Deep Learning ดีกว่า Traditional Machine Learning จริงเหรอ
By Arnon Puitrakul - 21 พฤษภาคม 2019
เมื่อหลาย ๆ ปีที่ผ่านมา นานมาละ คำว่า Machine Learning ก็บูมขึ้นมาจนกลายเป็น Buzz Word ถูกนำไปใช้อย่างแพร่หลาย จนใครไม่มีคำว่า Machine Learning ก็คือขายไม่ออกกันเลยทีเดียว (ถ้าไปเดิน Startup เดี๋ยวนี้ Keyword ที่มันต้องมี และได้ยินบ่อยโคตร ๆ เลยคือประโยคประมาณว่า "เราใช้ Machine Learning เพื่อ....." เยอะมากกกก) และเมื่อไม่กี่ปีที่ผ่านมา คำว่า Deep Learning ก็เข้ามาเป็นอีกหนึ่ง Buzz Word ในแวดวงอีก ทำให้วันนี้เราเลยอยากที่จะมาอธิบายว่า จริง ๆ แล้ว Deep Learning คืออะไร และจริงเหรอ ที่มันดีกว่า Traditional Machine Learning
Traditional Machine Learning
Traditional Machine Learning หรือบางคนก็เรียกมันว่า Classical Machine Learning เอาเป็นว่า แล้วแต่จะเรียกละกัน มันเป็นวิธีในการสอนเครื่องให้ทำอะไรได้สักอย่างโดยที่เราไม่ต้องไปโปรแกรมบอกมัน ซึ่งสิ่งที่เราใช้เก็บวิธีเหล่านั้น เราเรียกมันว่า Model
หลัก ๆ ทั่วไปแล้ว Model ที่เรากำลังพูดถึงมันก็คือ Mathematical Model หรือ โมเดลทางคณิตศาสตร์ นั่นเอง ที่เราอาจจะใช้เรื่องพวก Regression ต่าง ๆ อย่าง Linear Regression และ Logistic Regression หรือจะเป็นการ Clustering อย่าง k-means และ KKN ในการสร้าง Model
นั่นทำให้ กระบวนการกว่าที่เราจะได้ Model นั้นมาคือ การที่เรามี Data แล้วก็เอาไปทำ Feature Extraction หรือก็คือ กระบวนการแปลงข้อมูลดิบให้อยู่ในรูปแบบที่เราต้องการให้เครื่องเอาไปใช้เรียน เช่น ถ้าเราอยากจะแยก หมา และ แมว ออกจากกัน เราอาจจะต้องมานั่งหาว่า แล้วหมา กับ แมว มีอะไรที่แตกต่างกันละ แล้วก็ค่อยใช้ข้อแตกต่างเหล่านั้น ให้เครื่องเอาไปเรียนรู้นั่นเอง
ยิ่งเรารู้ Background Knowledge ของเรื่องที่เราจะต้องทำงานได้เท่าไหร่ Model ของเราก็จะออกมาได้ดีขึ้นเท่านั้น เพราะ บาง Feature ที่เรา Extract มา มันก็อาจไม่สำคัญทุกอันก็ได้ ทำให้มันอาจจะต้องมีขั้นตอนอย่าง Feature Selection และ Feature Engineering หรือ Feature อื่น ๆ เข้ามาเกี่ยวข้องมากมาย ซึ่งแน่นอนว่า มันก็ต้องใช้แรงงานคน และเวลามากมายในการทำอะไรแบบนี้นั่นเอง
Deep Learning
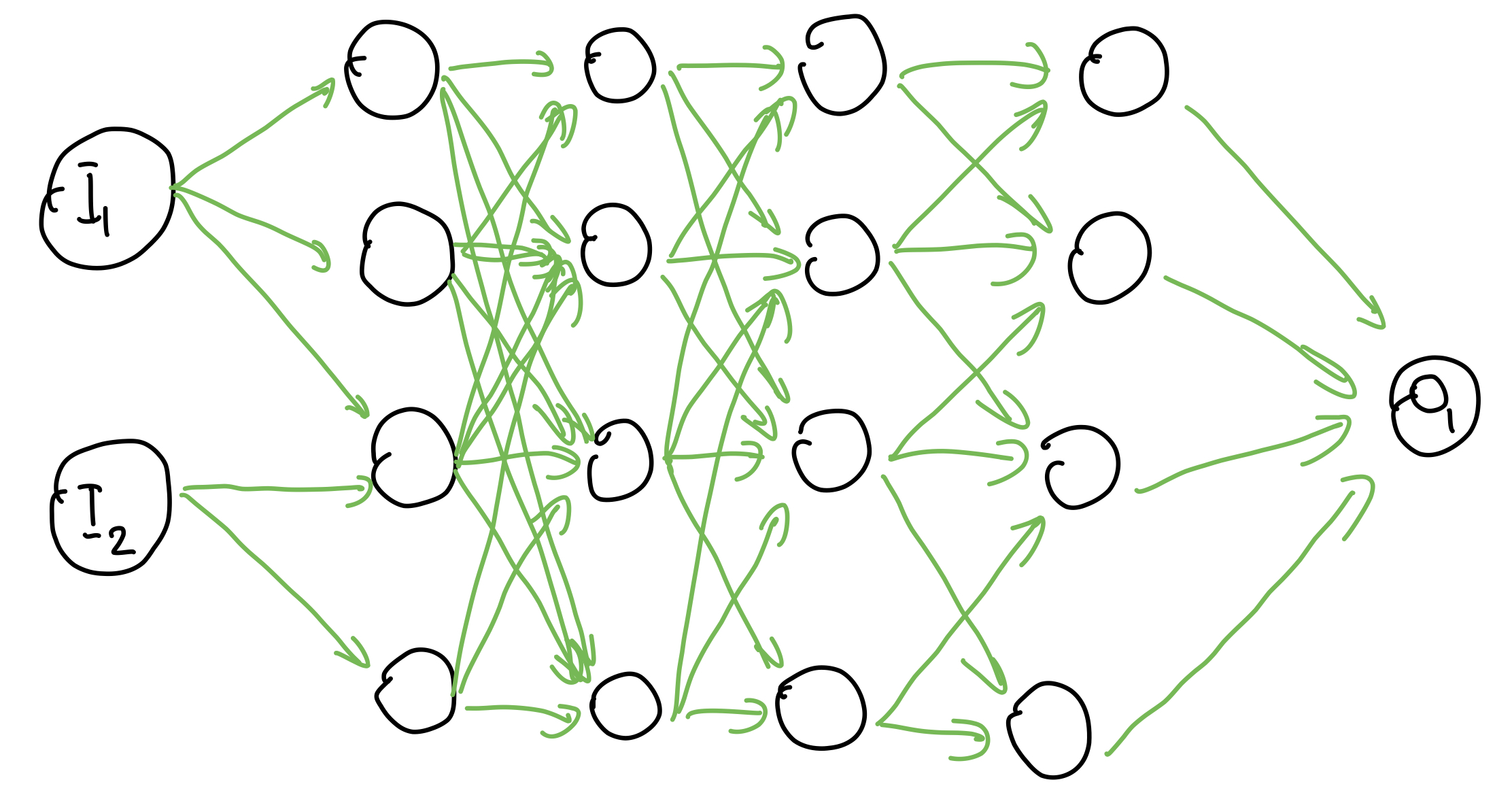
Deep Learning เป็นอีกวิธีนึงที่มาบูมระเบิดเถิดเทิงในช่วงไม่กี่ปีที่ผ่านมา เพราะ Data ที่มีจำนวนมากขึ้น และ ความสามารถในการประมวลผลสูงขึ้นเรื่อย ๆ แต่สุดท้ายแล้ว จริง ๆ มันก็คือ Machine Learning แบบนึงนั่นแหละ
แต่เมื่อเราพูดถึง Deep Learning เราพูดถึงการใช้ Deep Artificial Neural Networks ในการทำ Machine Learning นั่นเอง สาเหตุที่มันเกิดบูมระเบิดเถิดเทิงขึ้นมาก็เพราะ ตัวมันสามารถที่จะแก้ปัญหาที่มีความซับซ้อนได้ดีมาก ๆ ที่เอามาใช้กันเยอะ ๆ และเราเห็นได้ทั่วไปเลยคือ การทำ Image Recognition และ Natural Language Processing (NLP)
Artificial Neural Networks (ANN) มันเลียนแบบมาจากสมองของคนเรานี่แหละ ที่มีเซลล์ประสาทวิ่งส่งข้อมูลไปมาเต็มไปหมด ใน ANN เองก็เอาหลักการนี้มาใช้ โดยการซ้อน Node ที่เหมือนกับเซลล์ประสาท และเชื่อมต่อกันไปเรื่อย ๆ จนออกมาเป็น Network อันนึง ที่มีความสามารถในการทำงานอะไรสักอย่าง เช่น Classification ได้ (เราไม่ลงรายละเอียดว่าทำไมถึงทำได้ และทำยังไงนะ เดี๋ยวจะยาว ไว้ค่อยมาเล่าในบทความต่อ ๆ ไปละกัน)
เมื่อกี้เราพูดถึงคำว่า ANN ไปแล้ว ตกคำว่า Deep คำนึง อ่าาห์ อันนี้ก็เป็น Key สำคัญเหมือนกันที่ทำให้ Deep Learning มันเก่งได้ขนาดนี้ ก่อนอื่นเราต้องอธิบายก่อนว่า โครงสร้างของ ANN เวลาเราพูดว่า เราทำ Deep Learning มันมักจะประกอบด้วย 3 ส่วน คือ Input, Hidden และ Output Layer
Input และ Output ชื่อมันก็บอกอยู่แล้วละว่า มันคือ ทางที่เราเสียบข้อมูลเข้า และ ออกนั่นเอง แต่สิ่งที่น่าสนใจคือ Hidden Layer เมื่อเราบอกว่า เราทำ Deep ANN มันหมายความว่า เราใช้จำนวนของ Hidden Layer ใน Model ของเราเยอะมาก เพื่อที่จะทำให้เครื่องมันเข้าใจข้อมูลของเราได้ดีขึ้น
วิธีการของมันก็คือ Hidden Layer แรก ๆ มันจะเรียนรู้ Feature หรือ ลักษณะที่ง่ายที่สุดเช่น ถ้าเราใส่รูปภาพเข้าไป มันอาจจะไปเข้าใจเรื่องของเส้น แสง และขอบภาพต่าง ๆ พอไปใน Hidden Layer ที่ลึกเข้าไปหน่อย ก็อาจจะเป็น การวาดโครงหน้า และหลัง ๆ ก็จะเป็นเรื่องของการ วาดส่วนประกอบบนใบหน้าอะไรแบบนั้น และสุดท้ายมันก็ออกมาเป็น Facial Recognition
แต่ด้วย Layer ที่มหาศาลขนาดนี้ การคำนวณต่าง ๆ ย่อมต้องเยอะเป็นเงาตามตัวอยู่แล้ว ทำให้คนชอบพูดกันว่า การทำ Deep Learning ต้องใช้เครื่องแรง ๆ นี่แหละเหตุผล ยิ่งจำนวน Layer เยอะ เครื่องที่ใช้ก็ต้องมีประสิทธิภาพที่สูงตาม อีกอันที่น่าสนใจคือ การใช้ GPU (หรือที่เราเรียกกันว่า การ์ดจอ นั่นแหละ) เข้ามาช่วยในการประมวลผล
GPU ข้อดีของมันคือ มีจำนวนแกนประมวลผล หรือ Core เยอะกว่า CPU หลายขุม ถ้าเป็น CPU ที่เราใช้กันตามบ้านเลย ก็น่าจะมีสัก 4 Core 8 Threads ใช่ม่ะ แต่ถ้าเป็น GPU เรากำลังพูดถึงหลักพัน Core เลย (อย่าง Nvidia Geforce RTS 2080 ก็โดนไป 2944 Cuda Core)
หูยยย อย่างงี้เราก็ไม่ต้องใช้ CPU ก็ได้สิ GPU มันต่างกันขนาดนี้ คำตอบคือ ไม่ได้ !! เพราะ มันออกแบบมาใช้งานต่างกัน CPU อาจจะมีจำนวนหัวน้อยกว่า แต่ CPU มันออกแบบมาให้มีชุดคำสั่งที่ทำงานยาก ๆ ได้ดีกว่า GPU หลายขุมมาก ในขณะที่แกนประมวลผลของ GPU ถูกออกแบบมาให้คิดเลขง่าย ๆ ได้เท่านั้น แต่อาศัยความเยอะสู้ เลยทำให้ยังจำเป็นที่ต้องใช้ CPU ในการทำงานส่วนใหญ่อยู่
อันนี้เราเสริมละกัน GPU สาเหตุที่มันต้องออกแบบมาให้มีจำนวน Core เยอะ ๆ แต่คิดเลขไม่ได้พิศดารมาก ลองคิดดูนะว่า เวลาเราเล่นเกมสักฉาก ในฉากนั้นมันมีของอยู่กี่ชิ้น แล้วเวลาเราเล่นเกม ของในฉากพวกนั้นมันก็ขยับเพราะแรงลม แสงอาจจะเปลี่ยนเพราะเราเดินแล้วเกิดเงา และเกมปกติเราเล่นก็ 60 FPS ก็คือ 1 วินาที เครื่องมันต้องประมวลผลทั้งหมด 60 Frame ถือว่าเป็นงานที่เหี้ยมมากงานนึงเลยนะ CPU ที่มีสัก 8 Core ก็ไม่น่าเอาอยู่
เราจะเห็นว่า งานขนาดนี้ การใช้จำนวน Core น้อยอาจจะไม่ใช่ทางออก ทำให้ GPU ที่ถูกออกแบบมาเพื่องานประเภทนี้โดยเฉพาะต้องแก้ปัญหาด้วยการเติม Core เข้าไปเยอะ ๆ เพื่อแก้ปัญหานี้ แต่ ๆๆๆ การเพิ่ม Core เข้าไปเฉย ๆ มันเป็นเรื่องที่ยากมาก ไม่งั้น CPU ตัวนึงก็มีพัน Core ไปแล้วสิ
ถ้าเราลองสังเกตดี ๆ งานส่วนใหญ่ที่ GPU ทำมันจะเป็นงานเดิม ๆ อย่างการประมวลผลภาพต่าง ๆ การคำนวณแสงเงาอะไรแบบนั้นทั้งหมดเลย ไม่ได้มีงานแปลก ๆ อะไรเลย อย่างการจัดการงานที่ซับซ้อนอย่าง CPU อื้มมม งั้นเราน่าจะเอาความสามารถในการทำงานแบบซับซ้อนที่การประมวลผลรูปภาพและวีดีโอใช้ออกละกัน ทำให้เราสามารถออกแบบ Core ของ GPU ให้ทำงานเฉพาะทางมากกว่า CPU นั่นทำให้ เราสามารถยัด GPU Core ได้เป็นพัน ๆ Core ลงได้ไปนั่นเอง
งานที่ GPU มันก็คือ เกิดมาเพื่อคำนวณล้วน ๆ (เพราะ CPU จัดการ IO และ เรื่องอื่น ๆ ให้หมดแล้ว) คำนวณในเรื่องเดิม ๆ ด้วยนะ อย่าง Video Encoding, Video Decoding, Linear Algebra อะไรแบบนั้น
ย้อนกลับไปที่ว่า เมื่อเราพูดถึง Deep Learning มันคือ การที่เราใช้ ANN ด้วยจำนวน Layer ที่เยอะมาก ๆ ใช่ม่ะ ในแต่ละ Layer มันก็จะมี Node ซึ่งแต่ละ Node มันทำงานเหมือนกับกล่องที่ เราเอาของเข้า แล้วคำนวณอะไรบางอย่าง แล้วให้ผลลัพธ์ออกมา พอจะมองเห็นภาพมั้ย
แต่ละ Node มันก็จะคำนวณแยกออกจากกันหมด เพียงแค่รอรับค่าจาก Node ก่อนหน้า ทำให้เราสามารถใช้ Core เยอะ ๆ ในการคำนวณได้ สบาย ๆ เลยหละ นั่นแหละคือเหตุผลที่ทำให้ GPU มันเหมาะกับการทำ Deep Learning เป็นอย่างมาก
สิ่งที่เราว่ามันเป็นข้อดีของ Deep Learning คือ เราไม่จำเป็นต้องมานั่งเลือก Feature หรือทำอะไรกับ Feature เพราะสุดท้ายเมื่อมันเข้าไปในสร้าง ANN อะไรนั่นแล้ว มันก็จะเปลี่ยน Weight หรือ ความสำคัญให้ในนั้นเอง มันก็เหมือนกับการทำ Feature Selection นั่นเอง
เพราะปัญหาของ Feature Selection ก็คือ เราจะเลือกอะไรมาใส่หละทีนี้ มันก็ต้องอาศัยความรู้ที่เรามีเกี่ยวกับเรื่องนั้น ๆ ก่อนใช่ม่ะ ว่าถ้าเป็นเรา เราจะใช้อะไรในการแยก หรือ แบ่งกลุ่ม ของตรงนี้ออกจากกัน ปัญหาคือ แล้วถ้าเราไม่รู้อะไรเลย อย่างวันนึงเราไม่รู้ข้อมูลพวก Trend เรื่องหุ้นมาก่อนเลย แล้วต้องมา Predict ว่าหุ้นนี้ดีหรือไม่ เราก็จะเลือก Feature ได้ยากมาก วิธีนึงที่น่าจะพอทำได้คือ การใช้ความรู้ทางสถิติ (สถิติ !== คณิตศาสตร์) ในการประมาณว่า Feature ไหนน่าสนใจ แล้วก็จิ้มลงมาใน Model เลย หรือปัญหาที่มีความซับซ้อนมาก ๆ การเลือก Feature ก็อาจจะทำให้เรากลายเป็นหิน นั่งอึนอยู่นานก็เป็นได้นะ
ดังนั้นการทำ Deep Learning มันเลยมีข้อดีอันนึงที่เราชอบมากเมื่อเราไม่มีความรู้ใน Domain นั้น ๆ เลย การลองด้วยการโยนลงไปใน Deep Learning Model เลยเป็นอะไรที่น่าลองเหมือนกัน แต่ด้วยความที่มันเป็นแบบนั้นแหละ มันเลยทำให้เราตีความ และทำความเข้าใจ Model ได้ยากขึ้นเหมือนกัน
จริงเหรอที่ Deep Learning ดีกว่า Machine Learning ทั่ว ๆ ไป
ถ้าขี้เกียจอ่านต่อ เราก็บอกตรงนี้เลยว่า ถ้าเอาความคิดเห็นเรา มันไม่มีอะไรดีกว่าใครหรอก เพราะถ้ามันเป็นแบบนั้นจริง Machine Learning มันก็หายไปแล้วใช่ม่ะ แต่ที่มันก็ยังคงได้รับความนิยมอยู่ ก็เพราะต่างคนต่างมีข้อดีของมันไงละ
เรื่องแรกอย่างจำนวนข้อมูล ถ้าเรามีจำนวนข้อมูลเยอะ ๆ อันนี้ Deep Learning อาจจะได้เปรียบเลยนะ ยิ่งทำให้ Model ดีขึ้นมาก ๆ เพราะมันได้เห็นข้อมูลจำนวนมาก กลับกันถ้าเป็น Machine Learning ทั่ว ๆ ไป การเพิ่มข้อมูลเข้าไปมันก็ทำให้ Model ดีขึ้นจริง ๆ แหละ แต่เมื่อเราลองเพิ่มขึ้นไปเรื่อย ๆ มันก็ดีขึ้นเรื่อย ๆ แต่พอถึงจุดนึงมันก็เหมือนเริ่มอิ่มตัว ทำให้การเก็บข้อมูลเพิ่มก็อาจจะดูไม่คุ้มค่าอีกแล้ว บางทีจุดนึงเราเพิ่มไป 1000 Record Performance มันก็ไม่ได้เพิ่มขึ้นเยอะเท่าไหร่เลย ซึ่งจุดที่มันอิ่มตัวอะไรนั่น มันก็ไม่ได้มี Best Practice อะไรขนาดนั้น นอกจาก เราต้องลองลดหรือเพิ่มขนาดของข้อมูล (โดยข้อมูลที่ลดและเพิ่มต้องถูก Random ก่อนแล้วค่อยตัดออกนะ) ดูว่า มันมีผลอย่างไรต่อ Model บ้าง
เรื่องถัดไปคือ เรื่องของเครื่องคอมพิวเตอร์ที่เอามาใช้ในการทำงาน ต้องบอกเลยว่า อันนี้หลาย ๆ คนน่าจะพอรู้มากบ้างแหละ ว่าการทำ Deep Learning เนี่ย มันกินเครื่องหนักมาก ๆ ยิ่ง Library เดี๋ยวนี้ก็มีความนิยมในการใช้ GPU มากขึ้นเรื่อย ๆ ในขณะที่ เครื่องคอมพิวเตอร์ในตอนนี้หลาย ๆ เครื่องที่ราคาแพงมักจะไม่ได้มาพร้อมกับ GPU เพราะ Integrated GPU ในปัจจุบัน มันมีประสิทธิภาพมากพอที่จะทำงานทั่ว ๆ ไปได้แล้ว ดังนั้น ถ้าจะทำงานพวกนี้ การมีการ์ดจอก็
และเรื่องสุดท้าย คือความน่าปวดหัวของ Model ถ้าเป็น Machine Learning ทั่ว ๆ ไป เราก็จะเริ่มจาก Feature แล้วเอาไปสร้าง Model ผ่าน Model แต่ละแบบอะไรก็ว่ากันไป นั่นทำให้สิ่งที่เราอาจจะเปลี่ยนแปลงเพื่อทำให้ Fitness ของ Model ดีขึ้นจะทำได้ 3 อย่างคือ การเพิ่มลด หรือสร้าง Feature ใหม่, เปลี่ยน Model และ การปรับจูน Hyperparameter ต่าง ๆ นั่นทำให้การ Optimise Model ทำได้ค่อนข้างตรงไปตรงมา ไม่น่าปวดหัวเท่าไหร่ กลับกัน ถ้าเป็น Deep Learning มันจะกลายเป็นอีกเรื่องไปเลย ไส้ในของมันค่อนข้างที่จะอยู่ในความมืดสุด ๆ บางทีเราไม่รู้เลยว่า ส่วนนี้มันมีอยู่ หรือไม่ก็ ส่วนนี้จริง ๆ แล้วมันทำอะไร หรือแม้กระทั่งการปรับจูน Hyperparameter ก็เป็นเรื่องที่ค่อนข้างยากเช่นกัน
เมื่อไหร่เราควรใช้อะไร
สำหรับเรา การที่อยู่ ๆ จะโยนเข้าไปใน Deep Learning เลย มันก็ดูจะไร้ความรับผิดชอบไปซะหน่อย การเลือก Model ที่มีความเหมาะสมกับข้อมูลเป็นเรื่องที่สำคัญมาก บางทีใช้ Model ที่ซับซ้อนมาก ๆ อาจจะไม่ได้ให้ผลดีเท่ากับ Model ที่เรียบง่ายอีกนะ ถ้าเราทำให้มันดี
ปัญหาที่ซับซ้อนมาก ๆ ก็อาจจะเหมาะกับ Deep Learning อย่างพวก ปัญหาเกี่ยวกับรูปภาพ เสียง และ สัญญาณต่าง ๆ ที่การ Extract Feature นั้นทำได้ยาก แต่กลับกัน ถ้ามันเป็น Feature อย่างขนาดของดอก Iris ก็เป็นอีกเรื่องไปเลย ถ้าเราเอา Iris ไปใช้ Deep Learning แล้วเราเอามาเทียบกับ Machine Learning แบบปกติ เราไม่รู้นะว่า Performance มันจะเป็นยังไง แต่อย่างน้อยเวลาในการสร้าง Model น่าจะมากกว่าแน่ ๆ
อาจจะมองว่า แค่นี้ มันไม่ได้สำคัญนะ แต่ลองคิดดูว่า ถ้า Data เรามีขนาดที่ใหญ่มาก ๆ เวลาที่ต่างกันอาจจะต่างกันในระดับวันก็ได้เลยนะ
นอกจากนั้น จำนวนข้อมูล อย่างที่เราบอกว่า Deep Learning มันจะเก่งได้นั้นต้องอาศัยข้อมูลจำนวนมาก กลับกันถ้าเป็น Traditional Machine Learning อาจจะใช้ข้อมูล ที่น้อยกว่า แต่ ต้องอาศัยการเลือกและจัดการ Feature ที่ยุ่งยากกว่า แต่ความเก่งอาจจะมากกว่าก็ได้นะ
จริง ๆ เรามองว่า สาเหตุที่ Deep Learning มันพึ่งมาบูมเมื่อไม่กี่ปีที่ผ่านมาเกิดจาก 2 ส่วนคือ ข้อมูลที่มีมากขึ้นเยอะมาก ๆๆๆๆๆ เพราะคนสามารถเข้าถึง Internet ได้มากขึ้น User Generated Content (UGC) ก็เพิ่มขึ้นเป็นเงาตามตัว และ เครื่องคอมพิวเตอร์ที่มีประสิทธิภาพสูงมากขึ้นพอที่จะรันอะไรแบบนี้ได้
สรุป
การเลือกใช้งานวิธีต่าง ๆ นั้นมีความสำคัญมาก ๆ เพราะถ้าเราโนสนโนแคร์ แล้วกะจะโยนทุกอย่างลง Deep Learning แล้วหวังว่าผลจะดีมันก็ดูจะเป็นอะไรที่ไร้ความรับผิดชอบไปนิดนึงนะ บางที Model ง่าย ๆ อย่าง Linear Regression อาจจะทำงานได้ถูกต้องกว่า เพราะข้อมูลเราดันมีการกระจายตัวแบบนั้นพอดี และก็ย่อมใช้เวลาน้อยกว่า Deep Learning แน่ ๆ ทำให้การเลือกใช้ Model ได้เหมาะสม ก็จะเป็นการลดต้นทุน ในการสร้าง Model เยอะมาก ไม่ว่าจะเป็น ทรัพยากรในการเอาข้อมูลมา เวลาในการวิเคราะห์และสร้างข้อมูล และ ราคาเครื่องที่เอามาใช้
Related Posts

วิธีการและเทคนิคการ Capture เรื่องราวด้วย Obsidian
01 พฤษภาคม 2026 - 2 min readหนึ่งขั้นตอน Workflow ของ PKM ที่เป็นเหมือนการนำเข้าวัตถุดิบมาปรุงเป็นไอเดียดี ๆ ในอนาคต คือ การ Capture สิ่งที่เราได้เรียนรู้ หรือได้รับฟัง ดู อ่าน เข้ามา วันนี้เราจะมาเล่าวิธีการที่เราใช้กับ Obsidian กันว่า เราทำอย่างไร เพื่อให้ Workflow นี้ง่าย และเหมาะกับการใช้งานของเราที่สุด...

สร้าง WebAssembly Module แรกกันเถอะ
21 เมษายน 2026 - 2 min readจากบทความที่แล้ว ที่มาแนะนำ WebAssembly ไปว่า มันเป็นอะไรที่ค่อนข้างน่าสนใจ และน่าเรียนรู้เอาไว้มาก ๆ วันนี้เราจะมาพาทุกคนไปสร้าง WebAssembly Module แรกกัน และเทียบกันไปเลยว่า Performance ในงานที่ CPU Bound มาก ๆ มันจะห่างกันขนาดไหน...

Self-Hosted Service บน Home Lab จัดการอย่างไรให้ปลอดภัย
16 เมษายน 2026 - 3 min readช่วงหลัง ๆ กระแสการทำ Home Lab ฮิตขึ้นมาก ๆ ในประเทศไทยเรา มีคนถามเข้ามาเยอะมากว่า แล้วเราจะจัดการอย่างไรให้ระบบของเราปลอดภัยมากที่สุด วันนี้เราจะมารวบรวมวิธีคิดการวางสถาปัตยกรรมแบบ Defense-in-Depth สำหรับงาน Self-Hosting ง่าย ๆ กัน...

Functional Programming คืออะไร ? ทำไมมันถึงเป็นเรื่องที่น่าสนใจในยุคใหม่
11 เมษายน 2026 - 2 min readก่อนหน้านี้ไม่ค่อยได้สนใจการเอา Functional Programming มาใช้ในงานเท่าไหร่ แต่พอได้ลิ้มรสเท่านั้นแหละ มันเหมือนโลกใหม่มาก ๆ เข้ามาแก้ปัญหาหลาย ๆ อย่างที่เคยได้เจอมา วันนี้เราจะมาเล่ากันว่า มันคืออะไร และ มันน่าจะเหมาะกับงานไหนกัน...