DNA Sequencing ฉบับคนทั่วไป (อยู่) ตอน 3 : Next-Generation Sequencing
By Arnon Puitrakul - 07 ธันวาคม 2022
ตอนก่อน เราได้เล่าไปถึงเรื่องของการทำ DNA Sequencing ในยุคแรก ๆ กันไปแล้ว กลับไปอ่านได้ที่ บทความนี้ ข้อเสียของวิธีการพวกนั้นคือ มันใช้ คน เวลา และ เงินเยอะมาก ๆ ในการจะ Sequence DNA จำนวนเยอะ ๆ หรือขนาดใหญ่ ๆ เมื่อเวลาผ่านไป เทคโนโลยีใหม่ ๆ มันก็เข้ามาเรื่อย ๆ มีเยอะมาก ๆ เราเลยเรียกพวกนี้ว่า Next-Generation Sequencing (NGS) Technology
เขาทำกันยังไง ?
จริง ๆ แล้วพวกการทำ NGS มันมีหลายวิธีมาก ๆ เพราะต่างคนก็ต่างคิดวิธีของตัวเองออกมาแล้วทำเป็นเครื่องกับพวกชุดอุปกรณ์มาขายกัน ก็แล้วแต่ Lab แล้วว่า จะเอา Platform ไหนมาใช้งานกัน หลัก ๆ ที่เราได้ยินในตลาดกันเยอะ ๆ สุด ๆ ก็จะเป็นฝั่ง Illumina หรือจะเป็นบางที่เราก็ยังเห็นใช้พวกเครื่องที่ใช้หลักการ Ion Torrent ของ ThermoFisher ก็เจอเหมือนกัน หรือถ้าในสายพวกของเล่นใหม่ ๆ หน่อย อย่างเราเองก็จะมาเป็นฝั่งของ Oxford Nanopore ที่จะเป็นเทคโนโลยีใหม่ ๆ หน่อย
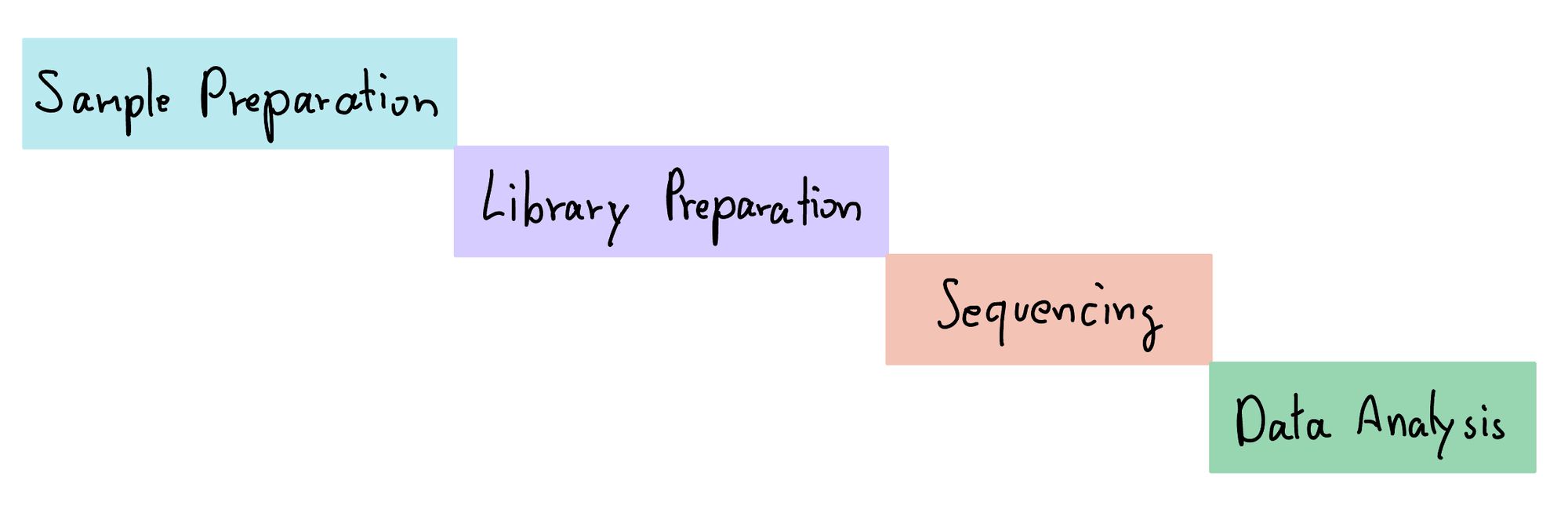
แต่ละวิธี ถ้าเราพยายาม Simplified ขั้นตอนออกมา ได้ประมาณ 4 ขั้นตอนใหญ่ ๆ คือ Sample Preparation, Library Preparation, Sequencing และ Data Analysis
ขั้นตอนแรกคือ การทำ Sample Preparation หรือก็คือการเตรียมตัวอย่าง เหมือนเวลาเราจะดื่มน้ำ เราก็ไม่อยากจะได้น้ำที่สกปรก หรือปนเปื้อนมาดื่มใช่มะ เครื่อง Sequencer มันก็ไม่ชอบเหมือนกัน ทำให้เราจะต้องทำการกรอง หรือทำให้อยู่ในรูปของ DNA ให้เรียบร้อยก่อน เช่นบางครั้ง เราได้ตัวอย่าง DNA มา แต่ความเข้มข้นต่ำ ก็ PCR เพิ่มจำนวนมั้ย หรือมันมีอะไรปนเปื้อนเยอะ เราก็ Purified มันจะมีพวก Kit ให้เราซื้ออยู่ หรือ เราอาจจะได้เป็นตัวอย่างที่ไม่ได้เป็น DNA ตรง ๆ อย่าง RNA เช่นเวลาเราจะ Sequence COVID-19 มันเป็น RNA Virus เราก็ต้องเอามา Reverse Transcription มันก็จะมี Kit ขายเช่นกัน ฮา ๆ (ขี้เกียจเล่าก็บอกว่า มันมี Kit ขาย ถถถถถ) หรือ อาจจะได้มาเป็นตัวอย่างเซลล์ เราก็ต้องเอามา สกัด (Extraction) สุดท้าย สิ่งที่เราต้องการคือตัวอย่าง DNA ที่บริสุทธิ์ และ เข้มข้นมากพอที่จะเอามาทำได้ (เท่าไหร่นั่น ต้องไป Optimise Protocol เอานะ ขึ้นกับงาน กับเครื่อง ตอบไม่ได้เหมือนกัน)
เมื่อตัวอย่างพร้อมแล้ว ขั้นตอนที่ 2 คือการทำ Library Preparation เป็นอีกขั้นตอนในการเตรียมตัวอย่างของเราให้พร้อมสำหรับเครื่อง เพราะเครื่องมันจะมีกลไกของมันในการอ่านเบสอะไรพวกนั้นอยู่ ทำให้ Sequencing Platform หลาย ๆ อย่างต้องมีการติดตั้งอะไรบางอย่างลงไปในตัวอย่างเพื่อให้มันเข้ากับตัวกลไกของเครื่อง Sequence เช่นมีการติด Adapter บางอย่างลงไปในตัวอย่างอะไรแบบนั้น
เท่านี้ตัวอย่างก็พร้อมสำหรับเครื่องแล้ว ทำให้ในขั้นตอนที่ 3 คือการ Sequencing หรือก็คือ การโหลดตัวอย่างจากขั้นตอนก่อนหน้าลงในเครื่อง แล้วปล่อยให้เป็นหน้าที่ของเครื่องในการจัดการต่อไป ในหน้างานจริง ก็คือ Moment of Truth สาด ถ้าเราลืมหรือทำอะไรผิด ตรงนี้แหละ เครื่องมัน Abort หยุดทำงานเลยนะ ถถถ
และขั้นตอนสุดท้ายคือ Data Analysis เมื่อเราได้ข้อมูลจากเครื่อง Sequencer แล้ว เราก็จะเอาข้อมูลมาจัดการวิเคราะห์เพื่อตอบคำถามที่เราต้องการ เรื่องนี้เราถนัดเลย ไว้จะมาเล่าแยกในตอนหน้าเลยละกัน มันทำอะไรได้เยอะมาก ๆ
ซึ่งแต่ละ Sequencing Platform ก็จะมี 4 ขั้นตอนนี้แหละ แต่อาจจะมีการเตรียมที่แตกต่างกัน ขึ้นกับหลักการที่ใช้ และสำหรับคนที่ทำจริง ๆ ก็อาจจะมี Protocol อะไรบางอย่างเพิ่มเติมเข้าไปด้วย ซึ่งในวันนี้เราจะเอาหลักการของ 2 Platform หลัก ๆ ที่เราใช้งานมาเล่าละกันคือของ Illumina และ Oxford Nanopore (อันอื่นไม่กล้าเล่า เดี๋ยวโป๊ะ ไม่เคยใช้)
Illumina Platform
เริ่มที่ตัวแรก เราว่าใช้งานกันเยอะมาก ๆ แบบเยอะมากจริง ๆ โดยเฉพาะในฝั่งของงานวิจัย คือกลุ่มพวก Illumina หรือมีช่วงนึง ก็ส่งไปในบริษัททำให้เหมือนกัน ถถถถถ
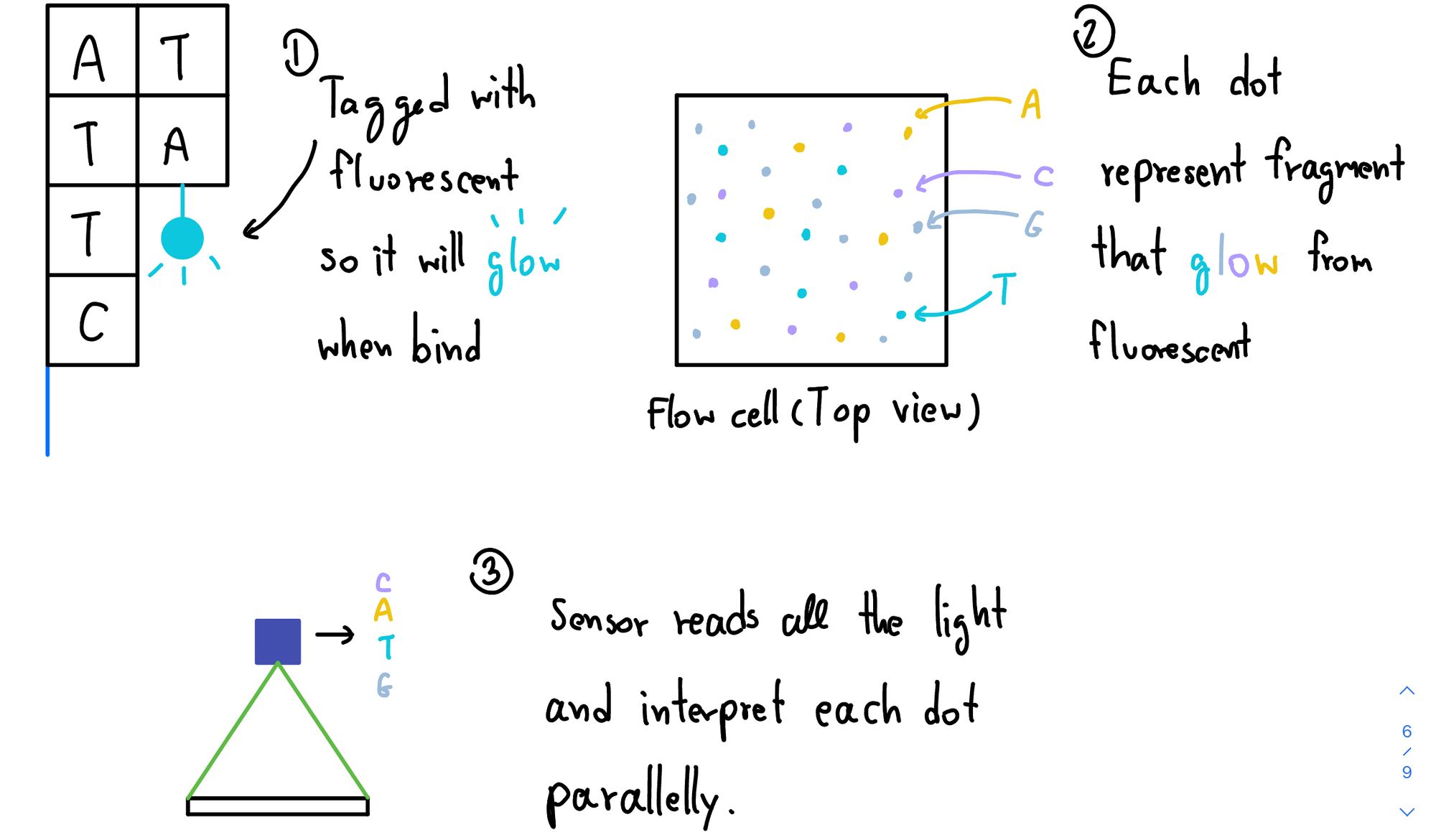
หลักการที่ Illumina Platform เขาใช้คือ Sequencing by synthesis (SBS) ให้เราคิดง่าย ๆ เลย มันคือการทำ PCR (Polymerase Chain Reaction) เลย แต่ตัว Nucleotide ที่เราใส่เข้าไปมัน Tag พวก Fluorescent เข้าไปด้วยทำให้เวลามันไปเกาะ มันก็จะมีแสงออกมา เครื่องก็จะมี Sensor สำหรับจับแสงพวกนี้แหละ แล้วเอามาตีความเป็น Base ที่เราอยากได้มานั่นเอง แต่ความพีคคือ เราทำแบบที่เราว่ามาหลายล้านอันพร้อม ๆ กัน ทำให้มันได้ Throughput สูงมาก ๆ สูงกว่าแบบเมื่อก่อนเยอะมาก ๆ
ซึ่งเขาก็มีการพัฒนานะ ให้เครื่องมันทำงานได้เร็วขึ้น เยอะขึ้นเรื่อย ๆ เหมือนกัน พวกการออกแบบพวกสารที่เอามาใช้ทำให้มันสามารถสังเคราะห์ได้เร็วขึ้นอ่านได้เร็วขึ้น หรือกระทั่งการออกแบบ Flowcell ให้มีความหนาแน่นสูงขึ้น ทำให้เราสามารถ Sequence ได้ด้วยจำนวนที่เยอะขึ้น
ซึ่งเครื่องที่เราใช้งานกันจาก Illumina ตอนนี้คือมีหลายขนาดมาก ๆ ตั้งแต่เราไป Sequence Gene ไม่ยาวมาก หรือ Whole Genome ของพวกแบคทีเรีย จนไปถึงสเกลของ คน และ พืชเลย พวกเครื่องเล็ก ๆ ก็พวก MiSeq พวกนี้ทำในระดับของ Gene เท่านั้นเองหรือเอามาใช้กับ Whole Genome ของพวก Virus ก็ไหวอยู่ ขนาดตั้งบนโต๊ะหรือ Lab Bench ได้ง่าย ๆ หรืออีกเครื่องระดับ Genome มนุษย์เลยคือกลุ่มรุ่น NovaSeq เคยเล่น NovaSeq 6000 อยู่ ใหญ่โต อลังการมาก เห็นมี NovaSeq X ออกมา ก็คือ เชร็ดเข้ !!!
ข้อดีของฝั่ง Illumina ถ้าเราเอามาใช้ในงานวินิฉัยต่าง ๆ เขาจะมีเครื่องอีกรุ่นที่ใส่พวก Pipeline สำหรับการทำงานพวกนี้ขึ้นมาให้เราเลย ซึ่งตัวพวกนี้เราก็ไม่เคยใช้เหมือนกัน อยากลองเล่น Lab ใครมีพาไปเล่นโหน่ยยยย ใครซื้อ NovaSeq X มาพาไปเล่นหน่อย อยากเล่น ถถถถ
Oxford Nanopore
อีก Platform ที่เป็นตัวที่มาใหม่ (จริง ๆ ก็หลายปีมาก ๆ แล้วแหละ) คือกลุ่มของ Oxford Nanopore พวกนี้ก็จะใช้อีกวิธีหนึ่งไปเลยในการที่จะ Sequence จากวิธีของ Illumina เราใช้แสงสี แต่อันนี้เราใช้ วิธีการที่เรียกว่า Strand Sequencing เขาจะวัดการเปลี่ยนแปลงของกระแสไฟฟ้า แทน อ่านแล้วอาจจะ งง นะ แต่เราค่อย ๆ มาดูกันดีกว่า
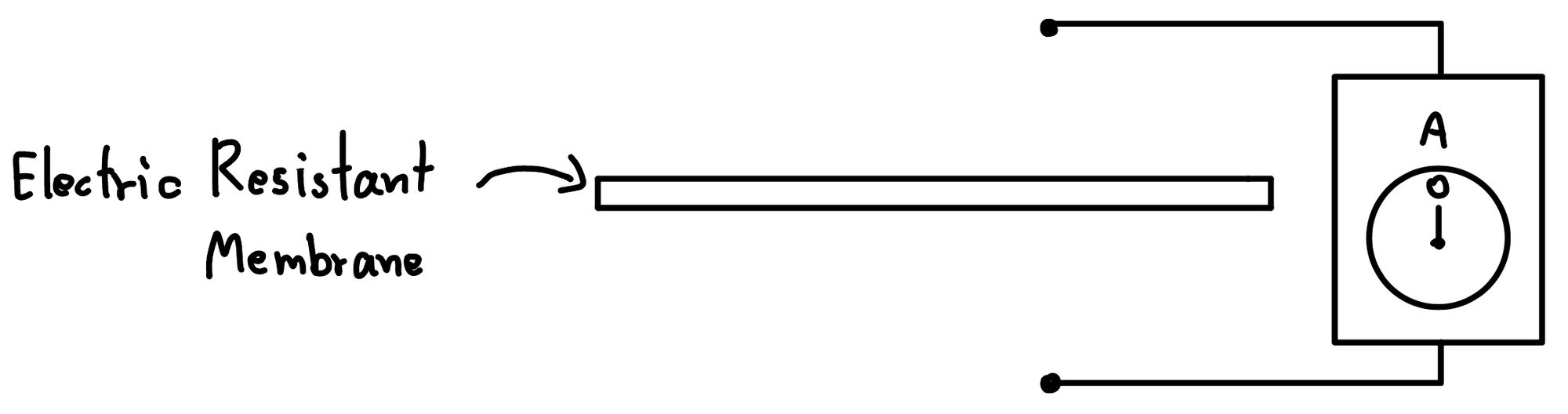
หลักการของวิธีการนี้คือ เราจะใช้วัสดุบางอย่างที่มันไม่นำไฟฟ้า เป็นเหมือนพื้นผิว เมื่อเจอแบบนี้ ทำให้ของจากด้านบน และ ล่างไม่สามารถไปมาหากันได้ ทำให้ถ้าเราจ่ายไฟเข้าไประหว่าง 2 ด้านนี้ แล้ววัดกระแสไฟฟ้าออกมา มันก็จะเป็น 0 ใช่มะ เพราะมันไปหากันไม่ได้
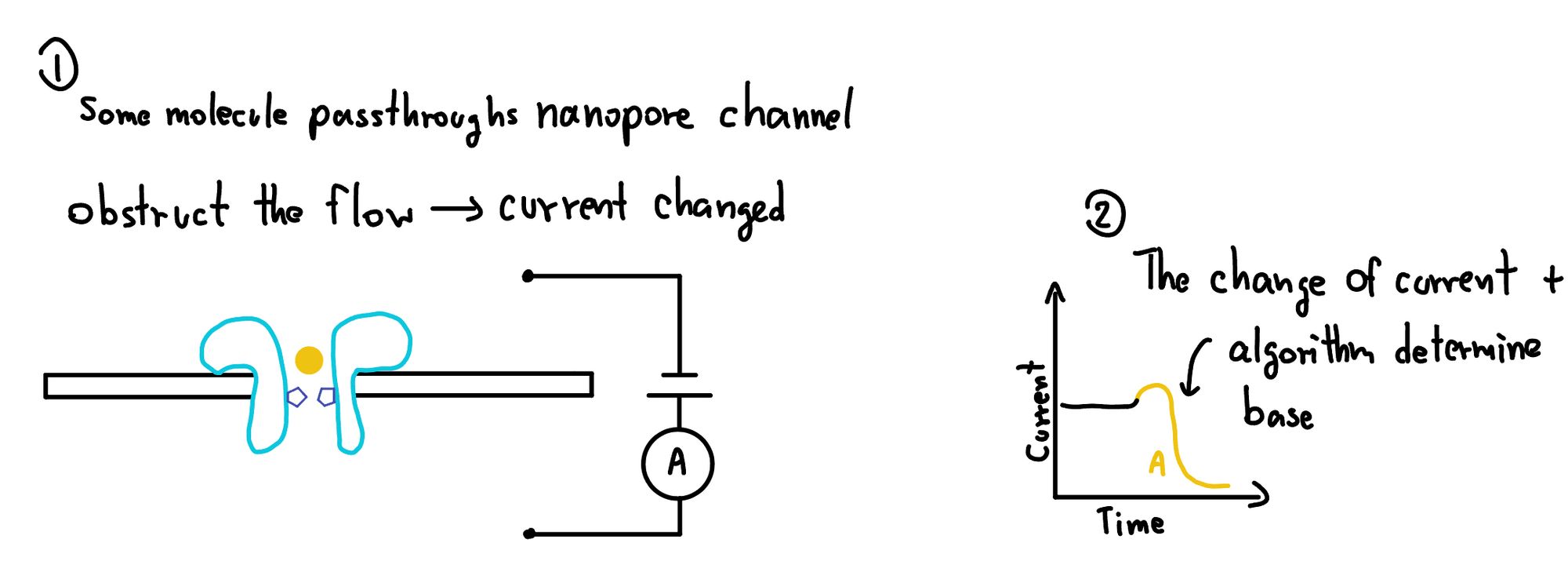
สิ่งที่เขาทำกันคือ เขาเอาโมโลกุลบางอย่าง ที่มีรู เราเรียกว่า Nanopore ไปเสียบเข้าไป ทำให้มันมีการไหลของไฟฟ้าข้ามไปเกิดขึ้นนั่นทำให้เราวัดได้ละ แต่ทีนี้ ถ้าเราเอาอะไรหย่อนเข้าไปในรู มันก็จะไหลผ่านไป แต่รูมันเล็กมาก ๆ พอของไหลผ่าน อ้าว ไฟแทนที่จะไหลได้เยอะหน่อยกลับโดนขัดซะได้ ทำให้เกิดการเปลี่ยนแปลงของกระแสไฟฟ้าเกิดขึ้น ตรงนี้แหละ ที่เราวัด ทำให้เราตีความออกมาได้
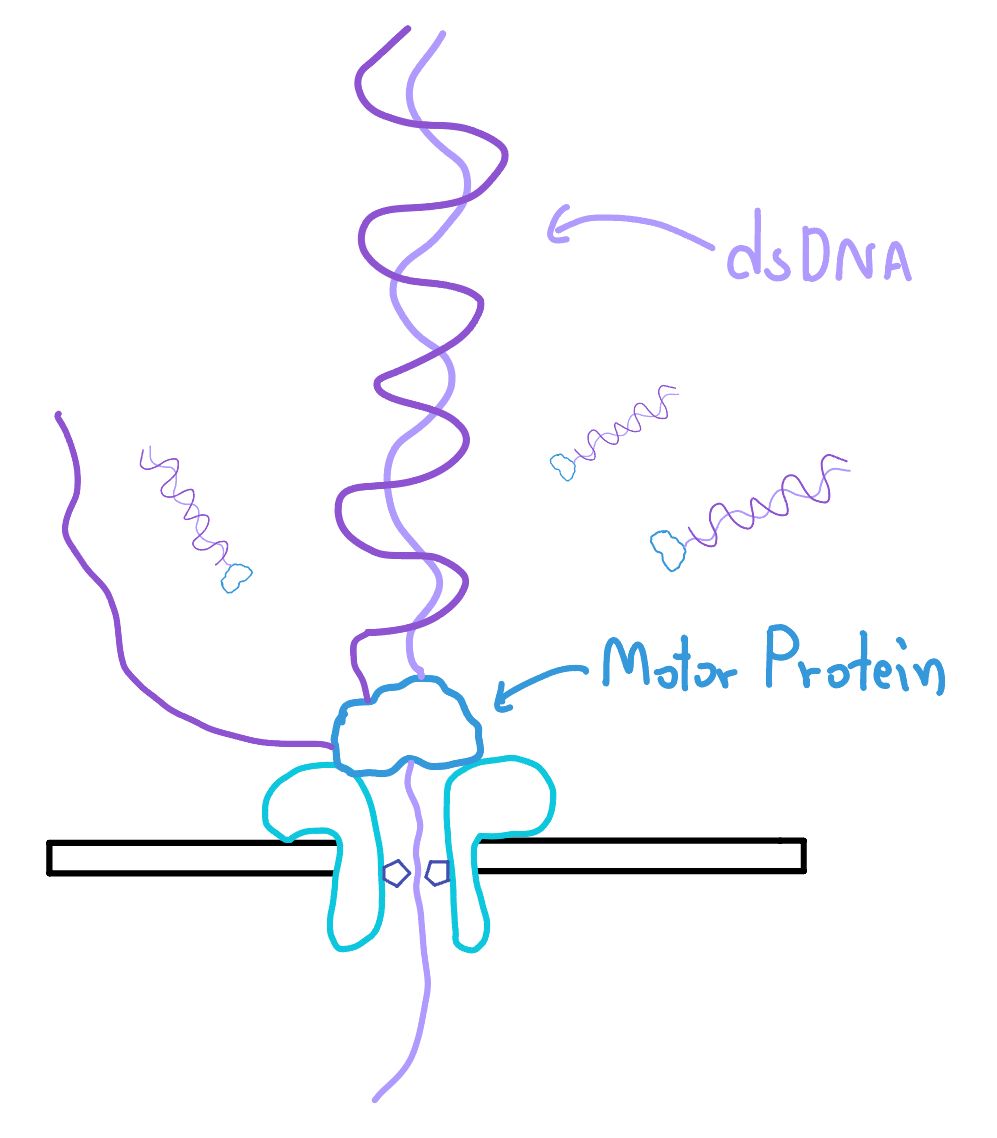
ในส่วนของ DNA เอง เราก็จะต้องมีขั้นตอนของการทำ Library Preparation เหมือนกันคือ เราจะต้องเอา DNA ของเราผสมกับ Enzyme บางอย่าง แต่ส่วนที่สำคัญจริง ๆ คือ Motor Protein มันจะทำหน้าที่ค่อย ๆ ดึง DNA ด้านนึงลงไปในหลุม โดยที่มันจะคลี่อีกด้านออกไป เมื่อ DNA วิ่งผ่าน Nanopore มันก็จะมีการเปลี่ยนแปลงของกระแสไฟฟ้าอย่างที่เราบอก เมื่อเสร็จ 1 เส้น ตัวเส้นใหม่มันก็จะเข้ามาทำแบบนี้ไปเรื่อย ๆ นั่นทำให้จุดเด่นตัวนึงคือ การทำงานแบบ Real-time จริง ๆ เราเห็นแต่ละเส้นถูกอ่านตอนนั้นเลย
คือเวลา Sequence เราจะได้ข้อมูลออกมาเป็นเส้น ๆ เลย เพราะเราเล่นรูดไปเรื่อย ๆ จบเส้นนึง ต่ออีกเส้นไปเรื่อย ๆ ต่างจากวิธีอื่น ๆ อย่าง SBS ที่มันจะทำทั้งหมดพร้อม ๆ กัน แต่ไม่เสร็จสักอัน มาเสร็จตอนสุดท้ายพร้อม ๆ กัน

หรือถ้าเราอยากรู้ทั้งสองด้านของ DNA เลย เราสามารถ Bind Hairpin Molecule เข้าไปเพื่อทำให้เวลา Motor Protein รูด DNA ด้านนึงหมดแล้ว มันก็จะผ่าน Hairpin แล้วไปรูด DNA อีกด้านให้ Nanopore อ่านนั่นเอง การทำแบบนี้ ทำให้เราสามารถ Validate ข้อมูลได้เลยว่า เห้ย Base นี้น่าจะผิด เพราะเรารู้อยู่แล้วว่า A คู่ T และ C คู่ G เท่านั้น
นอกจากนั้น พอเราใช้วิธีการให้ DNA รูดผ่านรูเล็ก ๆ ไปทำให้เราติดเรื่องข้อจำกัดของความยาวต่อการอ่านที่เกิดอยู่บนพวก Illumina ไปเลย เพราะพวกนั้นมันจะมีข้อจำกัดจากการที่เราจะต้องสังเคราะห์เส้นใหม่เรื่อย ๆ ทำให้เราอ่านมันได้ยาวมาก ๆ Illumina อาจจะอ่านได้ 300 Base แต่ Nanopore เราอ่านกันระดับ 500 Base จนไปถึง 2 Mb (Million base) ทำให้การประกอบร่าง หรือการนำข้อมูลมาวิเคราะห์บางอย่างมันง่าย หรือเป็นไปได้เลยด้วยซ้ำ
เครื่องของ Oxford Nanopore มันทำให้การทำงานค่อนข้างยืดหยุ่นมาก ๆ เพราะเขามีเครื่องขนาดเล็ก ๆ ยันใหญ่อลังการงานสร้างแบบสุด ๆ อย่าง Illumina เล็กสุด เราก็ต้องวางบนโต๊ะ แต่เล็กสุด ๆ ของ Oxford Nanopore คือรุ่น MinION (เราชอบเรียกว่า มินเนี่ยน) ขนาดเท่าฝ่ามือ ใส่กระเป๋ากางเกงได้อะคิดดู (แต่อย่าใส่จริงนะ ขอร้อง เสียว กลัวพัง) หรือเครื่องใหญ่สุด คือ PromethION บอกเลยว่าใหญ่จริง ใช้แล้วฟิลเหมือนขับ Fortuner บนถนนไทยอะ
ถามว่า ต่างขนาดไหน ถ้า MinION Max Output เราอยู่ที่ ประมาณ 50 Gb (Gigabase) แต่ ระดับ PromethION ได้อยู่แถว ๆ 13-14 Tb (Terabase) ก็คือ อลังการสุด ๆ เลยละ คิดดูว่า ถ้าได้ข้อมูลจาก PromethION มาก็คือ คอมที่ใช้เก็บมันต้องขนาดไหน คอมที่ใช้วิเคราะห์คืออลังแน่นอน ไม่งั้นก็คือโหลดข้อมูลก็เต็มแล้ว
แต่ละ Platform มันก็มีข้อดีข้อเสียไม่เหมือนกัน
ซึ่งแต่ละเทคโนโลยีมันก็จะมีข้อดี ข้อเสียที่แตกต่างกัน แล้วในตลาดหลาย ๆ เจ้า โดยเฉพาะเจ้าใหญ่ ๆ ก็มีการพัฒนาเทคโนโลยี Platform ของตัวเองให้ดีขึ้นเรื่อย ๆ Sequence ได้ยาว ได้แม่นยำมากขึ้นเรื่อย ๆ ถ้าเราอยู่ในวงการคอมพิวเตอร์ เราก็อาจจะเคยได้ยินพวกที่เขา Overclock CPU ให้แรงมากขึ้นเรื่อย ๆ แต่ในวงการ Sequencing ก็มีอะไรแบบนี้เหมือนกัน เช่น เราทำให้มัน Sequence ได้ยาวขึ้น ทำ Throughput ได้สูงขึ้น ใช้เงินต่อตัวอย่างน้อยลงอะไรแบบนั้น
อย่างในเรื่องของ ความยาวในการอ่าน เรื่องนี้เราก็ต้องใช้ Nanopore เขาแหละ เพราะเขาอ่านได้ยาวมาก ๆ ยาวแบบ โลกหน้าแล้ว มันก็มีงานที่อยากได้ยาว ๆ เหมือนกัน ไว้เรามาเล่าว่ามันเอามาทำอะไรบ้าง
แต่ถ้าเราพูดถึงเรื่อง Throughput เมื่อก่อนก็ต้องยอมรับนะว่า ยังไง Nanopore คือกินขาด จนไปอ่านสเปกของ NovaSeq X ก็คือ Illumina กลับมาทวงที่แล้วค่าาา เพราะมันกดได้สุด ๆ 16 Tb (Terabase) แต่ ฝั่ง Nanopore PromethION ได้ 13-14 Tb เท่านั้นเองแต่ก็ถือว่าใกล้ ๆ กันแหละ
ในขณะที่ความแม่นยำก็ยังเป็นข้อดีของฝั่ง Illumina มาก ๆ เลย เราชอบใช้เอามาเป็น Confirmation มากกว่า ว่า ที่เราทำมาจากเครื่องอื่นถูกเยอะขนาดไหน ทำให้จริง ๆ แล้วพวกกลุ่มของเครื่อง Illumina มันเลยจะไปเหมาะกับการศึกษาพวก Variation หรืออะไรที่เราจะต้องดูการเปลี่ยนแปลงระดับตำแหน่งต่อตำแหน่งตรง ๆ เลย มันจะชัวร์กว่าเยอะมาก
ทำให้เราเห็นได้ว่า ในช่วงนี้ก็คือพวกบริษัทที่ทำเครื่อง Sequencing มันแข่งกันหนักมาก ๆ ในอุตสาหกรรมนี้ เพราะบอกเลยว่า มันจะเป็นยุคต่อไปของการศึกษาในหลาย ๆ ด้านเลย ทั้งชีววิทยา การแพทย์ จนไปถึงโบราณคดีด้วยซ้ำ นอกจาก 2 เจ้าที่เราเล่าไปก็จะมีพวก กลุ่มของเครื่องหลักการ IoN Torrent และเครื่องฝั่ง PacBIO ที่ใช้ SMRT (Single Molecule Real-Time) บอกเลยว่า ต่อจากนี้คือ Game on ! ของจริงแล้ว
แล้วเราได้อะไร ?
จากวิธีการใหม่ ๆ ที่เราเอามาเล่ากันวันนี้ ยังเป็นวิธีที่เราใช้กันอยู่ทั้ง ในการวิจัย และ การวินิฉัย พวกข้อมูลลำดับ RNA ของ COVID-19 ที่เราเห็นกันทุก ๆ วันนี้ก็มาจากพวก Sequence Platform พวกนี้แหละ ทำให้เราสามารถเข้าใจการกระจายตัวมันได้ ทำให้เราทำนายลักษณะพิเศษของมันได้ เพื่อให้เราเข้าใจมันและหาทางกำจัดได้ง่ายขึ้น หรือในแง่ของคนเอง เราก็เอามาศึกษาความผิดปกติทางพันธุกรรมต่าง ๆ เพื่อหาวิธีรักษา และ ป้องกัน หรือจะเป็นพวกมะเร็งเองก็มีการเอามาใช้เยอะขึ้นเรื่อย ๆ ซึ่งในวันนี้เราเอาแค่วิธีการ Sequence มาเล่าละ ในตอนหน้า เราจะมาเล่ากันต่อว่า แล้ว ข้อมูลที่เราได้ตรงนี้ เป็นข้อมูลลำดับ DNA จากเครื่อง Sequencer มันเอามาวิเคราะห์อย่างไรเพื่อตอบปัญหาต่าง ๆ กัน
Related Posts

Perfume Science 101: น้ำหอมโมเลกุลสังเคราะห์ vs โมเลกุลธรรมชาติ
01 สิงหาคม 2025 - 2 min readเวลาเราดูโฆษณาน้ำหอม โดยเฉพาะตัวที่มีราคามากหน่อย มักจะเห็น เขาใช้คำเคลมว่า กลิ่นมาจากธรรมชาติจริง ๆ ไม่ใช่โมเลกุลสังเคราะห์นั่นนี่ บ้างบอกว่าพวกสังเคราะห์เนี่ยเป็นอะไรที่อันตรายมาก ๆ นะ วันนี้เราจะมาเล่าให้อ่านในเชิงวิทยาศาสตร์กันว่า มันเป็นแบบนั้นจริงหรือไม่ เราควรจะเลี่ยงมันจริง ๆ เหรอ...

หลังจากมะนาวโซดา ไปโซดามิ้นท์กันแล้วชะลอวัยกี่โมง
17 มิถุนายน 2024 - 1 min readมันมีลัทธิกิน โซดามิ้นท์ กันแล้วหวะทุกคน นี่มันอะไรกันวะเนี่ย หลังจากมะนาวโซดาฆ่ามะเร็ง สู่โซดามิ้นชะลอวัยกันแล้ว วันนี้เราจะมาเล่าให้อ่านกันว่า คนที่เขาอ้าง เขาอ้างว่ากินยังไง ทำไมถึงมีผลแบบที่เขาบอกได้จริง และเราจะเล่าในเชิงวิทยาศาตร์ทางการแพทย์ว่า ทำไมมันอันตรายกว่าที่ทุกคนคิด...

เจาะลึกเบื้องหลังการทำงานของ กันแดด ทำไมมีหลายแบบ จะเลือกอย่างไร
18 มีนาคม 2024 - 3 min readถ้าต้องให้เลือก Skin Care แค่อย่างเดียวเราะจะเลือกอะไร เราคงตอบได้อย่างรวดเร็วว่า กันแดด แน่นอน แต่ถ้าเราลองไปดูกันแดดในท้องตลาดบ้านเรา มันมีเยอะมาก มีหลายประเภทสารพัด วันนี้เรามาเล่าให้อ่านกันในเชิงวิทยาศาสตรดีกว่าว่า มันมีแบบไหน และ แบบไหนเหมาะอะไรกับใครบ้าง...

มันจะไม่มีอีกแล้วหมาล่าแดง ๆ กับ Sudan Red
15 มีนาคม 2024 - 1 min readเราอ่านข่าวเจอเรื่องการที่ไตหวันพบการแพร่ระบาดของการผสมสีอย่าง Sudan Red ลงไปในเครื่องปรุงต่าง ๆ โดยเฉพาะพริก และพวกผงหมาล่าที่นำเข้าจากประเทศจีน วันนี้เราจะมาเล่าให้อ่านกันว่า สรุปแล้วเรื่องมันเป็นอย่างไร และ สีเจ้าปัญหาอย่าง Sudan Red มันเป็นอันตรายต่อมนุษย์อย่างไร...