โหลด CSV วิธีไหนเร็วที่สุด ?
By Arnon Puitrakul - 08 กรกฎาคม 2024

เมื่อหลายวันก่อนมีพี่ที่รู้จักกันมาถามว่า เราจะโหลด CSV ยังไงให้เร็วที่สุด เป็นคำถามที่ดูเหมือนง่ายนะ แต่พอมานั่งคิด ๆ ต่อ เห้ย มันมีอะไรสนุก ๆ ในนั้นเยอะเลยนี่หว่า วันนี้เราจะมาเล่าให้อ่านกันว่า มันมีวิธีการอย่างไรบ้าง และวิธีไหนเร็วที่สุด เหมาะกับงานแบบไหน
Setting up the Experiment
ถ้าเราจะวัดเวลาในการโหลด CSV File เราจำเป็นต้องมีตัวอย่างข้อมูลกันก่อน เราขอ Generate File ง่าย ๆ ขึ้นมา ประกอบด้วย 3 Columns ชื่อ A,B และ C ตามลำดับ โดยในแต่ละ Column เราจะให้ข้อมูลเกิดจากการ Random ตัวเลข ระหว่าง 0-1,000 ขึ้นมา โดยให้มีทั้งหมด 100 ล้าน Row เพื่อจำลองในกรณีที่เรามีจำนวน Row เยอะ ๆ
import numpy as np
import pandas as pd
n_sample = 100_000_000
df = pd.DataFrame({'A': np.random.randint(0,1_000,n_sample) , 'B' :np.random.randint(0,1_000,n_sample) , 'C' : np.random.randint(0,1_000,n_sample)})
df.to_csv('data.csv', index=False)วิธีการทำใน Python ที่ง่าย และเร็วคือ การใช้ Numpy และ Pandas มันซะเลย เราเริ่มจากการสร้าง DataFrame จาก Dictionary โดยในนั้นเราให้มี 3 Key เป็นแต่ละ Column ที่เรากำหนด ส่วนข้อมูลคือตัวเลข เราเลือกใช้ Numpy เข้ามาช่วย ไส้มันเขียนด้วย C ทำให้ทำงานได้ค่อนข้างเร็วกว่ามาก ๆ
สุดท้ายจาก Pandas DataFrame เราเรียกคำสั่ง to_csv เพื่อเซฟเก็บเป็น CSV File ที่ไม่เอา Index ไว้ด้วยนะ เปลืองจะเอามาทำไม
import time
start_time = time.time()
// Do Experiment
elapsed = time.time() - start_timeตัวแปรตามคือเวลาที่ใช้ในการทำงาน เราจะใช้ Module เวลาใน Python เก็บเวลา ณ ก่อนเริ่มการทดลอง และ เมื่อทำการทดลองเสร็จ เราเอาเวลาปัจจุบัน ณ ตอนที่ทำเสร็จ ลบกับเวลาที่เราเก็บไว้ ณ ก่อนเริ่มการทดลอง เราก็จะได้เวลาที่ใช้ในหน่วยวินาทีออกมานั่นเอง เราจะทำแบบนี้กับทุก ๆ การทดลอง ในบทความนี้ เราจะแบ่งการทดลองออกมาทั้งหมด 7 ตัวด้วยกัน แบ่งเป็น
- Simple Method หรือการอ่านไฟล์ทีละบรรทัด และ Split ออกตามปกติ
- Pandas read_csv(method='c')
- Pandas read_csv(method='pyarrow')
- Pandas read_csv(method='python')
- Pandas read_csv แบบ Chunk
- Dask read_csv
- Polars read_csv
Experiment #1 : อ่านไฟล์ทั่ว ๆ ไปง่าย ๆ
def simple_reader (file_path:str) :
data_file = open(file_path, 'r')
while (line := data_file.readline()) :
line.split(',')
data_file.close()วิธีแรกขอเป็นวิธีตรง ๆ ง่าย ๆ เพื่อสร้าง Baseline เอามาเทียบกัน โดยเราเริ่มจากเปิดไฟล์ และค่อย ๆ อ่านมาทีละบรรทัด จากนั้น เราทำการ Split หรือแยก String ด้วย Comma วนแบบนี้ไปเรื่อย ๆ จนจบ แล้วอย่าลืมปิดไฟล์
โดยการทำงานแบบนี้เราคาดหวังว่า มันน่าจะทำงานได้ช้ามาก ๆ เพราะทุกคนก็เข้าใจเนอะว่า Python Interpreter มันต้อง Interpret ทุกครั้ง ทำให้มี Overhead มาก ดังนั้นเมื่อเราเจอการวน ๆ แบบนี้ยิ่งเป็นการตอกย้ำปัญหานี้เข้าไปใหญ่ จึงทำให้เราคาดหวังว่ามันน่าจะช้าแน่นอน
Experiment #2-4: Pandas read_csv
pd.read_csv(data_file_path, engine='c')
pd.read_csv(data_file_path, engine='pyarrow')
pd.read_csv(data_file_path, engine='python')Library ที่เป็นที่ยอดนิยมใช้ในการจัดการข้อมูลกันใน Python คือ Pandas โดยเขา Built-in คำสั่งสำหรับการอ่าน CSV File มาให้เราแล้ว ซึ่งมันมีตัวเลือกสำหรับ Engine ที่ใช้มาให้เราทั้งหมด 3 ตัวด้วยกันคือ C, PyArrow และ Python
C Engine คือ ตัวเลือก Default เมื่อเราเรียกคำสั่ง read_csv โดยมันจะไปเรียกคำสั่งสำหรับการอ่าน CSV ที่เขียนในภาษา C ทำให้การทำงานค่อนข้างไวกว่ามาก ๆ แต่ตัวเลือก Option ในการทำงานบางอย่าง อาจจะใช้งานไม่ได้เท่ากับ Python Engine แต่ถ้าหากอ่าน CSV File ทั่ว ๆ ไป การใช้ C Engine ดูจะเป็นตัวเลือกที่ง่ายสำหรับคนส่วนใหญ่ และเร็วที่สุดแล้ว จึงถูกใช้เป็น Default Engine นั่นเอง
Python Engine คือ การใช้ Python Script ปกติเลย หมายความว่า คำสั่งที่ทำงานทั้งหมดต้องทำงานผ่าน Python Interpreter ทั้งหมด ทำให้ Performance ค่อนข้างช้ามาก ๆ แน่นอน แต่แลกมากับความสามารถในการใช้งานตัวเลือกบางอย่างเพิ่มเติมเข้าไปได้ สำหรับ CSV File ที่น่าตาแปลก ๆ หรือมีเงื่อนไขในการดึงบางอย่าง
PyArrow Engine คือ การเรียกคำสั่ง read_csv() จาก Apache Arrow นั่นเอง ซึ่งเจ้าตัว Arrow เขาขึ้นชื่อเรื่องความเร็วในการทำงานกับข้อมูลขนาดใหญ่ ๆ อยู่แล้ว ตั้งแต่การดึงข้อมูล จนไปถึงการทำ In-Memory Analytics ทั้งหลาย ทำให้น่าจะเป็นตัวที่รวดเร็วที่สุดในทั้ง 3 Engines นี้แล้วแหละ แต่แลกมากับตัวเลือกบางอย่างที่ใช้งานไม่ได้ ต้องใช้ตามที่ Arrow มีมาให้แค่นั้น แต่ไม่มีปัญหาอะไร ถ้าอ่าน CSV File ทั่ว ๆ ไป
Experiment #5: Pandas Chunk Read
def pandas_chunk_reader (file_path:str) :
chunks = pd.read_csv(file_path, chunksize=1_000_000)
for idx,chunk in enumerate(chunks) :
chunkหากข้อมูลของเรามีขนาดใหญ่มากจริง ๆ ใหญ่จนบางที เราไม่สามารถ Fit ลงไปใน Memory ของเราได้ วิธีการแก้ปัญหาที่ง่ายที่สุดคือ การทำ Batch Processing เอา กล่าวคือ ให้เราอ่านข้อมูลเข้ามาแตกออกเป็น Chunk หรือชิ้นที่เล็กลง เช่น 1 ล้าน Record แล้วเอา 1 ล้านตรงนั้นมาทำงาน แล้วค่อยไปอ่านอีก 1 ล้านต่อไป ทำแบบนี้ไปเรื่อย ๆ จนจบ นั่นแปลว่า Memory ที่เราต้องใช้คือ Memory สำหรับ 1 ล้าน Records เท่านั้น ไม่ใช่จำนวน Row ทั้งหมดที่มี
สำหรับวิธีการที่เราใช้เขียนนั้น ในคำสั่ง read_csv() ของ Pandas เขาจะมีตัวเลือกสำหรับกำหนดว่า เราจะให้มันอ่านทีละกี่ Row ผ่านตัวเลือกที่ชื่อว่า chunksize เช่นในตัวอย่างด้านบน เราอ่านมาทีละ 1 ล้าน แต่สิ่งที่มัน Return กลับมา ไม่ใช่ Array ของ DataFrame ที่ในนั้นมีข้อมูลอยู่ 1 ล้าน Record แต่เป็นเหมือน FileReader หรือก็คือ หัวอ่านที่ถูกเซ็ต Cursor ไปตามจุดต่าง ๆ ไว้แล้ว ดังนั้น ถ้าเราต้องการจะอ่านจริง ๆ จำเป็นต้องไล่ไปตาม Reader เพื่อให้มันไปอ่านไฟล์จริง ๆ ออกมา ทำให้เราเขียน For Loop ไปเพื่อเรียกให้มันอ่านไฟล์นั่นเอง
 Arnon Puitrakul
Arnon Puitrakul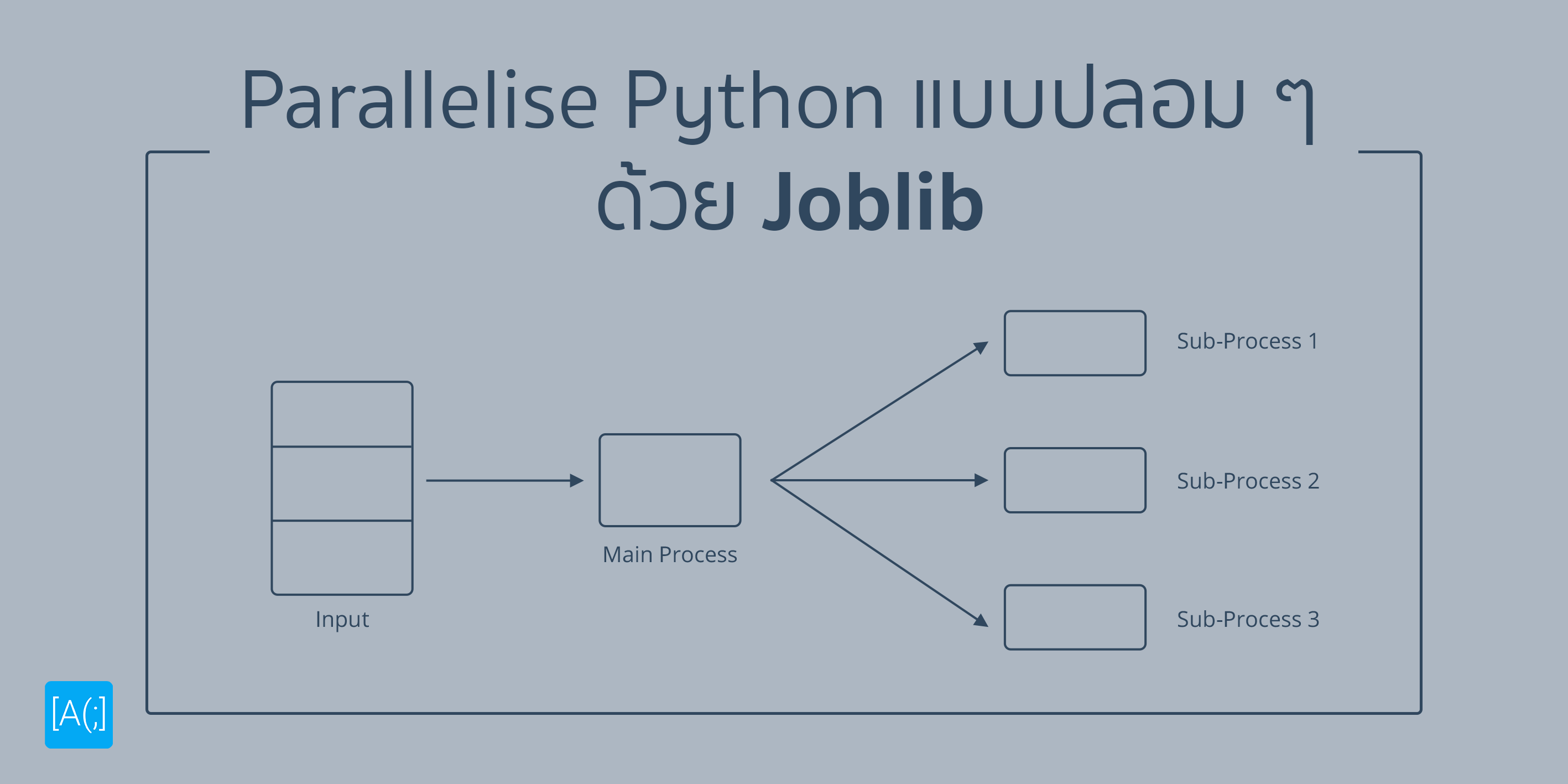
เราเคยทำให้มันพีคกว่านั้นอีกคือ เราใช้ Joblib ช่วย คือ จากเดิมที่เรา For Loop ทำทีละ Chunk ถ้าเครื่องที่เรารันมี Memory มากพอ เราก็กระจาย Chunk ไปตาม Core ต่าง ๆ เลยสิ เรียก Parallel ของ Joblib แตก Process ออกไปซะเลย มันก็จะเร็วขึ้นจริง แต่มันกิน Memory หนักอยู่นะ
Experiment #6: Dask read_csv()
Dask เป็น Python Library ตัวนึงที่ออกแบบมาเพื่องานจำพวก Parallel และ Distributed มี Feature สำหรับการช่วยเหลือเราในเรื่องพวกนี้เยอะมาก ๆ แต่ในการทดลองนี้เราไม่ได้พาไปขนาดทำระดับ Setup Cluster ขึ้นมาช่วยกันทำงานเด้อ มันจะเอาเปรียบการทดลองอื่น ๆ มากไป เราแค่ใช้คำสั่งในการ อ่าน CSV ของ Dask เท่านั้น
import dask.dataframe as dd
ddf = dd.read_csv(data_file_path)
ddf.compute()ความสนุกของ Dask ที่เราชอบคือ เวลาเรารันคำสั่ง มันจะยังไม่ทำงานตามที่เราบอกทันที เราจะต้องเรียก compute() มันถึงจะเริ่มทำงาน ดังนั้น เราสามารถสั่งรัว ๆ ไว้ได้เลย เช่น เราให้มันอ่านเข้ามา และ Transform บางอย่างให้เรียบร้อย แล้วเราค่อยสั่ง Compute มันถึงจะเริ่มทำงานตามที่เราสั่ง ดังนั้น ในการทดลองนี้ เราไม่สามารถเรียกแค่ read_csv ได้ เพราะมันจะไม่ทำอะไรเลย นอกจากจำไว้ว่า มันจะต้องเรียกแค่นั้น เราเลยสั่ง compute() เข้าไป
Experiment #7: Polars read_csv()
Polars เป็น Library สำหรับการจัดการข้อมูลคล้ายกับ Pandas แต่เกิดมาในยุคใหม่กว่า แซ่บกว่า เริ่ดกว่าหลายขุม เพราะโดยค่าพื้นฐาน Polars จะใช้ระบบการ Parallel Processing, SIMD และ Algorithm ใหม่ ๆ ที่มีประสิทธิภาพสูง และความพีคของมันอีกอย่างคือ หากเราใช้ Pandas อยู่แล้ว เราแทบไม่ต้องเปลี่ยน Code อะไรมากเลย ชุดคำสั่ง ชื่อ Function ที่ใช้เหมือนกับ Pandas เกือบทั้งหมด แค่เปลี่ยน Library ชีวิตเปลี่ยนได้ทันที เขาเคลมว่า Performance Improved 30 เท่าตัวเมื่อเทียบกับ Pandas เลยนะ นี่สินะที่เขาชอบพูดกันว่า เด็กมันแซ่บ
import polars as pl
pl.read_csv(data_file_path)อย่างที่บอกว่า คำสั่งเหมือนกับ Pandas เป๊ะ ๆ เราแทบไม่ต้องทำอะไรเลย แค่เปลี่ยนจาก pd ข้างหน้าเป็น pl แค่นั้นเลย หรือ ถ้าไม่อยากแก้มาก ก็แค่เปลี่ยน pl เป็น pd เอาจริง ยังไม่รู้เรื่องเลยด้วยซ้ำว่าเปลี่ยน คำสั่งมันใช้กันได้หมด
Results

จากผลการทดลอง เราจะเห็นได้ว่า เวลาที่ใช้ในแต่ละวิธีการนั้นค่อนข้างแตกต่างกันมาก ๆ โดยเฉพาะ วิธีที่เราใช้ Python Engine บน Pandas ทะลุวิธีที่เหลือไปไกลมาก ๆ ใช้เวลาไป 501.50 วินาที เมื่อเทียบกับวิธีที่เหลือที่ช้าที่สุดคือ การอ่านไฟล์ปกติที่ใช้อยู่ 15.83 วินาทีด้วยกัน
วิธีการที่เร็วที่สุด เป็นไปตามคาดคือ Polars ที่ใช้ 0.55 วินาที หรือไม่ถึงวินาทีเท่านั้นเอง เมื่อเทียบกับวิธีการพื้นฐานที่สุดอย่าง C Engine บน Pandas ที่ใช้ 6.47 วินาที ดังนั้น ถ้าเราเปลี่ยนมาใช้ Polars มันจะทำให้เราโหลด CSV ได้เร็วกว่าประมาณ 10-11 เท่าตัวเลยทีเดียว ถือว่าเยอะมาก ๆ เลยทีเดียว
ถ้าเทียบแต่ละ Engine บน Pandas กันเอง Python Engine ช้าที่สุด รองลงมาคือ C Engine และ PyArrow Engine เป็นตัวที่เร็วที่สุด โดย C Engine และ PyArrow Engine ใช้เวลา 6.47 และ 1.06 วินาทีตามลำดับ หรือต่างกันประมาณ 6 เท่าตัวเลยทีเดียว
นอกจากนั้น Chunk Read สามารถทำความเร็วได้ใกล้ ๆ กับ C Engine แต่มากกว่าหน่อยนึง ซึ่งไม่ใช่เรื่องแปลกเท่าไหร่ เนื่องจากตอนที่เราเขียน Chunk Read เราไม่ได้กำหนด Engine ลงไปด้วย ทำให้มันใช้ค่า Default นั่นคือเรียก C Engine แต่ที่มันช้ากว่า เพราะเราจะต้อง Loop ให้มันไปอ่านแต่ละ Chunk อีกที แต่ต้องอย่าลืมว่า หากเรามีจำนวนข้อมูลที่ต้องโหลดใหญ่เกินขนาดของ Primary Memory วิธีการนี้ดูจะเป็นวิธีการที่ง่ายที่สุดในการจัดการแล้ว
เราคิดว่า หลาย ๆ คนอาจจะสงสัยว่า ทำไม วิธีการอ่านไฟล์ และ Split เอง ถึงเร็วกว่าการใช้ Python Engine บน Pandas มหาศาล เราเดาว่า น่าจะเป็นเพราะ Pandas มันไม่ใช่แค่ Parse File เท่านั้น แต่มันต้องสร้าง DataFrame แล้วเก็บข้อมูลบน DataFrame อีกทำให้มันกินเวลามาก ประกอบกับ ณ ตอนที่รัน Python มันกิน Memory ไปเยอะมาก ๆ จน Paging เริ่มทำงาน นั่นอาจจะเป็นเหตุใหญ่ ๆ เลยละที่ทำให้มันช้ากว่าวิธีอื่นมาก ๆ
Discussion
เราคิดว่า หากใครต้องการ Performance จริง ๆ Polars ดูจะเป็นตัวเลือกที่น่าสนใจมาก ๆ เหมาะสำหรับทั้งมือใหม่ที่พึ่งเรียนรู้ และรุ่นใหญ่ที่ใช้ Pandas มาก่อน เพราะ API เหมือนกันแบบเป๊ะ ๆ แค่เปลี่ยน Library ที่เรียกเท่านั้นเอง ถามว่า Pandas สามารถทำพวก Parallel และ SIMD ได้มั้ย คำตอบคือ ได้ แต่มันไม่ได้ง่าย และใช้เป็นค่าเริ่มต้นเหมือนกับ Polars ทำให้ถ้าเราใช้ Polars เราก็ตัดเรื่องการจัดการ Performance ออกไปได้พอสมควร เขาทำให้เราส่วนใหญ่แล้ว เว้นแต่มันจะเป็นเคสแปลก ๆ จริง ๆ
หรือถ้าเราทำงานแบบ Parallel ทำเป็น Cluster เราคิดว่า Dask เป็นตัวเลือกที่ไม่เลวเลย มีคำสั่งสำหรับการทำงานแบบ Parallel ที่ดีมาก ๆ นอกจากนั้น Dask DataFrame ยังมีข้อดีในการ Abstract DataFrame ขนาดใหญ่ ๆ ได้ เหมือนกับเราร่างแบบไว้ว่า มันจะหน้าตาประมาณนี้ เราแค่บอกมันว่า เราจะทำอะไร แล้วค่อยสั่งให้มัน Execute ทีเดียว
และสำหรับคนที่ใช้งาน Pandas อยู่แล้ว และต้องการเร่งความเร็วในการอ่าน CSV ผ่าน Pandas โดยการเปลี่ยนแปลง Source Code ให้น้อยที่สุด การเปลี่ยน Engine เป็น PyArrow ดูจะเป็นตัวเลือกที่ดีอันนึงเลย เพราะสุดท้ายแล้ว คำสั่ง read_csv ไม่ว่าเราจะใช้ Engine ไหนมันก็ยัง Return Pandas DataFrame กลับมาเหมือนเดิม ไม่มีปัญหากับคำสั่งที่ใช้อยู่เดิมแน่นอน
แต่วิธีการที่เราไม่แนะนำคือ การนั่งเขียนเอง เพราะเอาเข้าจริง มันมี Library ตัวเลือกมาให้เยอะขนาดนี้แล้ว เราจะเขียนเองเพื่ออะไร ที่เราใส่มาให้ในการทดลองครั้งนี้ เพื่อเป็น Baseline ในการเปรียบเทียบเท่านั้นว่า หากเราเขียนเองมันจะเร็วกว่า หรือช้ากว่า พวก Library ที่ใช้ท่าอ่านเขียนแบบยาก ๆ ขนาดไหนกัน
Related Posts

วิธีการและเทคนิคการ Capture เรื่องราวด้วย Obsidian
01 พฤษภาคม 2026 - 2 min readหนึ่งขั้นตอน Workflow ของ PKM ที่เป็นเหมือนการนำเข้าวัตถุดิบมาปรุงเป็นไอเดียดี ๆ ในอนาคต คือ การ Capture สิ่งที่เราได้เรียนรู้ หรือได้รับฟัง ดู อ่าน เข้ามา วันนี้เราจะมาเล่าวิธีการที่เราใช้กับ Obsidian กันว่า เราทำอย่างไร เพื่อให้ Workflow นี้ง่าย และเหมาะกับการใช้งานของเราที่สุด...

สร้าง WebAssembly Module แรกกันเถอะ
21 เมษายน 2026 - 2 min readจากบทความที่แล้ว ที่มาแนะนำ WebAssembly ไปว่า มันเป็นอะไรที่ค่อนข้างน่าสนใจ และน่าเรียนรู้เอาไว้มาก ๆ วันนี้เราจะมาพาทุกคนไปสร้าง WebAssembly Module แรกกัน และเทียบกันไปเลยว่า Performance ในงานที่ CPU Bound มาก ๆ มันจะห่างกันขนาดไหน...

Self-Hosted Service บน Home Lab จัดการอย่างไรให้ปลอดภัย
16 เมษายน 2026 - 3 min readช่วงหลัง ๆ กระแสการทำ Home Lab ฮิตขึ้นมาก ๆ ในประเทศไทยเรา มีคนถามเข้ามาเยอะมากว่า แล้วเราจะจัดการอย่างไรให้ระบบของเราปลอดภัยมากที่สุด วันนี้เราจะมารวบรวมวิธีคิดการวางสถาปัตยกรรมแบบ Defense-in-Depth สำหรับงาน Self-Hosting ง่าย ๆ กัน...

Functional Programming คืออะไร ? ทำไมมันถึงเป็นเรื่องที่น่าสนใจในยุคใหม่
11 เมษายน 2026 - 2 min readก่อนหน้านี้ไม่ค่อยได้สนใจการเอา Functional Programming มาใช้ในงานเท่าไหร่ แต่พอได้ลิ้มรสเท่านั้นแหละ มันเหมือนโลกใหม่มาก ๆ เข้ามาแก้ปัญหาหลาย ๆ อย่างที่เคยได้เจอมา วันนี้เราจะมาเล่ากันว่า มันคืออะไร และ มันน่าจะเหมาะกับงานไหนกัน...