสัก 70B Parameter แต่ GPU มี VRAM แค่ 16 GB หรือ 24GB ต่อให้มันจะคำนวณเก่งแค่ไหน แต่มันก็ยังรันขึ้นมา Inference ไม่ได้ หรือถ้าฝืนด้วยการแชร์กับ RAM ของเครื่อง Overhead ก็จะสูงจนใช้งานไม่ได้เลย
ในจุดนี้แหละคือจุดที่ GB10 ฉายแสงด้วย VRAM ขนาด 128 GB ทำให้เราสามารถรัน Model ขนาดใหญ่ ๆ ที่ฉลาด ๆได้ในเครื่องโดยไม่ต้องพึ่งพาการเชื่อมต่อผ่าน PCIe ที่ทำงานได้ช้ากว่า อีกจุดที่ GB10 ได้เปรียบคือ การขนส่งข้อมูลระหว่าง Memory และ Compute Unit ต่าง ๆ
ในพวก Gaming GPU เขาเน้นความเร็วในการส่งข้อมูลภาพ แต่ GB10 แตกต่างออกไปตรงที่มันถูกออกแบบมาให้มี Memory Bandwidth ที่กว้างพอจะป้อนข้อมูลมหาศาลจาก Model สู่ Compute Unit ได้อย่างต่อเนื่อง ถ้าใครเรียนมาจะรู้ว่า มันคือหัวใจสำคัญของ Performance ที่ดีในงานของ AI Inference เลยก็ว่าได้
ทำให้ส่วนตัวเรารู้สึกว่าพวก RTX GPU เหมือนพวกรถสปร์ต ที่ทำความเร็วได้ดีมาก ๆ แต่ GB10 มันคือ รถบรรทุก ที่แม้ว่ามันจะไม่สามารถวิ่งเร็วได้เท่ากับรถสปอร์ต แต่มันขนของได้เยอะ วิ่งได้หนัก และวิ่งไปหาเป้าหมายได้อย่างมั่นคงต่อเนื่อง ดังนั้นงานที่มันเกิดมาจากจริง ๆ ไม่ใช่การรันเกม AAA หรือ Render 3D หนัก ๆ แต่เป็นสอมงสำหรับ LLM และการทำ Fine Tuning หรือการรัน AI Agent ที่ต้องอาศัย Context Window มหาศาล
สรุป : พลัง 1 PFLOPS บนโต๊ะทำงาน มันวิเศษมาก

ตั้งแต่แกะกล่องมา การตั้งค่าที่ทำเอาปวดหัวอาทิตย์จนสุดท้ายมันกลายเป็น Service ที่ใช้งานได้จริง เราได้เรียนรู้เลยว่า Nvidia DGX Spark มันไม่ได้เป็นแค่ Mini PC ที่แรงเฉย ๆ แต่มันคือการย่อส่วนโครงสร้างพื้นฐานแห่งอนาคตอย่างการใช้ AI มาทำงานในพื้นที่เล็ก ๆ ในบ้านของเรา มันทำให้เราเห็นความเป็นไปได้ที่ไร้ขีดจำกัด มันเหมือนเป็นสนามเด็กเล่นของเราในบ้านที่ปลดล๊อคให้เราสร้างของเล่นสนุก ๆ ออกมาอีกเยอะมาก ว่าแต่วันนี้เราจะสร้างอะไรออกมาดีละ
Related Posts

รีวิว Bambu Lab H2C กับ Vortex System ที่ช่วยลดพลาสติกเหลือทิ้ง แลกกับราคามหาศาล
28 มิถุนายน 2026 - 4 min readเมื่อหลายอาทิตย์ก่อน เราเข้าวงการใหม่ที่เข้าแล้วออกไม่ได้อีกแล้วกับ 3D Printer เครื่องรุ่น Top สุด อย่าง Bambu Lab H2C วันนี้ เราได้ใช้งานมาหลักหลายร้อยชั่วโมงแล้ว เราจะมาเล่าประสบการณ์การใช้งานให้อ่านกันว่า เราคิดยังไงกับเจ้าเครื่องนี้กัน...

รีวิว 2 ปีกับ iPad Pro M4 ที่โดนเนิฟด้วย iPadOS
26 มิถุนายน 2026 - 2 min readเมื่อไม่กี่วันก่อน เราเห็น Memories ใน Facebook ที่เราถ่ายตอนได้ iPad Pro M4 มาวันแรก แบบเห้ย 2 ปีผ่านไปเร็วมาก ๆ อย่างไม่น่าเชื่อ เราเอามันไปใช้เป็นเครื่องหลักในการทำ Content เลยก็ว่าได้ วันนี้เราจะมาเล่าให้อ่านกันว่าผ่านมา 2 ปี ทำไมเรายังไม่เปลี่ยนไปใช้รุ่นใหม่...

รีวิว iBasso DC04U DAC ตัวเล็ก ๆ แต่พลังล้นเกิ้น
23 มิถุนายน 2026 - 3 min readเราได้ DAC ตัวใหม่มา กับ iBasso DC04U ตอนแรกว่าจะไม่รีวิวแล้วนะ แต่พอมานั่งอ่าน กับได้ลองใช้จริง ๆ มันมีอะไรที่น่าสนใจมาก ๆ กับเสียงที่ได้สุดยอดมากจริง ๆ จนต้องมาเล่า อยากรู้ว่าเป็นยังไง อ่านได้ต่อได้เลย...
รีวิว DGX Spark โคตรพลัง AI Super Computer บนโต๊ะทำงาน
08 มิถุนายน 2026 - 5 min readเรื่องของเรื่องคือ เมื่อไม่นานมานี้ Google เปิดตัว Gemini 3.5 Flash ที่เขาบอกว่า มันฉลาดพอ ๆ กับ Gemini 3.1 Pro แต่เร็วกว่า เราก็ลองมาใช้ดู ปรากฏว่าฉลาดและเร็วจริง ไม่จ้อจี้ แต่มันกิน Token จนติด Limit ใน 30 นาทีแค่นั้น เลยคิดว่า น่าจะซื้อ AI Computer มาเพื่อทำงานอยู่นะ เลยจัดมาเลย กับ DGX Spark...