จัดการข้อมูลบน Pandas ยังไงให้เร็ว 1000x ด้วย Vectorisation
By Arnon Puitrakul - 20 ตุลาคม 2023

เวลาเราทำงานกับข้อมูลอย่าง Pandas DataFrame บน Python หนึ่งในงานที่เราเขียนลงไปให้มันทำคือ การ Apply Function บางอย่างเข้าไป เช่น การทำ Standardise และ การ Clean ข้อมูลต่าง ๆ ถ้าข้อมูลมีขนาดเล็ก มันไม่มีปัญหาเท่าไหร่ แต่ถ้าข้อมูลของเราใหญ่ระดับล้าน ๆ มันอีกเรื่องเลย ดังนั้นทำให้เกิดคำถามว่า ถ้าเราจะเขียนให้เร็วที่สุด เราจะทำได้โดยวิธีใดบ้าง และมันเร็วกว่าเดิมได้ขนาดไหน วันนี้เรามาดูกัน
Experimental Setup
เพื่อให้เห็นภาพมากขึ้น เราจะมาทดลองแต่ละวิธี แบ่งเป็น 5 วิธีการดังนี้
- การใช้ iterrows() Loop จุก ๆๆ ใน Pandas
- การใช้ Slicing (iloc Function) ใน Pandas
- การใช้ apply() ใน Pandas
- การใช้ Vectorisation ใน Pandas
- การใช้ Vectorisation ใน Numpy
def generate_dataset (n:int) -> np.array :
return pd.DataFrame({'col1' : np.random.randint(0,255, n)})โดยแต่ละขั้นตอน เราจะสุ่มตัวเลขออกมา โดยมีค่าตั้งแต่ 0-255 ผ่าน Numpy และแยกออกมาทั้งหมด 5 การทดสอบย่อยด้วยกันประกอบด้วยข้อมูลจำนวน 1,000 , 10,000 , 100,000 , 1,000,000 , 10,000,000 และ 100,000,000 และใช้ทั้ง 5 วิธีที่ได้บอกไปรัน
ซึ่งระหว่างที่การทดสอบกำลังทำงาน เราจะวัดเวลาที่ใช้ในการรันด้วย แต่ไม่นับเวลาช่วงที่สุ่มข้อมูล และการคำนวณ Mean และ Std.Dev
def standardised_value(data : int, mean:float, std:float) -> float :
return (data - mean) / stdในการคำนวณที่เราจะทำ เราจะให้มันทำสิ่งที่เรียกว่า Standard Scaler หลักการง่าย ๆ คือ เราเอา Mean ไปลบ แล้วหารด้วย Std.Dev แค่นั้นเลย นั่นคือ เหตุที่ทำให้เราต้องมีการหา Mean และ Std.Dev ก่อน โดยเราไม่นับเวลาในส่วนนั้นนั่นเอง
การใช้ iterrows() Loop
การทดลองแรก เราขอใช้อะไรที่ตรงไปตรงมาในการทำงานที่สุด ถ้าเราบอกว่า เรามี DataFrame อยู่ และ เราต้องการที่จะคำนวณค่าใหม่ใส่เข้าไป เราเข้าถึง Column ที่ต้องการมันจะอยู่ในรูปแบบของ Series ทำให้สามารถใช้วิธีการเดียวกับตอนที่มันเป็น List ได้คือ การ Loop ไล่เข้าไปเรื่อย ๆ ซึ่งใน Pandas เขามีคำสั่งชื่อว่า iterrows() มาให้เรียบร้อย
def iterrow_test (dataset: pd.DataFrame, mean:float, std:float) -> float :
for index, row in dataset.iterrows() :
dataset['scaled'] = (row['col1'] - mean / std)การทำงานตรงไปตรงมาเป๊ะ ๆ คือ เราจะค่อย ๆ Loop ไปเรื่อย ๆ ทีละ Row ไปเรื่อย ๆ ผ่านคำสั่ง iterrows มันจะคืนค่ากลับมาให้เราทั้งหมดสองค่าด้วยกันคือ Index ที่อยู่ปัจจุบัน และ Row เป็นข้อมูลในแต่ละ Row เราสามารถเข้าถึงเป็น Column ได้เลย ทำให้เราเขียนแบบง่าย ๆ คือ ให้คำนวณ และ เอาไปเก็บไว้ใน Column ใหม่ไปเลยชื่อว่า "scaled"
วิธีการนี้ เป็นวิธีที่ช้ามาก ๆ เพราะ การทำงานคือ เครื่องจะค่อย ๆ Loop เข้าไปที่ทีละสมาชิกใน Row ที่เราสั่งให้คำนวณ ไม่แนะนำสำหรับการทำงานบนข้อมูลขนาดใหญ่ ๆ มันกินเวลาสูงมาก ๆ
การใช้ Slicing
ใน Pandas เขามี Concept ของการทำ Slicing หรือ การหั่นข้อมูล เช่น เราสามารถหั่นบาง Column ออก หรือ เลือกเฉพาะ Row ที่ผ่านเงื่อนไขบางอย่างได้ นึกภาพเหมือนกับเวลาเรา Query อะไรสักอย่างใน SQL ได้เลย แต่ ๆๆๆ การทำแบบนี้ ต้องบอกเลยว่า มันช้ามาก ๆ เพราะเมื่อเราสั่ง Slicing ตัว Pandas มันจะต้องเข้าไปหา และ แปลง Data Structure ไปมาจนได้ข้อมูลที่เราเห็น
def slicing_test (dataset: pd.DataFrame, mean:float, std:float) :
for n in range(len(dataset['col1'])) :
dataset.iloc[n, 0] = (dataset.iloc[n, 0] - mean) / stdการทำงานง่ายมาก ๆ เรารู้ว่า เราสามารถทำ Slicing ผ่านคำสั่งชื่อว่า iloc หรือ Index Location ได้ หมายความว่า Pandas อนุญาติให้เราดึงส่วนใดส่วนหนึ่งของ DataFrame โดยใช้เลข Index เป็นตัวกำกับ Location ได้ เช่น [1,0] คือ Row ที่ 1 และ Column 0 (อย่าลืมว่าเป็นเลข Index เริ่มนับที่ 0 เสมอ)
เราก็จัดเลย เรารู้ว่า เราต้องเข้าถึง Column ที่ 0 ตัวเดียว อันนี้ฟิคเลย ส่วน Row เราต้องเข้าตั้งแต่ 0 ถึงขนาดของมันลบ 1 (เพราะเป็น Index) ซึ่งขนาดของมัน เราสามารถใช้คำสั่ง len() ในการหาได้โดยตรง ทำให้ใน Loop เราเลย กำหนดเป็น For Loop ตั้งแต่ 0 ถึงจำนวน Row บน DataFrame ภายในนั้น เราสั่งให้คำนวณใหม่ตามสูตรของ Standard Scaler เท่านั้นเป๊ะ
ดังนั้น สิ่งที่เหมือนกับวิธีการก่อนหน้าคือ เรามีการ Loop เข้าไปทำ Operation หรือการคำนวณทีละตัว ๆ ความเร็วมันไม่น่าจะต่างกันเท่าไหร่ แต่.... สิ่งที่มันต่างกันคือ วิธีการเข้าถึงต่างหาก เพราะ การทำ Slicing มันเร็วกว่าการใช้ iterrows มาก ๆ สุดท้าย เลยทำให้ วิธีการนี้อาจจะทำให้เร็วขึ้น แต่ยังไม่ได้เร็วที่สุดแน่ ๆ
apply()
ถ้าไปอ่าน Document ของ Pandas เราจะเจอคำสั่งตัวนึงน่าสนใจคือ apply() เป็นสำสั่งที่ทำให้เราสามารถยัด Function ที่เราต้องการลงใน Element แต่ละตัวของ Pandas Series ได้ตรง ๆ ทำให้จัดการ หรือ แปลงข้อมูลที่ซับซ้อนได้ง่ายขึ้น
def apply_test (dataset: pd.DataFrame, mean:float, std:float) :
dataset['col1'].apply(standardised_value, args=(mean, std))การใช้งาน เราสามารถเรียกคำสั่ง apply() ด้านในใส่ Function ที่เราต้องการเข้าไป จากตัวอย่างด้านบน เรายัดคำสั่งสำหรับการทำ Standard Scale เข้าไป ซึ่งมันจะต้องมีอีกสอง Argument คือ Mean และ Std.Dev โดยเราสามารถยัดผ่าน args ดั่งตัวอย่างด้านบนได้เลย
อีกลักษณะที่ชอบเขียนกันคือ การใช้ Lambda Function หรือเรียกว่า Anonymous Function ทำให้เราไม่จำเป็นต้องประกาศ Function ให้ยุ่งยาก เราสามารถกำหนด Function ขนาดเล็ก ณ ตอนที่เราใช้งานได้เลย
แต่ ๆๆๆ การใช้งานลักษณะนี้ เมื่อมีการเรียก Function แปลว่า จะต้องมี Overhead และเราไม่ได้เรียกมันแค่ 1-2 ครั้ง เราเรียกกันเท่ากับจำนวนข้อมูลที่เราทำงาน เช่น 1 ล้านรอบ และในแต่ละรอบ เราเขียนคำสั่งผ่าน Python ทำให้มันต้องทำงานผ่าน Python Interpretator ซึ่งมี Overhead มหาศาล ทำให้วิธีการนี้ยังทำงานได้ช้าเมื่อเทียบกับอีก 2 วิธีที่เหลือ แต่ข้อดีคือ ให้ความสะดวก โดยเฉพาะเวลาทำ Analysis ง่าย ๆ เร็ว ๆ คร่าว ๆ วิธีการนี้จะทำให้เราทำงานได้เร็วมากกว่าแน่นอน
Pandas Vectorisation
จากวิธีก่อน ๆ เราสั่งไป เครื่องจะค่อย ๆ ไปสั่งคำนวณกับ Element ทีละตัวไปเรื่อย ๆ สิ่งที่ต้องทำ น่าจะเริ่มจาก การเข้าถึงข้อมูล การคำนวณ และ การ Update ค่าที่คำนวณกลับเข้าไป ทำให้อย่างน้อย Operation ที่ต้องทำจะมีขนาด 3N ยิ่ง Operation เยอะ ยิ่งมี Overhead ในการทำงานเยอะ เลยเกิดคำถามว่า เราสามารถทำให้การทำงานมีประสิทธิภาพมากกว่านี้ได้มั้ย
 Arnon Puitrakul
Arnon Puitrakul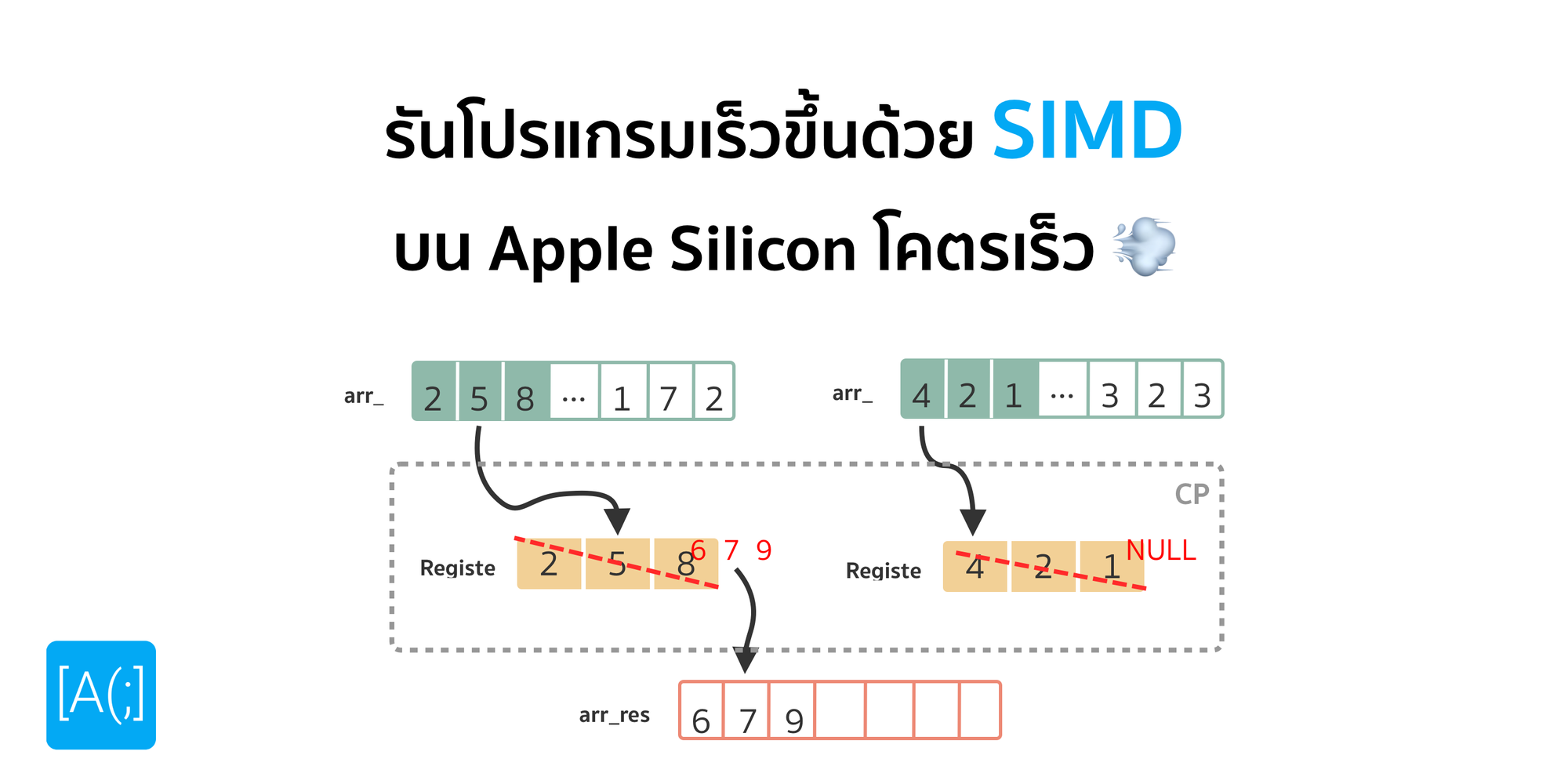
Vectorisation เข้ามาเล่นตรงนี้เลย แทนที่เราจะค่อย ๆ ทำทีละตัวแบบ Sequentially เราบอกว่า เราสามารถคำนวณทีละหลาย ๆ ค่าได้ใน 1 รอบการทำงาน อ่านแล้วอาจจะคล้ายกับการทำ Multithread แต่ไม่ใช่ เคสนี้เราไม่จำเป็นต้องใช้ CPU แบบ Multi-Core เลย เพราะใน CPU สมัยใหม่ เรามีสิ่งที่เรียกว่า Vector Instruction Set อยู่ เป็นชุดคำสั่งพิเศษที่ทำหน้าที่ในการทำ Vector Operation โดยเฉพาะ เช่นการบวกลบคูณหาร Matrix ต่าง ๆ
ถ้าเราดึงข้อมูลเช่น ทีละ 10 ตัวออกมา แล้วเอาไปผ่าน Vector Operation แทนที่เราจะต้องเสีย Overhead ดึงข้อมูล คำนวณ และเขียนข้อมูลกลับ 10 ครั้ง เราจะเหลือครั้งเดียว ทำให้การทำงานมีประสิทธิภาพสูงขึ้นอย่างมาก
def vectorisation_test (dataset: pd.DataFrame, mean:float, std:float) -> float :
dataset['col1'] = (dataset['col1'] - mean) / stdการใช้งาน Vectorisation ใน Pandas ง่ายมาก ๆ คือเราสามารถเอา Pandas Series ไปบวกลบคูณหารกับตัวเลขธรรมดาได้ มันจะเข้าไปใช้การทำงานแบบ Vectorisation เป็นค่าพื้นฐานอยู่แล้ว
ส่งผลให้ การเขียนในลักษณะนี้ สั้นกว่า และ อ่านได้ง่ายกว่า การเขียนโดยใช้ Loop หรือ Apply Function มาก ๆ เพราะ ตัวมันเองสามารถสื่อได้เลยว่า มันจะต้องทำอะไรโดยตรง เหมือนกับเวลาเราเขียนเพื่อทำงานกับจำนวนแค่จำนวนเดียว
Numpy Vectorisation
และวิธีสุดท้าย เรายังอยู่กับการทำ Vectorisation เหมือนเดิม แต่เราเลือกใช้ Library ที่เหมาะสมขึ้นอย่าง Numpy โดยเรารู้กันดีว่า ตัว Numpy Array มันเขียนมาเพื่อให้มีประสิทธิภาพในการเก็บ และ ประมวลผลข้อมูลที่สูงมาก ๆ ทำให้เป็นตัวเลือกที่น่าสนใจในการเอามาทดสอบครั้งนี้
def numpy_array (data: np.array, mean:float, std:float) :
data = (data - mean) / stdการเขียนง่ายมาก ๆ สั้นมาก ๆ เพียง บรรทัดเดียวจบได้เลย คือเราบอกไปเลยว่า ข้อมูล ที่เรารับเข้ามาเป็น Numpy Array เอาไปลบกับ mean และเอาไปหารกับ std ที่เป็น Float แค่นั้นเลย มันจะจัดการให้เราเอง เพราะเหมือน Pandas คือ มันใช้ Vectorisation เป็นค่าเริ่มต้น
Result

ผลการทดลองทำให้เราเห็นได้แบบเต็ม ๆ ว่า จากวิธีการที่เราเอามาทดลอง วิธีที่เร็วที่สุด ไปถึง ช้าที่สุดคือ Numpy Vectorisation, Pandas Vectorisation, apply(), Slicing และ สุดท้าย iterrows()
ตอนแรกที่ทำ เราคิดว่า Slicing น่าจะช้ากว่า iterrows() กลายเป็นว่าผลกลับกันเลย เราเดาว่า น่าจะเกิดจากวิธีการเข้าถึงข้อมูล เพราะ iterrows() มันเข้าถึงเป็น Row ไปเรื่อย ๆ แต่ โครงสร้างข้อมูลของ Pandas DataFrame เก็บเป็น Column แบ่งเป็น Pandas Series ไปเรื่อย ๆ ดังนั้น การใช้งาน iterrows() เบื้องหลังมันจึงซับซ้อนยุ่งยาก และใช้เวลามากกว่านั่นเอง
ส่วนวิธีการทำแบบ Vectorisation ทั้งสองคือ Numpy และ Pandas ดูเหมือน เราจะใช้หลักการเดียวกัน ทำให้เวลามันน่าจะใกล้เคียงกัน ซึ่งผลที่ออกมาก็จริง เพราะมันต่างกันประมาณ 1.5 เท่าได้เลย เราเดาว่า น่าจะเกิดจาก ลักษณะโครงสร้างข้อมูลของ Pandas Series และ Numpy Array ที่ตัว Numpy Array มันออกแบบมาเพื่อการเข้าถึงได้รวดเร็วกว่า กระชับกว่า จึงเกิด Overhead น้อยกว่า Pandas Series (ไว้เราจะมาเล่าละกันว่า ไส้ในเขาเก็บต่างกันยังไง ถ้าเล่าในนี้เดี๋ยวยาว..... แต่ถ้าอยากรู้เลยไปแคะ Source Code ได้) นั่นจึงเป็นเหตุที่การใช้ Numpy Array ให้ความเร็วที่สูงกว่า
แต่ ๆๆ ข้อสังเกตคือ ถ้าเกิดข้อมูลของเรามันอยู่ใน Format ของ Pandas DataFrame หรือ Pandas Series อยู่แล้ว การแปลงกลับไปเป็น Numpy Array และแปลงกลับมาหยอด Pandas ใหม่ เราค่อนข้างกังวลเรื่อง Overhead การแปลงไปกลับว่า มันจะทำให้โดยรวมช้ากว่าการใช้ Vectorisation บน Pandas โดยตรงหรือไม่ อาจจะต้องไปทดลองเพิ่มอีกหน่อยเพื่อทดสอบสมมุติฐานนี้
และสุดท้าย apply() ที่เร็วกว่าฝั่ง iterrows() และ Slicing ส่วนหนึ่งเป็นเพราะ มันทำงานแบบ ลูกครึ่ง คือ ตอนที่สั่ง Invoke Function หรือสั่งพวก Loop ทั้งหลาย มันไม่ได้ทำผ่าน Python แต่มันทำผ่านภาษา C ที่เป็นเบื้องหลังของทั้ง Pandas และ Numpy แต่สิ่งที่เราสั่งภายใน Function นั่น ยังต้องทำผ่าน Python ทำให้มันไปลด Overhead ของส่วนที่เป็น Loop ไป เลยทำให้เร็วกว่า 2 วิธีก่อนหน้าที่เราใช้ Loop แต่พอมาเทียบกับ Vectorisation นอกจากเทคนิคมันจะคำนวณได้ทีละหลาย ๆ ค่าแล้ว มันยังทำงานบน C เพียว ๆ ดังนั้น ความหน่วงของ Python Interpretator แทบจะหายไปเลย นั่นคือ เหตุว่าทำไมฝั่ง Vectorisation ถึงเร็วกว่าการใช้ apply()
สรุป
การจัดการข้อมูลบน DataFrame วิธีการอย่างการ Loop ไม่ว่าจะเป็นการใช้ iterrows() และ การทำ Slicing เป็นวิธีการที่เราไม่แนะนำให้ใช้เลย เนื่องจากช้า และ กินทรัพยากรที่สูงมาก ๆ แต่เบื้องต้น แนะนำให้ใช้ apply() บนงานที่มีความซับซ้อนสูง เนื่องจากเราสามารถใช้ Python ที่เป็นภาษาชั้นสูงเขียน Logic การทำงานได้โดยตรง แต่การงานแบบไหนที่เราเน้นคำนวณง่าย ๆ ไว ๆ การทำ Vectorisation ย่อมเป็นทางเลือกที่ดีกว่าแน่นอน เพราะเราต้องยอมรับว่า Python Interpretator เป็นส่วนที่ทำให้ Python มันง่าย แต่กลับกัน มันส่งผลกระทบกับเรื่อง Performance สูงมาก เมื่อเทียบกับการเรียก Machine Code ที่ผ่านการ Compile มาแล้วจากฝั่งของภาษา C แน่นอน ทำให้ในการทำงานกับข้อมูลขนาดใหญ่ ๆ เรามักจะใช้ Python เป็นเหมือนหน้ากากในการทำงาน ส่วนไส้ใน เรายัง Prefer ที่จะใช้พวก Compiler ในการทำงานมากกว่าอยู่ดี ด้วยเหตุที่กล่าวไปนั่นเอง
Related Posts

วิธีการและเทคนิคการ Capture เรื่องราวด้วย Obsidian
01 พฤษภาคม 2026 - 2 min readหนึ่งขั้นตอน Workflow ของ PKM ที่เป็นเหมือนการนำเข้าวัตถุดิบมาปรุงเป็นไอเดียดี ๆ ในอนาคต คือ การ Capture สิ่งที่เราได้เรียนรู้ หรือได้รับฟัง ดู อ่าน เข้ามา วันนี้เราจะมาเล่าวิธีการที่เราใช้กับ Obsidian กันว่า เราทำอย่างไร เพื่อให้ Workflow นี้ง่าย และเหมาะกับการใช้งานของเราที่สุด...

สร้าง WebAssembly Module แรกกันเถอะ
21 เมษายน 2026 - 2 min readจากบทความที่แล้ว ที่มาแนะนำ WebAssembly ไปว่า มันเป็นอะไรที่ค่อนข้างน่าสนใจ และน่าเรียนรู้เอาไว้มาก ๆ วันนี้เราจะมาพาทุกคนไปสร้าง WebAssembly Module แรกกัน และเทียบกันไปเลยว่า Performance ในงานที่ CPU Bound มาก ๆ มันจะห่างกันขนาดไหน...

Self-Hosted Service บน Home Lab จัดการอย่างไรให้ปลอดภัย
16 เมษายน 2026 - 3 min readช่วงหลัง ๆ กระแสการทำ Home Lab ฮิตขึ้นมาก ๆ ในประเทศไทยเรา มีคนถามเข้ามาเยอะมากว่า แล้วเราจะจัดการอย่างไรให้ระบบของเราปลอดภัยมากที่สุด วันนี้เราจะมารวบรวมวิธีคิดการวางสถาปัตยกรรมแบบ Defense-in-Depth สำหรับงาน Self-Hosting ง่าย ๆ กัน...

Functional Programming คืออะไร ? ทำไมมันถึงเป็นเรื่องที่น่าสนใจในยุคใหม่
11 เมษายน 2026 - 2 min readก่อนหน้านี้ไม่ค่อยได้สนใจการเอา Functional Programming มาใช้ในงานเท่าไหร่ แต่พอได้ลิ้มรสเท่านั้นแหละ มันเหมือนโลกใหม่มาก ๆ เข้ามาแก้ปัญหาหลาย ๆ อย่างที่เคยได้เจอมา วันนี้เราจะมาเล่ากันว่า มันคืออะไร และ มันน่าจะเหมาะกับงานไหนกัน...