Parallelise Python แบบปลอม ๆ ด้วย Joblib
By Arnon Puitrakul - 24 กันยายน 2020
จากตอนที่แล้ว เราคุยกันเรื่อง GIL ใน Python ที่ทำให้เรา ไม่สามารถเขียนโปรแกรมแบบ Parallel บน CPython โดยที่ไม่ติดเรื่อง GIL ได้ กลับไปอ่านได้ ที่นี่ ทำให้เกิดคำถามว่า แล้วถ้าเราอยากจะเขียนโปรแกรมที่มันทำงานแบบ Parallel ที่ไม่ติด GIL ละเราจะทำยังไง
ปัญหาที่เราเจอ
เรื่องของเรื่องมันมีอยู่ว่า เราต้องเขียนโปรแกรมที่อ่านไฟล์ที่ประกอบด้วยหลายล้านบรรทัด (ไฟล์ขนาดประมาณ 700 GB) ถ้าเกิดเราเขียนโปรแกรมด้วย Python แบบปกติเลย เราก็อาจจะเขียนเป็นแบบด้านล่างดังนี้
input_file = open(file_path, 'r')
line = input_file.readline()
while line != '' :
//Do Sth
line = input_file.readline()
input_file.close()ซึ่งแน่นอนว่า มันกินเวลาเยอะมาก เพราะจำนวนบรรทัดในไฟล์ที่เราต้องอ่านคือ เยอะมาก ๆ หลายล้านมาก ๆ เราลองทำแบบนี้ไป เราใช้เวลาประมาณ 10+ ชั่วโมงในการรัน ซึ่งเรารับความเร็วแค่นั้นไม่ได้ งานนี้มันควรจะต้องทำทั้ง Process ในเวลาไม่ถึง 3 ชั่วโมง ทำยังไงดี
ไอเดียบรรเจิดว่า งั้นเราลองทำ Parallel Version ของโปรแกรมนี้กัน ถ้าใครที่เรียน Parallel Computing มาก็นึกถึง Thread เลยใช่ม่ะ เออ งั้นเราก็แบ่ง Thread อะไรไปก็จบแล้ว ไม่น่าจะยากเท่าไหร่ แต่อันความ GIL ใน Python นั่นเอง ทำให้เราทำแบบนั้นไม่ได้ แล้วเราจะทำยังไงดีกับปัญหานี้
วิธีโง่ ๆ อันแรกที่นึกถึงคือ เออ ช่างมันละกัน ถ้าเราอยากจะใช้งานทุก Core และ เรามีไฟล์ที่ต้องทำงานด้วยหลายอัน เราก็สั่งรันพร้อม ๆ กันเลย เดี๋ยว OS มันก็แยก Core/Thread ให้เองด้วย Job Scheduling ของมันเองแหละ ถ้าเกิด เราต้องรันไฟล์เดียวก็จอบออะดิ
งั้นลองใหม่ เอางี้ เราลอง Split File ออกมามั้ย ถ้าเราบอกว่า 700 GB มันใหญ่ไป ใช้เวลาเยอะเกิน เราก็ Split ออกมาเลย เอาง่าย ๆ ก็ awk ไปซอยบรรทัดออกมา อ้าวกลับเสียเวลาขึ้นอีก เพราะ awk มันก็ไม่ได้เร็วขนาดนั้น หรือจะใช้ head มันก็ยังต้องอ่านทั้งหมดอยู่ดี สุดท้าย รัน Python Script อันเดียวเร็วกว่าแล้ว ทำไงดี
Joblib มาช่วยแล้ว
Joblib เป็น Module ตัวนึงใน Python ที่ผู้พัฒนาบอกว่ามันเป็น "lightweight pipelining in Python" โดยสิ่งที่มันทำได้ หลัก ๆ มันจะมีอยู่ 3 เรื่องคือ การจำ State ของ Function กล่าวคือ มันสามารถจำผลลัพธ์จาก Function เหมือนเป็น Cache เอาไว้ เมื่อเราเรียก Function เดิม ด้วย Pattern (Argument) เดิม มันจะทำให้เราไม่ต้องคำนวณ หรือทำซ้ำอีกรอบนั่นจะช่วยลดเวลาในการทำงานลงได้ ตัวอย่างง่าย ๆ คือ Factorial นั่นแหละ
อย่างที่ 2 เขาบอกว่า มันทำมาเพื่อแทนที่ Pickle บนตัวแปรที่มีข้อมูลขนาดใหญ่ขึ้น หรือก็คือการ Serialise ตัวแปรนั่นเอง
และอีกความสามารถคือ การเขียนโปรแกรมที่สามารถทำงานแบบ Parallel ที่อ่านง่าย และสามารถ Debug ได้อย่างรวดเร็ว อ่านประโยคนี้คนที่อ่านเรื่อง GIL เมื่ออาทิตย์ก่อนต้องกำหมัดแล้วว่า มันคืออะไรฟร๊ะเนี่ย
Parallel ใน Joblib มันทำงานยังไง
จากตอนก่อน เราบอกว่า ยังไง ๆ ถ้าเราเขียน Python ให้ Parallel ยังไง มันก็ติด GIL อยู่ดี ทำให้สุดท้าย ในบางเคส มันได้ความเร็วเท่าเดิมเลย ไม่ได้มี Performance Improvement ใด ๆ ทั้งสิ้น แต่สิ่งที่ Parallel ใน Joblib นางทำต่างออกไป
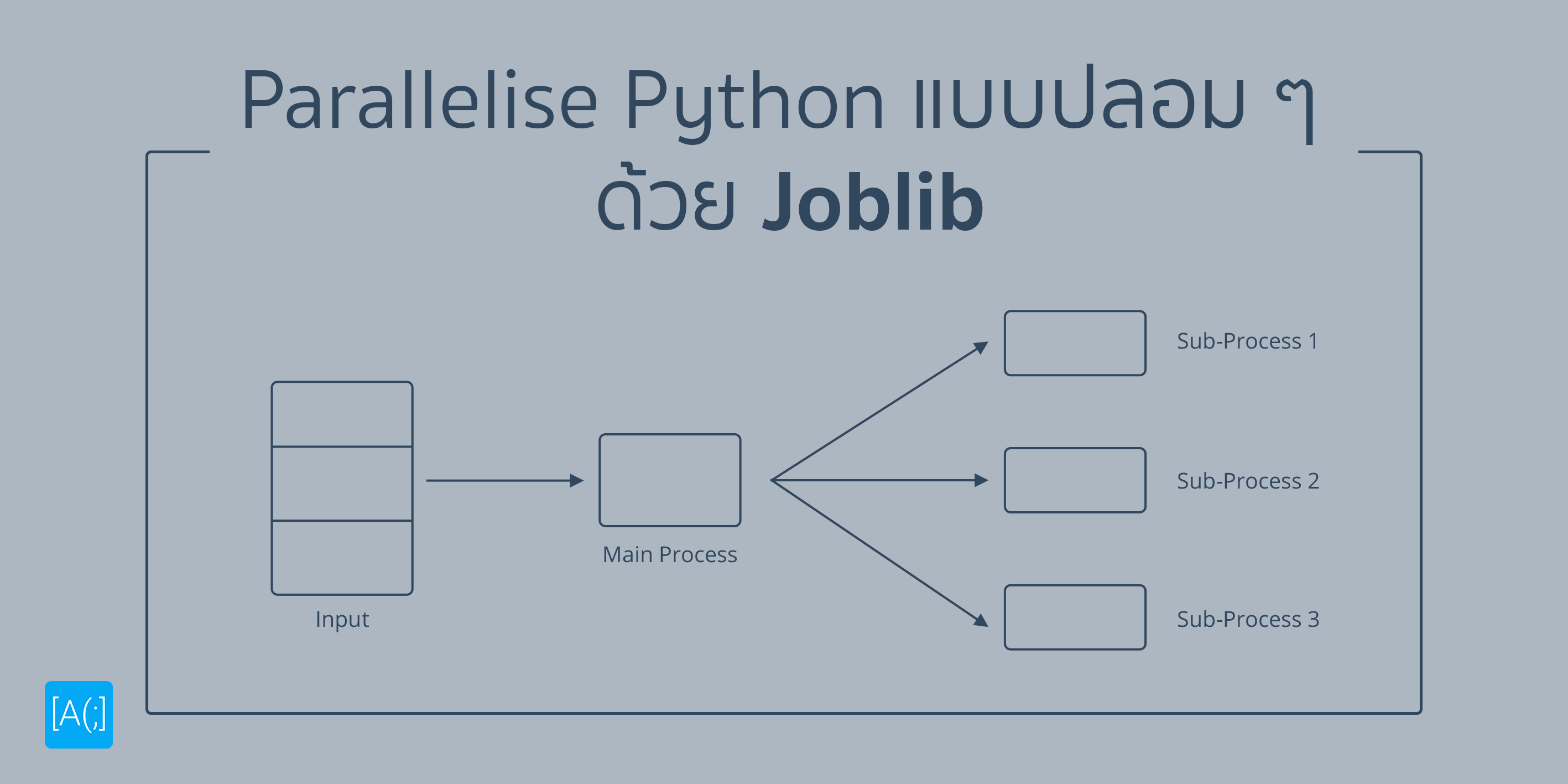
อย่างที่เราบอกปัญหาของ GIL มันคือการแย่ง Interpreter สิ่งที่เรารู้จากพฤติกรรมของ Python คือยังไง ๆ เราก็ Spawn Interpreter ขึ้นมาเองไม่ได้ มันมาพร้อมกับ Process ของ Python เลย งั้นทำไมเราไม่ Spawn Python หลาย ๆ Process มันซะเลยละ เท่านี้เราก็สามารถ Parallelise งานของเราได้แล้วไง โดยที่ทุก Process ไม่ตรบตีแย่ง รอให้ GIL ปล่อยให้คนใดคนนึงทำงาน
ฟิลเหมือนกับละครหลังข่าวที่ตบแย่งผู้ชายกัน สิ่งที่เราทำก็คือ เราก็หาผู้ชายใหม่มาให้ผู้หญิงที่เหลือ เพื่อให้ทุกคนมีคู่และจบแบบ Happy Ending นั่นเอง
ใช่แล้ว สิ่งที่ Joblib ทำคือมันก็แตกตัวเองออกมาหลาย ๆ Process ไปซะเลย ถ้าเราลองรัน Parallel โดยใช้ Joblib แล้วลองดู Process ที่กำลังทำงานเราจะเห็น Python ขึ้นมาเพียบเลย นั่นแหละคือ Joblib มันสร้างขึ้นมาและกระจายงานไปให้
ทีนี้ปัญหาคือ แล้วแต่ละ Process มันจะคุยกันยังไง เพราะเวลาเราเขียนโปรแกรมที่ Parallel ปกติแล้ว แต่ละ Thread มันต้องคุยกันได้ ส่งข้อมูลไปกลับได้ อันนี้จะทำยังไงดี
ย้อนกลับไปที่ Feature ที่สามารถ Serialise ตัวแปรได้ ใช่แล้ว เวลามันทำงาน คือ เมื่อมันแบ่งงานไปในแต่ละ Process มันจะยัดทุกอย่างแล้ว Serialise กลับมาที่ Process หลัก สุดท้าย มันก็จะกลับมาเป็นผลลัพธ์ใน Process หลักนั่นเอง
นั่นทำให้ เวลามันทำงาน มันไม่สามารถเข้าไปแก้ไขค่าของ Process อื่นได้ ซึ่งมันทำให้การเขียนโปรแกรมของเราทำได้เรียบง่ายขึ้น ไม่ต้องมากังวลเรื่องที่เราอาจจะไปเปลี่ยนแปลงค่าใน process หลัก และ ทำให้พฤติกรรมของโปรแกรมมันมั่วไปหมดได้
ดังนั้นถ้าเราลองวาด Process ของการทำงานดี ๆ มันก็เหมือนกับ เราให้ Process หลักแตก Process ย่อย ๆ ออกมาเพื่อทำงานในแต่ละงานที่เรากำหนดลงไป และ ให้แต่ละ Process ย่อยมันทำงานเสร็จ และ Serialise ผลลัพธ์กลับมาให้ Process หลัก และ คืนกลับมาเป็นตัวแปรที่เราสามารถเข้าถึง และ ใช้งานได้ใน Process หลักนั่นเอง
แล้วมันต่างจากการเขียนโปรแกรมแบบ Parallel ที่ใช้ Thread ยังไง
อย่างที่เราบอกว่า Joblib มันใช้การแยก Process ในการ Parallel โปรแกรมของเรา ข้อดีคือ มันทำให้เราสามารถรัน Script ของเราแบบ Parallel ได้จริง ๆ แต่นั่นก็มาพร้อมกับข้อเสียเลย นั่นคือ มันมี Overhead การทำงานที่เยอะมาก ๆ เพราะ มันต้องสร้าง Process ของ Python ขึ้นมาหลาย ๆ ตัว
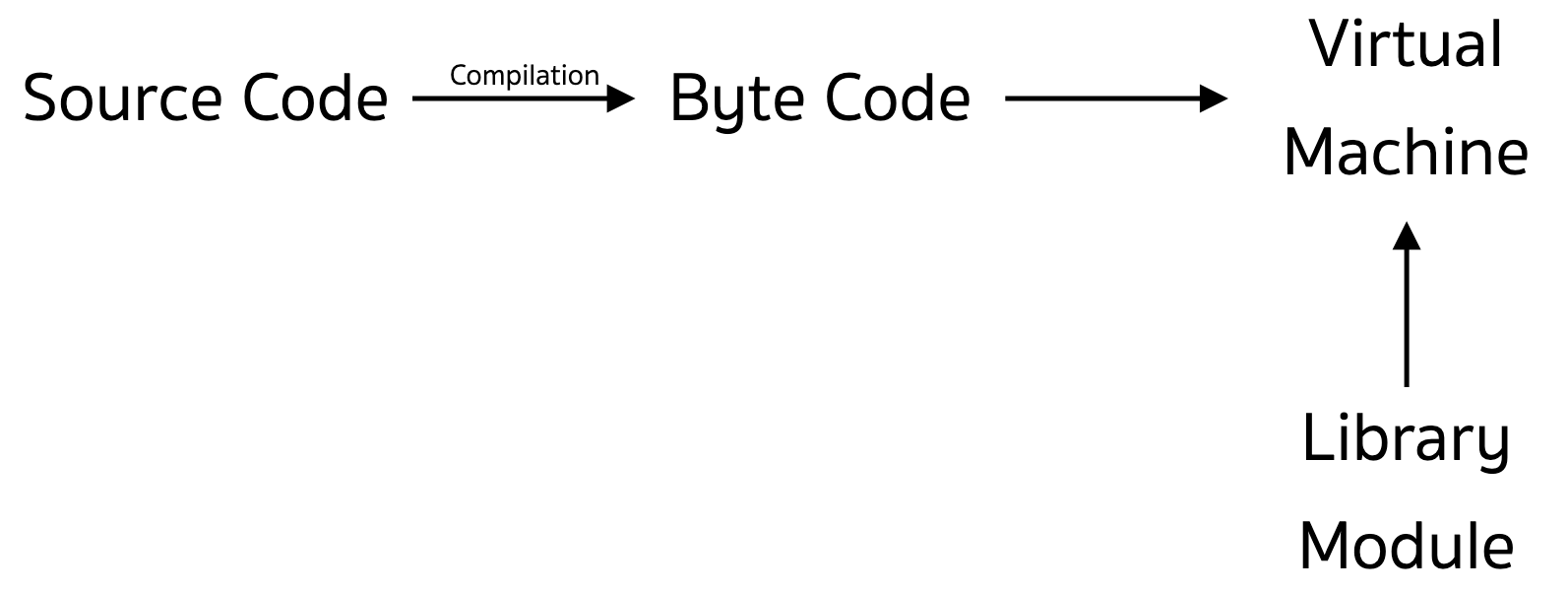
แต่ละ Process ของ Python มันก็มาพร้อมกับพวก Python Virtual Machine และ ตัว Translator ตามการทำงานของมัน นั่นแปลว่า เราจะมีเจ้าพวกนี้เปิดขึ้นมาเต็มไปหมด กิน RAM แน่ ๆ ละส่วนนึง ยิ่งเราเปิดหลาย ๆ Process มากขึ้น มันก็กินเข้าไปเรื่อย ๆ เช่นกัน ดังนั้น เรื่องของการกินทรัพยากร เลยเป็นเรื่องที่น่าปวดหัวมาก ๆ ถ้าต้องการทำงานกับข้อมูลที่ขนาดใหญ่มาก ๆ เราแนะนำให้ไปทำในภาษาอื่นเช่น Go เถอะ น่ารักกว่าเยอะ
ปัญหาที่เราเจอมาคือ เวลาเรากด Control + C เพื่อหยุดรัน Process หลักมันหยุดรันจริง แต่บางที Process ที่ Joblib มันสร้างขึ้นมา มันไม่หยุดด้วยอะสิ ทำให้เราต้องไปไล่ Kill Process ที่ค้างอยู่ออก
ลองเขียนกันเลย
Joblib ไม่ใช่ Standard Library ทำให้เราต้อง Install ก่อนใช้งาน อันนี้แล้วแต่เลยว่า แต่ละคนใช้ Package Manager อะไรกันบ้าง สำหรับเรา เราใช้ pip ก็สามารถ Install ได้จากคำสั่งด้านล่างนี้เลย
pip install joblibเท่านี้ เราก็จะได้ Joblib มาใช้งานเรียบร้อยแล้ว ในการเรียกใช้งาน Parallel Processing ของ Joblib เราสามารถเรียกผ่าน Function ที่ชื่อว่า Parallel ได้เลย เริ่มจากการ Import เข้ามาใน Script ของเรา
from joblib import Parallel, delayedจากนั้นเราสามารถที่จะเรียกสำสั่ง Parallel ได้เลย โดยใช้คำสั่งตามด้านล่างนี้
result = Parallel(n_jobs=1)(
delayed(factorial)(i)
for i in range(1,20)
)สิ่งที่ Parallel รับเข้าไปคือ จำนวน Process ที่ต้องการแตกออกมา ที่อยู่ใน n_jobs โดยที่ถ้าเราอยากให้มันทำงานในทุก Core ของ CPU เราเลย เราสามารถกำหนดเป็น -1 ได้
และในอีกวงเล็บ เราก็จะ Pass Function เข้าไป ในที่นี้คือ factorial และเราต้องการให้มันหาตั้งแต่ 1! ถึง 20! โดยการป้อน i เข้าไป ซึ่ง i เราก็จะไล่ตั้งแต่ 1-20 นั่นเอง เวลามันทำงาน มันก็จะเอา factorial(1) ถึง factoral(19) ไปแบ่งตาม Process และทำงานไปเรื่อย ๆ จนเสร็จ แต่ถ้าเราไม่ใส่ delayed มันก็น่าจะเป็นแบบด้านล่าง
Parallel(n_jobs=-1)(factorial(i) for i in range(1,20))เราลองคิดดี ๆ นะ สิ่งที่มันน่าจะทำคือ มันก็จะ Invoke factorial ทีละตัวไปเรื่อย ๆ ตั้งแต่ i เป็น 1 ถึง 19 เลย แล้ว Parallel มันก็จะไม่ได้รับ Function อะไรเข้าไปเลย แล้วเราจะ Parallel ทำไมใช่ม่ะ ฮ่า ๆ
[(factorial, [1], {}), (factorial, [2], {}), ... , (factorial, [19], {})]สิ่งที่เราต้องการคือ การ Pass Function พร้อมกับ Argument แล้วไป Invoke ในแต่ละ Process ทำให้เราต้องใส่ delayed เข้ามามันจะรันออกมาเป็น Tuple เพื่อฟีทให้ Parallel เอาไปกระจายออกเป็น Process ต่อไปนั่นเอง ทำให้ เราจะบอกว่า เวลาใช้งาน Parallel ทุกครั้งอย่าลืมใส่ delayed ลงไปด้วย ไม่งั้น เราก็รันแบบปกตินี่แหละ ไม่ได้ช่วยให้เร็วขึ้นเลย แล้วจะงงกันเลยทีนี้ทำไมมันเป็นแบบนั้น ฮ่า ๆ
โดย Default แล้วการทำงานของ Parallel มันจะใช้การแตก Process ออกไปเหมือนที่เราเล่าไป แต่ถ้าเราอยากจะใช้ Threading แบบปกติที่ติด GIL ก็ย่อมทำได้เช่นกัน โดยการกำหนด backend='threading' ลงไปใน Parallel ได้ด้วย
อย่างที่เราบอกว่า เวลามันทำงานสุดท้าย มันจะเอาค่าจาก Process ที่แตกออกมาไปมา Serialise แล้วยัดกลับมาให้ Process หลัก ตัว Parallel มันจะ Result ค่าเหล่านั้นกลับมาเป็น List ให้เราใช้งานต่อได้เลย ถือว่าสะดวกในการทำงานมาก ๆ
สรุป : Parallel ใน Joblib ทำให้เรารันแบบ Parallel ได้จริง ๆ แต่ Overhead เยอะมาก
Parallel ที่เป็นส่วนนึงของ Joblib ช่วยให้โปรแกรมเราทำงานแบบ Parallel โดยที่ไม่ติด GIL ได้จริง ด้วยการเปลี่ยนวิธีการทำงานจากการแบ่ง Thread เป็นการแบ่ง Process และ Serialise ผลลัพธ์กลับมาที่ Process หลัก แต่ก็แลกมาด้วย Overhead ที่สูง เราแนะนำว่า ถ้าเราต้อง Parallelise เยอะมาก ๆ เข้า เราจะไปใช้ภาษาอื่นดีกว่า เช่น Go เป็นต้น
Bonus: ปัญหาการอ่านไฟล์
ปัญหาการอ่านไฟล์ที่เราเล่าไปในตอนต้นของบทความ เราใช้ Parallel แก้ปัญหาง่าย ๆ เลย เรารู้ว่า เวลามันอ่านไฟล์มันจะมีสิ่งนึงที่เรียกว่า Cursor อยู่ เหมือนเวลาเราพิมพ์งานใน Word Processing ต่าง ๆ มันก็คือ ตำแหน่งของไฟล์ที่เราอยู่ นั่นเอง
การที่เราเรียก some_file.readline() มันก็คือ การอ่านไปเรื่อย ๆ ทีละตัวจนมันเจอ New Line Character นั่นเอง ถ้าเราเข้าไปดูไส้ในของมันก็คือ read() ดี ๆ นั่นแหละ เวลาเราอ่านพวกนี้ Cursor มันก็จะเลื่อนไปเรื่อย ๆ โดยที่เราสามารถถามหาตำแหน่งของ Cursor ได้โดยใช้คำสั่ง some_file.tell() มันจะคืนค่ากลับมาเป็นตำแหน่งของ Cursor และเรายังสามารถที่จะเลื่อน Cursor ไปมาได้ด้วยคำสั่ง some_file.seek(position)
เราใช้ความรู้เรื่องพวกนี้ คู่กับ Parallel ใน Joblib ทำให้เราได้ Solution แบบง่าย ๆ คือเราแบ่งไฟล์ออกเป็น Chunk แต่แทนที่เราจะแบ่งไฟล์ออกมาเป็นไฟล์จริง ๆ ซึ่งมันช้า เราใช้วิธีคล้าย ๆ กับการทำ Pointer ชี้ไปที่ไฟล์ เราก็ชี้ด้วยตำแหน่งของ Cursor แทน และ กำหนดขนาดของ Chunk เข้าไป นั่นแปลว่า แต่ละ Process มันก็จะทำงานตั้งแต่ตำแหน่งที่ป้อนเข้ามา ถึง ตำแหน่งที่ป้อนเข้ามาบวกด้วยขนาดของ Chunk นั่นเอง
ปัญหาคือ ถ้า Chunk ที่เราแบ่งไปมันเกิดขนาดของไฟล์มันก็จะ Infinity Loop หมุน ๆ ไปเรื่อย ๆ เพราะ ถ้ามันอ่านเลยตำแหน่งที่ไฟล์มี มันจะให้ String เปล่าออกมา เราก็แค่เช็คว่า ถ้ามันเจอ String เปล่า ก็ให้มันตัดจบแล้ว Return กลับไปที่ Process หลักเลย
Related Posts

วิธีการและเทคนิคการ Capture เรื่องราวด้วย Obsidian
01 พฤษภาคม 2026 - 2 min readหนึ่งขั้นตอน Workflow ของ PKM ที่เป็นเหมือนการนำเข้าวัตถุดิบมาปรุงเป็นไอเดียดี ๆ ในอนาคต คือ การ Capture สิ่งที่เราได้เรียนรู้ หรือได้รับฟัง ดู อ่าน เข้ามา วันนี้เราจะมาเล่าวิธีการที่เราใช้กับ Obsidian กันว่า เราทำอย่างไร เพื่อให้ Workflow นี้ง่าย และเหมาะกับการใช้งานของเราที่สุด...

สร้าง WebAssembly Module แรกกันเถอะ
21 เมษายน 2026 - 2 min readจากบทความที่แล้ว ที่มาแนะนำ WebAssembly ไปว่า มันเป็นอะไรที่ค่อนข้างน่าสนใจ และน่าเรียนรู้เอาไว้มาก ๆ วันนี้เราจะมาพาทุกคนไปสร้าง WebAssembly Module แรกกัน และเทียบกันไปเลยว่า Performance ในงานที่ CPU Bound มาก ๆ มันจะห่างกันขนาดไหน...

Self-Hosted Service บน Home Lab จัดการอย่างไรให้ปลอดภัย
16 เมษายน 2026 - 3 min readช่วงหลัง ๆ กระแสการทำ Home Lab ฮิตขึ้นมาก ๆ ในประเทศไทยเรา มีคนถามเข้ามาเยอะมากว่า แล้วเราจะจัดการอย่างไรให้ระบบของเราปลอดภัยมากที่สุด วันนี้เราจะมารวบรวมวิธีคิดการวางสถาปัตยกรรมแบบ Defense-in-Depth สำหรับงาน Self-Hosting ง่าย ๆ กัน...

Functional Programming คืออะไร ? ทำไมมันถึงเป็นเรื่องที่น่าสนใจในยุคใหม่
11 เมษายน 2026 - 2 min readก่อนหน้านี้ไม่ค่อยได้สนใจการเอา Functional Programming มาใช้ในงานเท่าไหร่ แต่พอได้ลิ้มรสเท่านั้นแหละ มันเหมือนโลกใหม่มาก ๆ เข้ามาแก้ปัญหาหลาย ๆ อย่างที่เคยได้เจอมา วันนี้เราจะมาเล่ากันว่า มันคืออะไร และ มันน่าจะเหมาะกับงานไหนกัน...