ย่อขนาด Numpy Array ใน 1 บรรทัด
By Arnon Puitrakul - 05 พฤศจิกายน 2020
สำหรับคนที่ใช้ Python ในการทำงาน น่าจะเคยได้ยิน Numpy ที่เป็น Library สำหรับการทำงานที่เกี่ยวกับการคำนวณได้ดีโคตร ๆ เร็วด้วย แต่ปัญหานึงที่เราอาจจะเจอ เมื่อ เราทำงานกับข้อมูลขนาดใหญ่คือ ปริมาณ RAM ที่มันกินเข้าไป ถือว่าเยอะมาก ๆ วันนี้เราจะมาสอนวิธีที่ทำให้ขนาดของ Memory มันน้อยลงเยอะมาก ๆ กัน
หยุดกินไผ่ก่อน
โดยปกติ เวลาเราโหลดข้อมูลเข้ามา เราจะใช้ Pandas ก็น่าจะเป็นตัวที่ง่ายที่สุดแล้ว ในการอ่าน CSV File เข้ามา แต่เมื่อเวลาเราจะ Pre-Process มัน หรือ ทำงานกับมันตรง ๆ เราจะเห็นได้ชัดเลยว่า มันช้ามาก ๆ ถ้าเจอปัญหานี้ เราแนะนำเลยว่า ก่อนที่เราจะทำอะไร ให้เราแปลงมันให้อยู่ในรูปของ Numpy Array ก่อนที่เราจะทำงานกับมัน ช่วยให้การคำนวณ หรือ Operation ต่าง ๆ ทำได้เร็วกว่าเยอะมาก
โดยเฉพาะกับข้อมูลที่เป็นตัวเลข Numpy ทำได้ดีมาก ๆ ก่อนหน้านี้ เราใช้ Pandas อย่างเดียวเลย ปรากฏว่าช้ามาก เวลาเราจะ Transpose เรื่องใหญ่เลย เพราะเรา Transpose ในตารางขนาดกว้าง 500 ช่อง กับยาวอีก 500 ล้านช่อง ก็คือ เกมจ๊ะ แต่พอมาใช้ Numpy เห็นได้เลยว่ามันช่วยได้เยอะมาก ทำได้เร็วขึ้นมาก
ใช้ Data Type ให้พอดีกับข้อมูล
วิธีที่เราจะเอามาเสนอในวันนี้คือ การที่เราเปลี่ยน Data Type ใน Array ให้เข้ากับข้อมูลของเรา ใครที่เรียนเขียนโปรแกรมมา เราน่าจะพอรู้จัก Data Type อยู่ละ ซึ่งในแต่ละแบบ มันก็จะมีข้อจำกัดที่ต่างกัน และ มีขนาดในการเก็บที่ต่างกันมาก
หรือที่เราเคยเจอคือ เวลาเราเอา Python Script ตัวเดียวกัน กับ HW เดียวกัน แต่ OS ต่างกัน ปรากฏว่า มันใช้ Memory ไม่เท่ากันอีก เหตุมันเกิดจาก Data Type นี่เหมือนกัน คือ โดยปกติ ถ้าเราแปลง หรือ สร้าง Numpy Array ออกมา และ เราไม่ได้กำหนด Data Type มันจะเลือกให้เอง ส่วนใหญ่มันจะเลือก Data Type ที่เป็น Standard Data Type กล่าวคือ ในแต่ละ OS ก็จะมีการกำหนดขนาดมาให้ไม่เหมือนกัน แต่เคสนี้เราเจอไม่ละเยอะ เพราะ OS เดี๋ยวนี้ทำมาได้เหมือนกันหมดละ
import numpy as np
normal_int = np.ones((256,256))เราลองมาจำลองสถานการณ์กัน ด้วยการสร้าง Array ที่มีแต่เลข 1 ขนาดสัก 256x256 ถ้าเราลองเอาค่าออกมาดู เราก็จะเห็นว่ามันเป็น Array ที่มีแต่ 1 หมดเลย หรือถ้าเราใช้ np.zeros ก็จะได้ 0 ออกมาทั้งหมด อันนี้ใช้ได้ดีเลย เวลาเราต้อง Encode ค่า ทำให้ทำได้เร็วขึ้นมาก
> print(normal_int.nbytes)
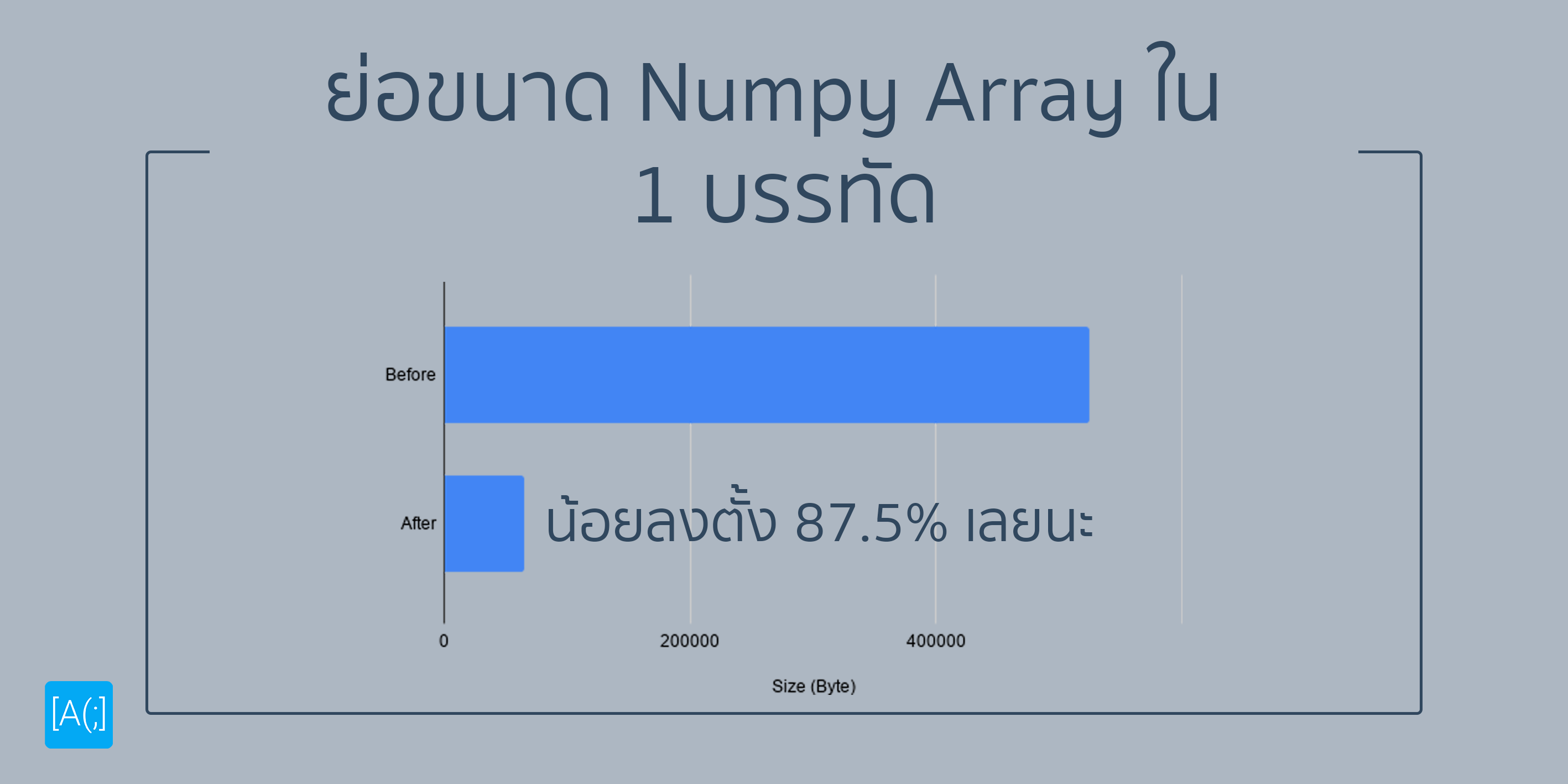
524288ใน Numpy เอง ก็จะมีคำสั่งสำหรับการเรียกขนาดของ Array นั้น ๆ ออกมาได้ด้วย ผ่าน Property ที่ชื่อว่า nbytes จากอันนี้เราก็จะได้ออกมา 524288 bytes หรือ 524.288 kB
> small_int = np.ones((256,256), dtype=np.uint8)
> print(small_int.nbytes)
65536แต่เมื่อเรากำหนด Data Type ลงไป ในที่นี้เรากำหนดเป็น Unsigned Integer ที่ใช้ขนาด 8 Bits เข้าไป และเอาขนาดออกมา เราจะเห็นว่าขนาดมันเล็กลงอย่างเห็นได้ชัด เหลือเพียง 65.536 kB เท่านั้นเอง หรือ หายไป 87.5% เลยทีเดียว ที่ดูมันหลัก kB เพราะ Data เรายังไม่ใหญ่ไง แต่ถ้า Data เราใหญ่แบบที่เราใช้ทำงานจริง ๆ มันหายไปหลาย GB เลยละ
ในตัวอย่างนี้ การที่เราใช้ Unsigned Integer ขนาด 8 Bits มันก็ทำให้เราสามารถเก็บตัวเลขที่มีค่าเป็นบวกได้แค่ 0-255 เท่านั้น ซึ่งเอาจริง ๆ สำหรับคนที่ทำพวก Computer Vision น่าจะใช้ประโยชน์จาก Data Type ประเภทนี้ได้เป็นอย่างดี เพราะมันคือ จำนวนค่าสีในแต่ละ Channel ของ RGB นั่นเอง โดยปกติ ถ้าเราไม่กำหนด และเราอาจจะทำ Augmentation หรือไม่ก็โหลดรูปใน Batch ที่มีขนาดใหญ่มาก ก็จะเจอกับปัญหา Memory ไม่พอ วิธีนี้ก็เข้ามาช่วยได้เช่นกัน
สิ่งที่อยากจะเน้นย้ำคือ เวลาเราจะแปลง Numpy Array ให้อยู่ใน Data Type ไหน อยากให้คำนึงด้วยว่า ในโปรแกรม ถ้าเราต้องมีการคำนวณ แล้วผลลัพธ์มันมีโอกาสที่จะเกิน Data Type ที่เราเลือกไว้มั้ย ก็อาจจะต้องลองดูกันไปว่า อาจจะเลือกให้ใหญ่พอไปเลย หรือ เราอาจจะสร้างขึ้นมาอีกตัว ก็เอาที่สบายใจ และ สะดวกเลย
สรุป
การกำหนด Data Type ให้กับ Array ของเราให้เข้ากับข้อมูล ทำให้เราประหยัด Memory ไปได้เยอะมาก อย่างงานที่เราทำ เราทำงานกับ Data ขนาดใหญ่มาก ๆ และ Data อยู่ในช่วงแค่ 0-4 เท่านั้นเอง แต่การที่เราต้องมาใช้ Int ปกติที่มีขนาด 4 Byte มันก็อาจจะใหญ่เกินกว่าความจำเป็นของเรา ยิ่งจำนวน Element เราเยอะขึ้น เราก็มี Memory ที่เสียไปเยอะมากขึ้นอีก ถือว่าช่วยชีวิตเราเลยก็ว่าได้
BONUS: เปลี่ยน Data Structure
อีกหนึ่งวิธีที่เราใช้คือ เราเปลี่ยน Data Structure ซะเลย เช่นพวก Array ที่มี 0 เยอะ ๆ ถ้าเก็บ 0 มันไปเลย มันก็จะเปลืองมาก ๆ วิธีนึงก็คือ การใช้พวก Sparse Array ก็ได้ หรือถ้าเป็นคนสด ๆ ชอบทำเองก็เอาที่สบายใจเลย
import numpy as np
from scipy.sparse import csr_matrix
ex_array = np.array([[1, 0, 0, 1, 0, 0], [0, 0, 1, 0, 0, 1], [0, 0, 0, 1, 0, 0]])
sparse_matrix = csr_matrix(ex_array)สำหรับใครที่ไม่อยากทำเอง เราสามารถใช้ Scipy ช่วยได้ จาก Code ด้านบนเลย ในตัวอย่าง เราเริ่มต้น จากการสร้าง Array ปลอมขึ้นมาก่อนเพื่อเป็นตัวอย่าง และ เราใช้คำสั่ง csr_matrix จาก scipy เพื่อแปลงเป็น Sparse Matrix ได้เลย
sparse_matrix.toarray()และเมื่อเราต้องการแปลงมันกลับเป็น Array แบบปกติ เราสามารถเรียกคำสั่ง toarray() ได้ มันก็จะคืนค่ากลับมาเป็น Numpy Array ถ้าเราอยากจะลดขนาดระหว่างการทำงาน เราก็สามารถเปลี่ยน Data Type ให้เข้ากับข้อมูลของเราได้
Related Posts

วิธีการและเทคนิคการ Capture เรื่องราวด้วย Obsidian
01 พฤษภาคม 2026 - 2 min readหนึ่งขั้นตอน Workflow ของ PKM ที่เป็นเหมือนการนำเข้าวัตถุดิบมาปรุงเป็นไอเดียดี ๆ ในอนาคต คือ การ Capture สิ่งที่เราได้เรียนรู้ หรือได้รับฟัง ดู อ่าน เข้ามา วันนี้เราจะมาเล่าวิธีการที่เราใช้กับ Obsidian กันว่า เราทำอย่างไร เพื่อให้ Workflow นี้ง่าย และเหมาะกับการใช้งานของเราที่สุด...

สร้าง WebAssembly Module แรกกันเถอะ
21 เมษายน 2026 - 2 min readจากบทความที่แล้ว ที่มาแนะนำ WebAssembly ไปว่า มันเป็นอะไรที่ค่อนข้างน่าสนใจ และน่าเรียนรู้เอาไว้มาก ๆ วันนี้เราจะมาพาทุกคนไปสร้าง WebAssembly Module แรกกัน และเทียบกันไปเลยว่า Performance ในงานที่ CPU Bound มาก ๆ มันจะห่างกันขนาดไหน...

Self-Hosted Service บน Home Lab จัดการอย่างไรให้ปลอดภัย
16 เมษายน 2026 - 3 min readช่วงหลัง ๆ กระแสการทำ Home Lab ฮิตขึ้นมาก ๆ ในประเทศไทยเรา มีคนถามเข้ามาเยอะมากว่า แล้วเราจะจัดการอย่างไรให้ระบบของเราปลอดภัยมากที่สุด วันนี้เราจะมารวบรวมวิธีคิดการวางสถาปัตยกรรมแบบ Defense-in-Depth สำหรับงาน Self-Hosting ง่าย ๆ กัน...

Functional Programming คืออะไร ? ทำไมมันถึงเป็นเรื่องที่น่าสนใจในยุคใหม่
11 เมษายน 2026 - 2 min readก่อนหน้านี้ไม่ค่อยได้สนใจการเอา Functional Programming มาใช้ในงานเท่าไหร่ แต่พอได้ลิ้มรสเท่านั้นแหละ มันเหมือนโลกใหม่มาก ๆ เข้ามาแก้ปัญหาหลาย ๆ อย่างที่เคยได้เจอมา วันนี้เราจะมาเล่ากันว่า มันคืออะไร และ มันน่าจะเหมาะกับงานไหนกัน...