ทำไมการ คูณ Matrix ถึงสำคัญกับ Deep Learning
By Arnon Puitrakul - 22 กันยายน 2023

เมื่อหลายวันก่อน เราสอนเลขให้น้อง ๆ ม.ปลาย แล้วมันมีเรื่องพวก Matrix Operation แน่นอนว่า ตอนนั้นเราก็เกลียดมันพอตัว และ น้องก็ไม่ชอบเหมือนกัน ทำให้เกิดคำถามว่า แล้วเราจะเรียนการทำ Matrix Operation ไปทำไมกัน วันนี้เราเอาตัวอย่างนึงมาเล่าให้อ่านกันดีกว่า คือ การเอามาใช้งานในกลุ่มพวก Neural Network หรือการทำ Deep Learning ที่เราชอบเอามาโม้เหม็นกัน
Inside Neuron
ถ้าเราคิดถึงพวก Deep Learning Model หรือกระทั่งพวก Neural Network ภาพที่เราเห็นมักจะเป็นภาพที่มีก้อนกลม ๆ มาต่อ ๆ กัน กลม ๆ นึง เราอาจจะต่อไปที่หลาย ๆ ก้อนกลม ๆ ต่อกันไปเรื่อย ๆ หลาย ๆ ชั้น ยิ่งชั้นเยอะขึ้นเท่าไหร่ มันก็ยิ่งซับซ้อนมากขึ้นเท่านั้นใช่มะ
ซึ่งในกลม ๆ หรือในภาษา Graph เราเรียกว่า Node หรือ ถ้าเป็นฝั่งพวก Neural Network เราก็จะบอกว่า มันคือ Neuron อันนี้แหละจุดสำคัญ คือ ภายใน Neuron มันไม่ได้มีแค่ Activation Function เท่านั้น ไม่งั้น Model เราจะ Train อะไรใช่มะ ดังนั้น จริง ๆ แล้ว ภายใน Neuron มันทำงานซับซ้อนกว่านั้น
เมื่อเรา Feed ข้อมูลเข้าไป สมมุติว่า เรามี ข้อมูลเข้ามาทั้งหมด 4 ตัวด้วยกัน เราแทนเป็น x1, x2, x3 และ x4 ใส่เข้าไป มันจะต้องเอามาคูณกับสิ่งที่เรียกว่า Weight หรือน้ำหนัก ค่านี้แหละ คือค่าที่เราพยายามจะให้ Model ปรับตอนที่เรา Train โดยเราจะแทนด้วย w1,w2,w3 และ w4 ตามลำดับ มันจะต้องเอา ข้อมูลเข้า คูณกับ น้ำหนักของแต่ละค่า
เวลาเรา Train ถ้ามันมองเห็นว่า Factor หรือ Input ไหนสำคัญกับมัน หรือ ทำให้ ลด Loss ได้ มันจะให้ Weight ของ Input นั้น ๆ มีค่าสูงขึ้น กลับกัน ถ้า มันมองเห็นว่า มันไม่สำคัญ มันก็จะ ทำให้ Weight ตัวนั้นมันมีค่าน้อยลงเรื่อย ๆ ระหว่างที่เรา Train
สุดท้าย เมื่อเราได้ ข้อมูลที่เราคูณกับน้ำหนักแล้ว เราก็จะเอามาบวกกัน หรือ ภาษาบ้าน ๆ เราเรียกว่า Sum สุดท้าย เราถึงจะเอาเข้า Activation Function แล้วได้ออกมาเป็นผลลัพธ์นั่นเอง นี่แหละ คือการทำงานของตัว Neuron ที่เราแทนมันด้วยก้อนกลม ๆ เราจะเห็นได้เลยว่า มันมีการคำนวณที่เยอะมาก ๆ มากกว่าแค่การที่เรายัดตัวเลขลง Activation Function มาก ๆ
Connecting Neuron Together
ทีนี้ เราก็จะเอา Neuron ที่เราเล่าไปก่อนหน้านี้มาประกอบร่างต่อ ๆ รวมกันจนเป็นเครือข่าย จะเล็กจะลึกใหญ่ตื้น อะไรก็ว่ากันไป การคำนวณที่เราเล่ามาใน Neuron แต่ละตัว มันก็ต้องเกิดขึ้นแน่นอน
ถ้าเราจะค่อย ๆ คำนวณ ทีละตัว เอา น้ำหนัก คูณข้อมูลไปเรื่อย ๆ ทีละตัว ทีละ Neuron ถามว่า ทำได้มั้ย คำตอบก็คือ ได้เลย ไม่มีปัญหา แต่ไม่รู้นะว่า เราจะอยู่ถึงตอนที่มันทำงานเสร็จมั้ย ยิ่งถ้าเราบอกว่า เราต้องทำงานเร็วมาก ๆ แบบ Real-time ก็เรื่องใหญ่อีก ดังนั้น การเขียนโปรแกรมให้มานั่งคูณ ๆ ทีละตัวเลย มันเป็นทางเลือกที่โคตรแย่เลย
งั้นถามว่า แล้วเราจะทำยังไงดี ก็มีนักคอมพิวเตอร์บอกว่า ในเมื่อ งานการคูณ การบวกค่าพวกนี้ มันไม่ได้เป็น Dependencies ต่อกัน งั้นเราลองมาทำให้มันสามารถคำนวณใน Throughput เยอะกว่า ใส่มันเข้าไปหลาย ๆ ตัวอย่างเลย มั้ยละ เราลองเปลี่ยน Representation จาก Array ง่าย ๆ เป็น Matrix มันเลยสิ
ถ้าเราลองคิดง่าย ๆ นะ เรามี x ซึ่งเป็น Feature ของเรา อาจจะมี ตัวเดียว หรือหลายตัวก็ได้ สมมุติว่า มี m ตัว แปลว่า เราก็จะมี x1, x2, ..., xm และอีกด้านคือ y หรือผลลัพธ์ของเรา ที่อาจจะเป็น Binary Classification ก็จะออกเป็น 1 หรือ 0 และเราจะหยอดมันเข้าไปทีละหลาย ๆ ตัวอย่าง มันก็จะกลายเป็น Matrix แบบในรูป โดยที่เราอาจจะใส่เข้าไป n ตัวอย่างพร้อม ๆ กัน ทำให้มิติของ Matrix นี้ก็จะเป็น m+1 x n
แต่เพื่อความง่าย เราก็จะดึง y ออกมา ทำให้เราได้ Matrix 2 ตัวคือ X ที่มีมิติเป็น n x m และ Y ที่มีมิติเป็น 1 x n อันนี้แหละ ข้อมูลที่เราจะ Feed เข้าไปเพื่อให้ Model มันทำการ Train
จากนั้น สิ่งที่มันเจ๋งกว่าอยู่ที่แต่ละ Node หรือ Neuron นางก็จะมี Weight ของตัวเองตาม Input ที่เข้าไป งั้นเราก็เก็บมันให้อยู่ในรูปของ Matrix ไปเลยสิ เราให้ชื่อว่า W ดังนั้น ถ้าเราบอกว่า เราอยากจะเอา Weight แต่ละตัวคูณกับ Input แต่ละตัวที่เราต้องการ คุ้น ๆ มั้ย ว่ามันมี Matrix Operation ตัวนึงที่เราทำแบบนั้นได้เลยง่าย ๆ คือ Dot Product เราก็แค่เอา X ไป Dot กับ W เราก็จะได้ผลลัพธ์ช่วงแรกมาแล้ว แล้วเราก็สามารถใช้คำสั่ง Sum เข้ามาได้ง่าย ๆ จนเหลือมิติที่เราต้องการแล้ว
 Arnon Puitrakul
Arnon Puitrakul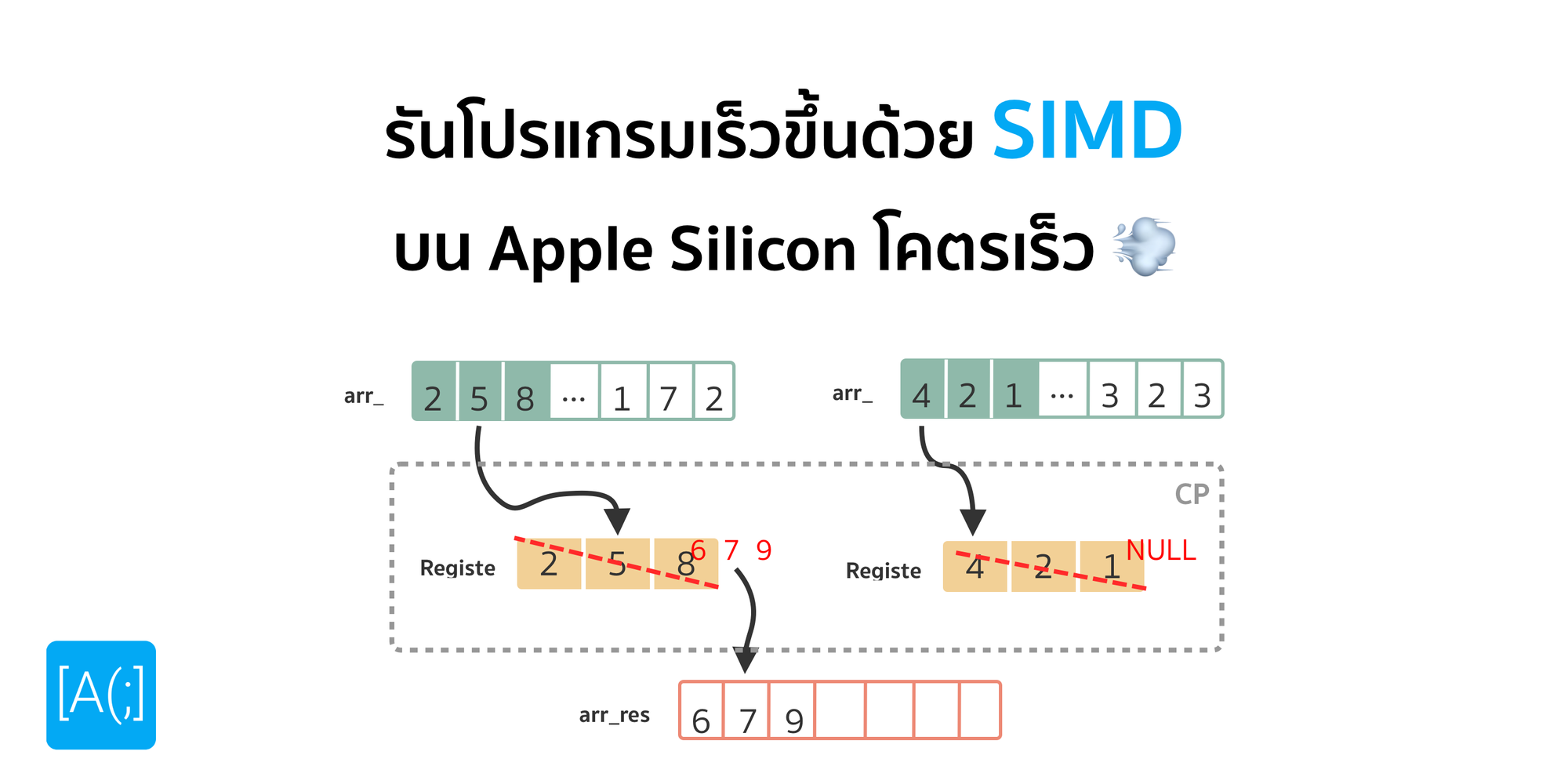
สุดท้าย เราก็ Apply พวก Activation Function ที่เรากำหนดไว้ในโครงสร้างของ Model ถ้าเป็นเมื่อก่อน เราก็อาจจะต้องค่อย ๆ ทำทีละตัวแหละ แต่สมัยนี้เราใช้พวก CPU หรือ GPU Generation ใหม่ ๆ เรามีพวกคำสั่งพวก SIMD หรือพวก Large Instruction Set ทำให้เราทำงานพวกนี้ได้เร็วขึ้น Throughput สูงขึ้นมาก ๆ
GPU came to dominate!
สำหรับคนที่เรียนคอมพิวเตอร์มา พอเราบอกว่า เราพยายาม Represent ปัญหาให้อยู่ในรูปแบบของ Matrix หรือ การทำ Vectorisation แล้ว อุปกรณ์ หรือหน่วยประมวลผลพิเศษตัวนึงที่เขาออกแบบมาเพื่อแก้ปัญหานี้ได้เก่งมาก ๆ ประสิทธิภาพสูงมาก ๆ นั่นคือ GPU หรือ บ้าน ๆ เราเรียก การ์ดจอนั่นเอง
เอ๋ะ เดี๋ยวนะ การ์ดจอ เราไม่ได้เอามาใช้เล่นเกมเหรอ ทำไมเราเอามาใช้ในงานพวกนี้ละ นั่นเป็นเพราะ พวกภาพ Graphic ที่เราเห็นทั้งหลาย พวก Operation ที่เกี่ยวข้องทั้งหมด มันล้วนเกิดจากพวก Matrix Operation ทั้งนั้นเลย เช่น เราจะเบลอรูป มันก็คือ การเอาพวก Filter ที่เป็น Matrix ขนาดประมาณนึง ไล่คูณในแต่ละส่วนของภาพที่เป็น Matrix นั่นแหละ หรือกระทั่งการเล่นเกมพวกการ Render ภาพที่เราเห็นทั้งหมด นี่ก็คือพวก Matrix Operation ทั้งนั้นเลยนะ ดังนั้น จริง ๆ แล้ว GPU มันไม่ได้เป็นอะไรที่วิเศษอย่างที่เราคิด จริง ๆ มันก็คือ หน่วยประมวลผลตัวนึงที่ออกแบบมาให้ทำพวก Vector หรือ Matrix Operation เก่งมาก ๆ มีหน่วยประมวลผลสำหรับการทำงานพวกนี้เยอะกว่าหน่วยประมวลผลทั่ว ๆ ไป
นั่นคือ เหตุที่ทำให้ ในสมัยใหม่ ๆ ที่เราทำงานทางด้าน Neural Network กัน เราถึงนำ GPU มาใช้ในการ Train และ Inference Model ใหม่ ๆ กันแล้ว เพราะประสิทธิภาพที่สูงกว่าราคาถูกกว่า นั่นเอง
xPU Born....
หลังจากที่งานพวก AI มันโตแบบก้าวกระโดดมาก ๆ ทำให้นักพัฒนาเริ่มบอกว่า เห้ย GPU ที่มันว่าเร็วกว่า CPU ในการทำงานกับพวก Neural Network มันก็เริ่มจะช้าละ และ ถ้าเราทำงานกันจริง ๆ ภายใน GPU มันมีอะไรหลายอย่างที่พวกงาน AI ไม่ได้ใช้เช่นพวก Shading Unit หรือพวก Graphic Pipeline ต่าง ๆ งานพวกนี้ มันเน้นพวก Vector หรือ Matrix Operation ล้วน ๆ เลย
แน่นอนว่า อุตสาหกรรมตอบสนองด้วยการ ออกหน่วยประมวลผลที่เฉพาะทางกว่าออกมา เช่น Google เองก็มี TPU (Tensor Processing Unit) หรือพวก NPU (Neural Processing Unit) และ Apple เจ้าก็มี Neural Engine พวกนี้ส่วนใหญ่ พวกการ Design มันก็ไม่ได้ต่างจาก Processor ตัวอื่น ๆ มากเท่าไหร่หรอก แต่เอาส่วนประมวลผลที่ไม่ได้ใช้บน GPU ออกแล้วใส่พวกที่งานทางด้าน AI ใช้เยอะมาก ๆ เข้าไปแทน เลยทำให้การ์ดพวกนี้มันทำงานได้เร็วกว่า GPU ด้วยซ้ำ
หรือกระทั่งในฝั่ง GPU เอง เช่น Nvidia เจ้าตลาด AI เลย หลัง ๆ ก็ไม่ได้มีแค่พวก Graphic Pipeline หรือ Video Encoding/Decoding เหมือนเมื่อก่อนละ เขาใส่สิ่งที่เรียกว่า Tensor Core เข้ามา เพื่อเร่งประสิทธิภาพการทำงานทางด้าน AI ให้สูงขึ้นอย่างก้าวกระโดดเลย ทำให้ ณ วันที่เราเขียนเอง เราว่า คำว่า Specialised Processor มันเริ่มได้รับความนิยมมากขึ้นเรื่อย ๆ ตั้งแต่ Apple Silicon เองที่ใส่ของพวกนี้เยอะมาก ๆ และ ฝั่ง AI เอง ที่ออก Specialised Processor เฉพาะสำหรับงานพวกนี้กันเยอะมาก ๆ
Case Study : Nvidia Tensor Core
พวก Specialised Processor สำหรับงาน AI ตัวอื่น ๆ เราไม่มีข้อมูลเยอะมาก งั้นเราของยกตัวอย่างใน Processor ที่เราทำงานด้วยทุกวันละกัน นั่นคือพวก AI Hardware จากฝั่ง Nvidia อย่าง Tensor Core บน Nvidia GPU ด้วยเนื้องานที่เราต้อง Optimise พวก AI Pipeline Process ทั้งหลาย เลยทำให้เราพอจะรู้พวกการออกแบบ และ สถาปัตยกรรม ของฝั่ง Nvidia บ้างแหละ อย่างน้อยก็มากกว่ายี่ห้ออื่นแน่ ๆ เลยเอามาเล่าละกัน
Tensor Core มันเป็น Processor ตัวนึงที่เขาออกแบบมาให้ทำงานที่เรียกว่า Fuse Multiply Add (FMA) Operation หรือ d = a*b + c ได้เก่งมาก ๆ ถ้าเราจำด้านบนได้ เอ๊ะมั้ยว่า มันคืองานแบบที่เราใช้ตอนเราทำงานกับพวก Neural Network เลยนิ (จริง ๆ แล้วมันอยู่แทบทุกที่เลย เช่น Analytical Geometry, Computer Science และอื่น ๆ อีกมากมาย)
Arnon Puitrakul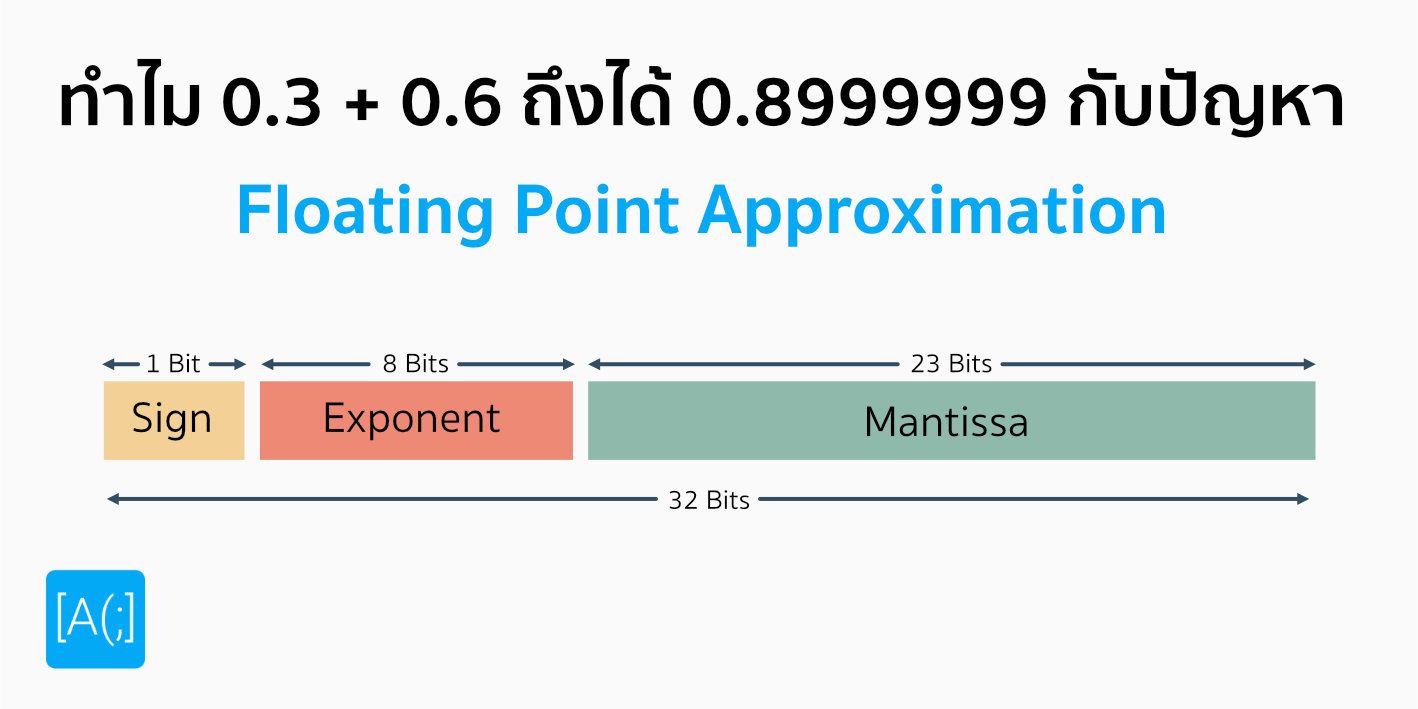
Keyword ของเรื่องนี้คือคำว่า Mixed-Precision เรื่องของเรื่องมันคือ ปกติ เวลาเราทำงานส่วนใหญ่ เวลาเราจะเก็บค่าทศนิยมทั้งหลาย เราจะเลือกจองพื้นที่แบบ 32-Bits หรือทศนิยมแต่ละค่า เราจะต้องใช้ขนาด 32 bits ในการจัดเก็บ เราเรียกพวกนี้ว่า FP32 (Floating-Point 32 Bits) นั่นเอง ยิ่งเราเก็บทศนิยมเยอะเท่าไหร่ ค่าที่เราเก็บได้มันก็จะแม่นยำมากขึ้นเท่านั้น ลดปัญหา Underflow และ Overflow ไปได้เยอะเลย แต่...... มันต้องมีข้อแลกเปลี่ยน
ถ้าเราใช้ขนาดของทศนิยมใหญ่มาก มาพร้อมกับ Memory ที่ต้องใช้เยอะกว่า และ การคำนวณ ก็ทำได้ยากกว่าด้วย คิดภาพง่าย ๆ ถ้าเราบวกทศนิยม 5 ตำแหน่ง กับ 2,000 ตำแหน่ง เราจะบวกอันไหนได้เร็วกว่า คอมพิวเตอร์ก็เหมือนกัน
Idea ของ Mixed-Precision คือในเมื่อทศนิยมใหญ่ มันทำงานเยอะ งั้นเราออกแบบ Processor พิเศษที่รับ Matrix แบบ FP16 หรือ 16-Bits เข้ามาแทน เพื่อเอามาทำ Dot Product กัน และ เอา FP32 มาบวกตอนสุดท้าย ก็น่าจะทำให้ออกแบบได้ดีกว่า ประสิทธิภาพสูงกว่า จะเห็นว่า ใน FMA อันนี้ เราใช้ FP16 2 ตัว และเอาผลลัพธ์มารวมเป็น FP32 แล้วค่อยเอามาบวก กับ FP32 ต่อไป สุดท้าย เราก็จะได้ผลลัพธ์ออกมาเป็น FP32 เหมือนเดิมทุกประการ ดังนั้น ปลายทาง สิ่งที่เราได้ ก็จะคล้ายเดิมมาก ๆ เลยละ สละความไม่เที่ยงของตำแหน่งทศนิยมไปบ้าง แต่แลกกับความเร็วที่ได้ นั้นก็บอกเลยว่า เร็วมาก ๆ
แล้วปีต่อ ๆ มา Nvidia ก็ออก Second-Generation Tensor Core ออกมา ไอ้นี่แหละ แมร่งสุดตรีนมาก จากเดิมเราบอกว่า เราลดขนาดไปใช้พวก FP16 แทน FP32 อันนี้บอกว่า ไม่ ๆๆๆ เราสละความแม่นยำ ไปยัดหน้าความเร็วได้มากกว่า ด้วยการอนุญาติให้ใช้พวก FP8, FP4 และ FP1
จากนั้น Third-Generation Tensor Core ออกมาแล้วบอกว่า เห้ย ๆ นาย ๆ นายไม่ต้องแก้ Code อะไรแล้ว ไม่ต้องมานั่ง Cast Data หรือบอก Model แล้วนะว่า เราจะใช้ Floating-Point ขนาดเท่าไหร่ เพราะเขา Implement Automatics Mixed Precision เข้ามา (แต่เราก็ยังเลือกเองได้อยู่) ทำให้เราสามารถเร่งความเร็วได้ระดับแบบ 2 เท่าโดยที่ไม่ต้องทำอะไรเลย ล่นเวลาการทำงานของพวก Developer ไปได้เยอะมาก หรือกระทั่งการทำงานผ่าน NVLink อีก ที่ทำให้รองรับการทำงานในสเกลขนาดยักษ์ได้ง่ายขึ้น ลื่นไหลมากขึ้นไปอีก โหดสัส ๆ เลยละ
และ ล่าสุด ณ วันที่เขียนคือ Forth-Generation Tensor Core ก็คือ Optimise พวก การทำงานของ FP8 ที่เราใช้กันเยอะมาก ๆ ในพวกกลุ่ม LLM ทาง Nvidia เคลมว่า มันจะทำงานได้เร็วขึ้นสูงถึง 30 เท่าในงาน LLM เลยละ เรียกว่าโหดขึ้นไปอี๊ก
Mixed-Precision Training ไม่ได้น่ารักกับทุกคน
อ่านมาแล้ว น่าจะพอเดาได้แล้วนะว่า ทำไม Nvidia ถึงเป็นเจ้าตลาดงานทางด้าน AI เราทดลองใช้งาน Forth-Generation Tensor Core บน Nvidia H100 เทียบกับ Nvidia A100 ทำให้เราเห็นความแตกต่างแบบ สุดขั้ว ว่าเขาไม่ได้เลยจริง ๆ แต่ ๆๆๆๆๆ เราจะบอกว่า ถึงมันจะเก่งขนาดนี้ แต่มันไม่ได้เก่งกับทุก Model บาง Model ก็ไม่ค่อย Works กับ Mixed-Precision เหมือนกัน เพราะบาง Model ค่าที่มันวิ่ง ๆ อยู่ใน Model มันอาจจะน้อยมาก ๆ จนมัน Overflow หายไปเลย ไปอ่านใน Documentation ของ Nvidia ได้
ประสบการณ์ตรงเลย เราลอง Enable Mixed-Precision บน Tensorflow สิ่งที่ได้คือ เวลาเรา Train ค่า Loss มันออกเป็น NaN ไปเลย เพราะค่ามันน่าจะ Underflow สักอย่างนี่แหละ เลยทำให้สุดท้าย Train ได้นะ แต่เอามาใช้ยังไงล๊ะลุ๊งงงงงง
แต่เราสามารถแก้ปัญหามันได้ด้วย 3 วิธีหลัก ๆ ก็คือ การใช้ Loss Scaling เพื่อป้องกันค่าที่มันน้อยหรือมากไปก็ได้เหมือนกัน หรืออาจจะโดดไปเล่นพวก Automantics Mixed Precision ก็ได้ หรือสุดท้าย คือการแก้ Model ให้เข้ากับการ Train แบบ Mixed-Precision ได้
สรุป
จากเรื่องการคูณ Matrix มันไปถึง Nvidia Tensor Core ได้ไงวะเนี่ย เอาว่า Takeaway Message ที่จะบอกคือ เรื่องเล็ก ๆ อย่างการคูณ Matrix ที่เราเรียนกันในมัธยมนี่แหละ มันเป็นรากฐานที่สำคัญในงานหลาย ๆ อย่างเลยนะ ตัวอย่างเช่น การเอามาใช้ในงานพวก AI อย่างการทำ Neural Network ที่เราเอามาใช้กันอย่างแพร่หลายในตอนนี้ ดังนั้น เรียนไปแล้วอย่าพึ่งเบื่อนะ คณิตศาสตร์มันมีอะไรที่น่าพิศมัยกว่านี้อีกเยอะมาก ๆ ที่เราอาจจะไม่รู้มาก่อน โอเค จบ จ้าาา
Related Posts

ทำยังไงถึงจะประหยัดค่า AI ในการทำงานได้
04 กรกฎาคม 2026 - 1 min readเมื่อหลายปีก่อน เราพูดบ่อยมาก ๆ ว่าเราน่าจะประหยัด Token ในการใช้ AI แต่คนก็บอกว่า นี่ เราจะต้องยัด Token เข้าไปเยอะ ๆ ใช้ Reasoning เยอะ ๆ สิมันจะได้ฉลาด แต่วันนี้ราคา Token นับวันยิ่งแพงขึ้นเรื่อย ๆ ทำยังไงกันละ เราถึงจะได้ความฉลาดเท่าเดิม แต่ประหยัดเงินในกระเป๋าของเราได้...

รู้จักกับ NVFP4 มาตรฐานการ Quantised จาก Nvidia
17 มิถุนายน 2026 - 1 min readก่อนหน้านี้ เรารีวิว DGX Spark สำหรับใช้งานในบ้านเราไป เลยทำให้เราได้ไปนั่งหา Model เพื่อมารัน จนอ่านไปเจอกับ NVFP4 ที่เป็น Quantisation ของ Nvidia เอง แล้วมันเป็นอะไรที่เจ๋งมาก ๆ วันนี้เราจะมาเล่าให้อ่านกันว่า ทำไมมันเจ๋ง และ ใครควรจะใช้...

เจาะลึก Vera CPU ไม้ตายใหม่จาก Nvidia งัดมาสู้กับ Agentic AI
14 มิถุนายน 2026 - 1 min readไม่ไหวแล้ววว คอมพิวเตอร์ตอนนี้สู้กับ AI ที่กินทั้ง Memory และ Compute มหาศาลไม่ไหวแล้ว !! เจาะลึก Vera Rubin ที่ Nvidia ออกมาเพื่อแก้ปัญหาที่เจอโดยเฉพาะ เขาทำยังไงอ่านได้ในบทความนี้เลย...

Stacked CMOS Sensor เทคโนโลยีที่ทลายขีดจำกัดความเร็วของกล้องยุคใหม่
20 พฤษภาคม 2026 - 1 min readหลายวันก่อน Sony เปิดตัวกล้องใหม่ในรุ่น Sony A7RVI ที่เขายอมเปลี่ยนไปใช้ Stacked CMOS Sensor แล้วหลังจากเราบ่นมานานว่า ทำไม Sony ไม่มีกล้องที่ใช้ Sensor แบบนี้สักที ไหน ๆ วันนี้ Sony ทำออกมาแล้ว เรามาเล่าให้อ่านกันว่า เทคโนโลยีนี้คืออะไร และมันเข้ามาแก้ปัญหาอะไร...