รันโปรแกรมเร็วขึ้นด้วย SIMD บน Apple Silicon โคตรเร็ว
By Arnon Puitrakul - 17 ตุลาคม 2022
ถ้าเราอ่านข่าว CPU ตัวใหม่ ๆ ที่ออกมาเรื่อย ๆ เราจะเห็นว่า ทุก ๆ เจ้า เขาจะทำทุก ๆ อย่างเพื่อให้มันเร็วมากขึ้นเรื่อย ๆ อย่างการเพิ่มจำนวน Core หรือปรับ Clock Speed ขึ้นไปให้สูงขึ้น เช่นในตอนนี้ AMD และ Intel เอง ดันกันไประดับ 5.0 GHz กันแล้วที่เมื่อก่อนขึ้นไปถึงยากมาก ๆ แต่เราจะบอกว่า ในหลาย ๆ เคสมันไม่ได้ทำให้โปรแกรมทำงานได้เร็วขึ้นจริง ๆ หรอก แต่เราจะบอกว่า จริง ๆ แล้วมันมีอีกอย่างใน CPU ที่ทำให้การทำงานมันเร็วขึ้นได้นั่นคือ การใช้ SIMD
ปกติ เราบวกเลขกันยังไง ?

เราลองมาแก้ปัญหาที่ง่าย ๆ กันดีกว่า เราบอกว่า เรามี Array ทั้งหมด 2 ชุดที่ขนาดเท่ากัน โดยใน Array ทั้ง 2 ชุดนี้ เราต้องการหาผลบวกของตัวเลข เช่น ผลลัพธ์ตัวที่ 0 จะเกิดจาก สมาชิกตัวที่ 0 ของ Array ทั้ง 2 ชุดบวกกัน
import random
# Generate sample dataset
data_size = 10_000_000
arr_a = [random.randint(0,1_000) for _ in range(data_size)]
arr_b = [random.randint(0,1_000) for _ in range(data_size)]
arr_result = []
for i in range(data_size) :
arr_result.append(arr_a[i] + arr_b[i])ถ้าเราแก้ปัญหาง่าย ๆ เลย เราก็น่าจะเขียน For-Loop เข้ามาวนใน Array ทั้งสอง บวกกัน แล้วเอาผลลัพธ์ไปใส่ใน Array อีกชุดที่เป็นผลลัพธ์ อื้ม Simple as sh_t ! ดูจะไม่ยาก รันออกมา เราก็ได้ผลลัพธ์จริง ๆ
เกิดอะไรขึ้นใน CPU ?
เราลองมาดูให้ลึกขึ้นดีกว่า การคำนวณเลข จะเกิดขึ้นในส่วนหนึ่งของ CPU ที่เรียกว่า ALU (Arithmetic Logic Unit) หรือเป็นส่วนหนึ่งของ CPU ที่ทำหน้าที่ในการคำนวณตัวเลขและตรรกะทั้งหมดเลย ในนั้น มันก็จะมีวงจรสำหรับการทำงานพวกนี้อยู่เช่น การบวกลบเลขจำนวนเต็ม จนกระทั่งฝั่งของทศนิยมเช่นกัน

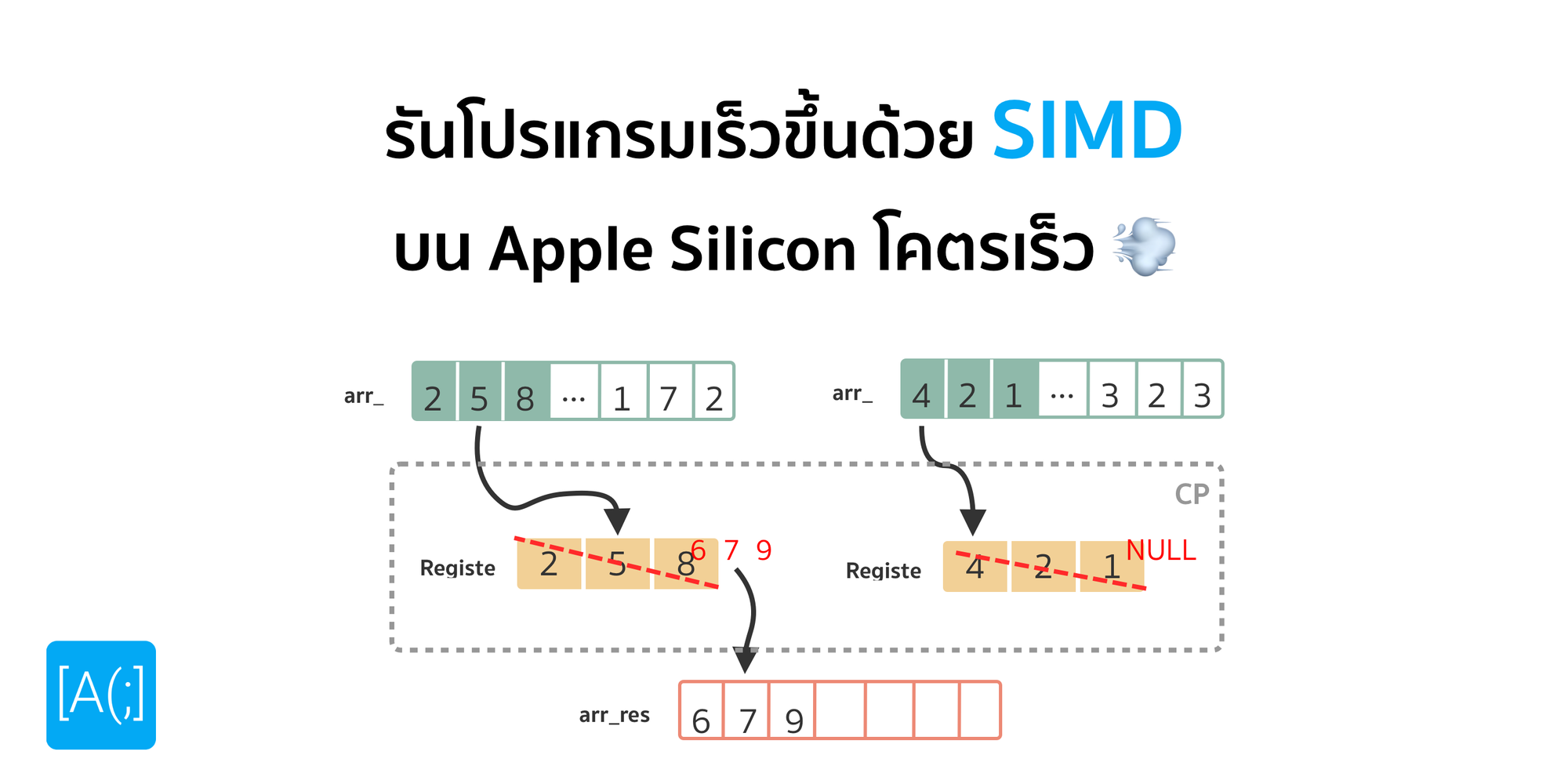
การที่เราจะบวกเลขได้ สมมุติว่า เราขอข้ามขั้นตอนของพวก Program Counter กับการ Parse Instruction อะไรออกไปแล้วนะ จะเริ่มบวกเลย เครื่องจะต้องโหลด ตัวเลขที่เราต้องการจะเอามาบวกกัน เช่น รอบแรก มันก็จะต้องโหลดตัวเลขตัวที่ 0 จาก Array ทั้ง 2 ตัวเข้ามาอยู่ใน Register (เป็น Memory ประเภทหนึ่งที่เร็วเ_ย) จากนั้นก็จะวงจรสำหรับการบวกเลขจะบวกเลขออกมาแล้วยัดใส่ Register ตัวนึงไว้ อาจจะเป็นตัวเดิมแหละ แล้วถึงจะเอาผลลัพธ์ที่ได้ เขียนกลับไปที่ Memory หรือก็คือ Array ที่เป็นผลลัพธ์ของเรา ที่เราสั่งมันไว้ก็เป็นอันจบขั้นตอน แล้วก็วนแบบนี้ไปเรื่อย ๆ จนกว่าจะทำครบทุกสมาชิกใน Array
ถึงตรงนี้เราจะสังเกตได้ว่า มันก็ดูเป็นการทำงานที่ตรงไปตรงมาดีเหมือนกัน ทำตามที่โปรแกรมเราเขียนไว้เป๊ะ ๆ เลยนินา แต่เราอยากให้ย้อนกลับไปดูที่ Application ก่อนหน้ากันคือ เราต้องการบวกเลขทั้งหมดใน Array เรารู้อยู่แล้วว่า เราจะต้องบวกให้หมดแน่ ๆ แต่ จากสิ่งที่เครื่องเห็นมันไม่ได้เป็นแบบนั้นน่ะสิ เครื่องเห็นแค่ว่า เราจะต้องบวกไปเรื่อย ๆ แบบ Serial ทำให้มันแอบเสียเวลารึเปล่า แล้วเราจะทำอย่างไรให้เราสามารถ Process ข้อมูลลักษณะนี้ได้รวดเร็วขึ้น
Single Instruction Multiple Data (SIMD)
จากปัญหาที่เราเล่าไป จะเห็นว่า เห้ย เราจำเป็นต้องบวกทีละตัวลงไปเรื่อย ๆ จริง ๆ อ่อ จริง ๆ แล้ว เราบวกอันไหนก่อนก็ได้ เราบวกพร้อม ๆ กันยังได้ อ่านแล้วอาจจะคิดว่า Mutithread Processing แต่ไม่ใช่วันนี้เราจะไม่ได้มาคุยวิธีนี้กัน
จริง ๆ เพราะปัญหาที่เรายกตัวอย่างมา หลาย ๆ ปัญหาทางการคำนวณ ก็มีอะไรที่ต้องทำแบบนี้เยอะมากขึ้นเรื่อย ๆ เช่นพวก Graphic เองที่เราเล่นเกมกัน ก็เจอปัญหาแบบนี้เหมือนกัน เลยทำให้ใน Processor ใหม่ ๆ เขาใส่วงจรที่สามารถรองรับการใช้ 1 คำสั่งในหลาย ๆ ข้อมูลพร้อม ๆ กันได้ หรือที่เราเรียกสถาปัตยกรรมพวกนี้ว่า Single Instruction Multiple Data (SIMD) นั่นเอง
import random
import pandas as pd
# Generate sample dataset
data_size = 10_000_000
arr_a = [random.randint(0,1_000) for _ in range(data_size)]
arr_b = [random.randint(0,1_000) for _ in range(data_size)]
df = pd.DataFrame({'a' : arr_a, 'b' : arr_b})
df['sum'] = df['a'] + df['b']ใน Python หลาย ๆ Library เองก็ Implement ใน C ดังนั้นบาง Function มันก็พ่วงพวก Vectorisation มาด้วยเช่นกัน สำหรับใน Pandas เอง ทำได้ง่ายมาก ๆ เราทำตรง ๆ เช่นโจทย์จากที่เราเล่าไปก่อนหน้า มันเขียนได้ง่ายกว่านั้นมาก เราก็แค่เอา Column บวกกันเท่านั้นเลย ที่เหลือมันจัดการให้เราหมด

ถามว่ามันเกิดอะไรขึ้นบ้าง แทนที่เราจะโหลดข้อมูลทีละตัวลงไปใน Register ตรง ๆ เลย เราก็โหลดได้เป็นชุด ๆ แล้วบวกพร้อม ๆ เลย เพราะใน CPU Core นึงเราอาจจะมีชุดคำสั่งสำหรับการบวกได้หลาย ๆ อันพร้อม ๆ กัน จากนั้นมันก็จะโหลดผลลัพธ์ทั้งหมดลงไปใน Register แล้วเขียนลงไปใน Memory เหมือนกับที่เราคุยกันก่อนหน้านี้ แค่เราบวกเป็นชุด ๆ เพราะเครื่องเห็นจากโปรแกรมเลยว่า เราจะ Batch เลย บวกทั้งหมด โดยใช้คำสั่ง และ ไม่เกี่ยวกัน ทำได้พร้อม ๆ กันเลย
Let's Benchmark
เรามาลอง Benchmark กันดีกว่า ว่าเกิดอะไรขึ้นกันแน่ เครื่องที่เราใช้เป็น Macbook Pro 14-inches M1 Max 32 GB Unified Memory เครื่องที่เราใช้งานในชีวิตประจำวันเลย
> time python sisd.py
python sisd.py 10.23s user 0.21s system 99% cpu 10.453 total
> time python simd.py
python simd.py 11.72s user 0.42s system 103% cpu 11.769 totalเริ่มจากทำอะไรง่าย ๆ ก่อนดีกว่า ใน Unix มันมีคำสั่ง time สำหรับวัดเวลาการทำงานของโปรแกรมได้ เราจะเห็นผลการทดลองที่ด้านบน โดยที่ simd ใช้เวลารันเยอะกว่า sisd ซะอีก ถึง 1 วินาที บนขนาดข้อมูล 10M เอ๊ะ มันแปลก ๆ นะ เพราะไหนเราบอกว่า การทำงานแบบนี้ฝั่ง SIMD น่าจะทำงานได้เร็วกว่าแท้ ๆ
ถ้าเราสังเกต Code ที่เราทดลองกัน เราจะเห็นว่า มันจะมีอยู่ 2 ส่วนใหญ่ ๆ ด้วยกันคือ ส่วนที่ใช้ในการสร้างข้อมูลขนาด 10M บน arr_a และ arr_b และส่วนที่เราทำการทดลองคือ ให้มันบวกกัน เราต้องการทราบแค่ส่วนหลังเท่านั้น ส่วนแรก เราไม่ต้องการ ดังนั้น เพื่อให้วัดผลได้ตรงจุดมากขึ้น เรามาทำ Time Block กั้นไว้ดีกว่า
import random
import time
import pandas as pd
# Generate sample dataset
data_size = 10_000_000
arr_a = [random.randint(0,1_000) for _ in range(data_size)]
arr_b = [random.randint(0,1_000) for _ in range(data_size)]
df = pd.DataFrame({'a' : arr_a, 'b' : arr_b})
start_time = time.time()
df['sum'] = df['a'] + df['b']
print(time.time() - start_time, 'sec')ตัวอย่างในไฟล์ของ SIMD เราก็จะเพิ่ม time เข้ามา และก่อนที่เราจะเริ่มบวก เราจะเก็บเวลาปัจจุบันที่รันถึงไว้ก่อนในตัวแปร start_time และเมื่อบวกเสร็จ เราก็จะเอาเวลาหลังบวกเสร็จ ลบ กับ เวลาใน start_time เราก็จะได้เวลาที่คั่นอยู่ระหว่างนั้น นั่นคือเวลาที่ใช้ในการบวก เราก็จะทำแบบนี้กับอีกไฟล์คือ SISD
> python sisd.py
1.0755951404571533 sec
> python simd.py
0.011874914169311523 secจากผลด้านบน เราจะเห็นว่าฝั่งของ SISD ใช้เวลาในการรันในระดับหลักวินาทีไปเลย เมื่อเทียบกับ SIMD เรารันในระดับไม่ถึงวินาที ห่างกันระดับเกือบ 100 เท่าเลย ถือว่าเร็วมาก ๆ จะเห็นได้เลยว่า แค่เราเปลี่ยนวิธีการเขียนโปรแกรม ก็ทำให้โปรแกรมเราเร็วขึ้นได้เยอะมาก ๆ ขนาดนี้เลย

หรือถ้าเราอยากให้เร็วขึ้นทั้งหมดเลย มันจะเหลือส่วนที่เป็นการ Random ตัวเลข ซึ่งแน่นอนว่า ก็มีคำสั่งสำหรับการทำอะไรแบบนี้เป็นแบบ SIMD โดยใช้ Numpy
Going deeper
ก่อนหน้านี้เราเห็นภาพแบบ High-Level ไปแล้ว ผ่านการเขียนใน Python เราไปให้ลึกขึ้นอีก ถ้าเราได้เรียนพวก Computer Architecture อาจจะเคยได้ยินคำว่า SSE (Streaming SIMD Extensions) หรือ AVX (Advanced Vector Extension) อะไรพวกนี้มาบ้าง พวกนี้มันเป็นชุดคำสั่งพิเศษ เพื่อให้ CPU สามารถทำ SIMD ได้
ADD R1, R2เพราะปกติ พวกชุดคำสั่งทั่ว ๆ ไปที่ใส่เข้ามาใน CPU มันก็จะเป็นคำสั่ง SISD ซะเยอะเช่น คำสั่งสำหรับการบวก เราก็จะบวกเลขได้แค่ เอาตัวเลข 2 ชุดมาบวกกัน แล้วยัดลงไปใน Register ได้แค่นั้น ทำให้ถ้าเราต้องการที่จะใช้ SIMD เราก็ต้องเพิ่มคำสั่งพิเศษเข้ามา
ถามว่า แล้วชุดคำสั่งทั่ว ๆ ไป มันก็ทำงานได้อยู่แล้ว งั้นเราก็ตีบวก Clock Speed เข้าไป นึกถึงเวลาเรา Overclock CPU ของเรา แน่นอนว่าทำให้การใช้พลังงานเยอะขึ้น ความร้อนสูงขึ้น และ ความเสถียรที่ลดลงแน่นอน ทำให้มันก็เป็นด้านหนึ่งแต่ก็ไม่ได้ยั่งยืนเท่าไหร่ในการประมวลผลข้อมูลขนาดใหญ่ ๆ
งั้นเอางี้ ถ้าการเพิ่ม Clock Speed ไม่ตอบโจทย์ละ ร้อนไม่ไหว เราก็เพิ่ม Core เข้าไปดิ เขียน Multi-Core Programming เข้าไปสิ ถ้าเราเรียนมา เราจะรู้ว่าจริง ๆ แล้ว มันก็ไม่ได้เป็น Linear Scale ขนาดนั้น เผลอ ๆ ทำให้ช้ากว่าเดิมได้เหมือนกัน นั่นแปลว่า ทั้งสอง Solution นี้อาจจะไม่ได้เป็นคำตอบของเราในวันนี้สักเท่าไหร่ ดังนั้น เพื่อเป็นการแก้ปัญหานี้ นักคอมพิวเตอร์เลยบอกว่า งั้นเอางี้ เราเพิ่มคำสั่งพิเศษแมร่งเข้าไปเลย ทำให้ใน 1 คำสั่งเราสามารถกดหลาย ๆ การคำนวณได้ซะเลย เลยทำให้มีพวก CPU ที่ทำ SIMD ได้นั่นเอง
ซึ่งแน่นอนว่า พวกคำสั่งพวกนี้ เราไม่ได้มีมาตรฐานอะไรอยู่แล้ว Brand ใครอยากใส่อะไร มันก็ใส่มา หน้าที่ของ Software Developer ก็ต้องเขียนออกมาเพื่อดึงความสามารถพวกนี้ออกมาให้ได้ ตัวอย่างที่เราพูดถึงอย่าง SSE และ AVX คือคำสั่งที่อยู่ใน Intel CPU
ดังนั้น จริง ๆ แล้ว การวัดความเร็วของ CPU มันไม่สามารถวัดได้จากแค่ Clock Speed เท่านั้นนะ เพราะมันต้องใช้หลาย ๆ ค่าในการทดสอบ เช่นจำนวน Core, IPC (Intruction Per Clock) บนกลุ่ม CPU สถาปัตยกรรมแบบ CISC, หรือการทำ SIMD มันเลยขึ้นกับการวัดมากกว่า ว่าเราต้องการวัดอะไร
How Special is Apple Silicon ?
ทีนี้ ถ้าเราจำกันได้ เราเคยเล่าเรื่องของพวก x86 กับ ARM ไปแล้ว โดยที่ Apple Silicon ทั้งหลายรันอยู่บนสถาปัตยกรรมแบบ ARM และ อย่างที่บอกว่า แต่ละ Brand ก็จะมีการออกแบบชุดคำสั่งบน CPU ของตัวเองที่แตกต่างกัน
สำหรับบน Apple Silicon เองที่ทำงานอยู่บนสถาปัตยกรรม ARM 64-Bits เขาก็จะมีชุดคำสั่งสำหรับการทำงานแบบ SIMD เหมือนกัน ที่มีชื่อว่า NEON ความเจ๋งที่ทำให้เรา ร้องว่า Holys_it ! กับ Apple Silicon คือ ขนาดของ Register ที่ทำให้เราสามารถเก็บข้อมูลได้มากขึ้น เช่นจากเดิมบาง CPU อาจจะรองรับที่ 64-Bits ก็โดดมาเป็น 128-Bits ไปเลย นั่นหมายความว่า เวลาเราทำ Vectorisation มันจะทำได้ในจำนวนต่อครั้งที่มากขึ้น ถ้าเรามองกลับกัน แปลว่า เราจะใช้ Clock Speed ที่ต่ำกว่า และ จำนวน Core ที่น้อยกว่า เพื่อจะคำนวณเลขได้เร็วกว่า CPU ตัวอื่น ๆ ได้ และ ถ้าเราเขียนโปรแกรมมาเพื่อรองรับด้วยนะ
โดยเฉพาะงานที่เราใช้เยอะ ๆ มาก ๆ อย่างการทำ Deep Learning นั่นอาศัยการทำ Vectorisation มหาศาลมาก ๆ ทำให้พวก GPU ได้เปรียบในงานแบบนี้ แต่นั่นก็แลกมากับการใช้พลังงานมหาศาลมาก ๆ ถ้าพวก High Performance GPU จริง ๆ เลย อาจจะกดทั้งระบบไป 1,000W เข้าให้ ทำให้ ไม่เหมาะกับการเอามาทำ Model ขนาดเล็ก ๆ หรือการทำพวก Edge Computing เท่าไหร่ เลยทำให้เราค่อนข้างสนุกมาก ๆ กับการเอา Apple Silicon มาทำงาน Deep Learning เพราะ Performance ได้ และ การกินพลังงานที่ต่ำมากตามสไตล์ของ ARM-Based Computer
โดยที่ใน Apple Silicon เองที่เป็น ARM ถ้าเราเอาโปรแกรมที่เป็น x86 มารัน จะต้องทำงานผ่าน Compatibility Layer อย่าง Rosetta น่าเสียดายที่มันยังไม่รองรับการแปลงพวกคำสั่งอย่าง SSE และ AVX ที่อยู่ใน Intel Mac ก่อนหน้าให้เป็น NEON ได้ ทำให้ Performance พวกนี้อาจจะยังสู้การทำงานบน Intel Mac ไม่ได้ ดังนั้น บางโปรแกรมที่เราเห็นว่า เขา Compile มาเพื่อทำงานบน Apple Silicon โดยเฉพาะ ส่วนนึง มันเร็วขึ้นก็เพราะการรองรับคำสั่งพวกนี้แหละ กับอีกส่วนคือ การไม่ต้องรันโดยมี Rosetta มาคล่อม
สรุป
SIMD (Single Instruction Multiple Data) เป็นวิธีการประมวลผลข้อมูลแบบขนาน (Parallel Processing) โดยที่เราเอาคำสั่งเดียวแต่ไปทำงานกับชุดข้อมูล ทำให้เราสามารถประมวลผลข้อมูลได้มากขึ้น มี Throughput ที่สูงขึ้น โดยการออกแบบ Instruction Set ที่ทำงานในเรื่องนี้โดยเฉพาะขึ้นมา ซึ่งใน CPU ใหม่ ๆ ก็มีการรองรับ Feature นี้กันเยอะมาก ๆ อย่างใน Apple Silicon เองก็รองรับเช่นกัน นอกจากนั้นยังมีขนาดของ Register ที่ใหญ่กว่าชาวบ้านมาก ๆ ทำให้ทำงานในลักษณะนี้ได้เร็วมาก ๆ ถามว่าการทำงานในลักษณะนี้ เร็วกว่าการทำงานแบบ Sequential ขนาดไหน ลองกลับขึ้นไปดู Benchmark ได้ ห่างกันเกือบ 100 เท่าตัวเลยในการบวกเลขจำนวน 10 ล้านตัว แนะนำว่า ถ้าเขียนโปรแกรมที่ทำงานกับข้อมูลขนาดนี้ ให้พยายามเขียนในลักษณะนี้ก็จะช่วยเรื่อง Performance ได้เยอะมาก ๆ
Related Posts

วิธีการและเทคนิคการ Capture เรื่องราวด้วย Obsidian
01 พฤษภาคม 2026 - 2 min readหนึ่งขั้นตอน Workflow ของ PKM ที่เป็นเหมือนการนำเข้าวัตถุดิบมาปรุงเป็นไอเดียดี ๆ ในอนาคต คือ การ Capture สิ่งที่เราได้เรียนรู้ หรือได้รับฟัง ดู อ่าน เข้ามา วันนี้เราจะมาเล่าวิธีการที่เราใช้กับ Obsidian กันว่า เราทำอย่างไร เพื่อให้ Workflow นี้ง่าย และเหมาะกับการใช้งานของเราที่สุด...

สร้าง WebAssembly Module แรกกันเถอะ
21 เมษายน 2026 - 2 min readจากบทความที่แล้ว ที่มาแนะนำ WebAssembly ไปว่า มันเป็นอะไรที่ค่อนข้างน่าสนใจ และน่าเรียนรู้เอาไว้มาก ๆ วันนี้เราจะมาพาทุกคนไปสร้าง WebAssembly Module แรกกัน และเทียบกันไปเลยว่า Performance ในงานที่ CPU Bound มาก ๆ มันจะห่างกันขนาดไหน...

Self-Hosted Service บน Home Lab จัดการอย่างไรให้ปลอดภัย
16 เมษายน 2026 - 3 min readช่วงหลัง ๆ กระแสการทำ Home Lab ฮิตขึ้นมาก ๆ ในประเทศไทยเรา มีคนถามเข้ามาเยอะมากว่า แล้วเราจะจัดการอย่างไรให้ระบบของเราปลอดภัยมากที่สุด วันนี้เราจะมารวบรวมวิธีคิดการวางสถาปัตยกรรมแบบ Defense-in-Depth สำหรับงาน Self-Hosting ง่าย ๆ กัน...

Functional Programming คืออะไร ? ทำไมมันถึงเป็นเรื่องที่น่าสนใจในยุคใหม่
11 เมษายน 2026 - 2 min readก่อนหน้านี้ไม่ค่อยได้สนใจการเอา Functional Programming มาใช้ในงานเท่าไหร่ แต่พอได้ลิ้มรสเท่านั้นแหละ มันเหมือนโลกใหม่มาก ๆ เข้ามาแก้ปัญหาหลาย ๆ อย่างที่เคยได้เจอมา วันนี้เราจะมาเล่ากันว่า มันคืออะไร และ มันน่าจะเหมาะกับงานไหนกัน...