Feature Selection ใน Machine Learning จะเอาอะไรมาใส่ดีนะ
By Arnon Puitrakul - 26 พฤษภาคม 2019

ปัญหานึงของการทำ Machine Learning (ไม่นับ Subset ของมันอย่าง Deep Learning นะ) คือเรื่องของ Feature บาง Dataset ก็มีอยู่ไม่กี่ Feature ก็ไม่น่าจะเดือดร้อนอะไรเท่าไหร่ แต่บาง Data นี่สิ Feature บานไปหมด ไม่รู้จะทำยังไงเลย วันนี้เราจะมานำเสนอ การทำ Feature Selection กัน
Feature Selection คืออะไร ?
Feature Selection ก็ตามชื่อมันเลย คือ การเลือก Feature นั่นแหละ เพราะ Feature เรามีเยอะไปหมด ทำให้พอเวลาเราไปใช้งาน เช่นการสร้าง Model ก็อาจจะเป็นอะไรที่สร้างความชิบหายในแง่ของ Resource กันมานัดต่อนัดแล้ว ทำให้การเลือก Feature เป็นเรื่องสำคัญมาก
ถ้าเรานึกไม่ออกว่า ถ้า Feature เยอะแล้วทำไม ให้เรานึกถึงเวลาเราเอาไปสร้าง Model ถ้า Feature เยอะนั่นแปลว่า เครื่องจะต้อง Fit Model เทียบกับ Feature จำนวนมาก ทำให้ใช้เวลาในการสร้างนานอยู่พอควรเลย นอกจากนั้น เมื่อเราสร้าง Model ออกมาแล้ว แล้วเราจะใช้ เราก็ต้องป้อน Data นั่นก็คือ Feature ให้เครื่องตามจำนวนที่เราใส่เข้าไปตอนสร้าง Model ใช่ม่ะ ถ้าเรามีเงินจำกัด การที่เราใช้ Feature เยอะ ๆ มันก็ทำให้เราได้จำนวน Data น้อยลงนั่นเอง เพราะ 1 Record ของเราแพงมาก ทำให้การลดจำนวน Feature ก็สามารถเพิ่มจำนวนของข้อมูลได้ ถ้าเราเป็นคนเก็บข้อมูลอะนะ
แล้วอันไหน สำคัญหรือไม่สำคัญละ
เป็นคำถามที่ดีเลย เราจะรู้ได้ยังไงว่า อันไหนสำคัญ อันไหนไม่สำคัญ เราก็ทำได้หลายวิธีมาก เช่น Literature Review ดูก่อนสิ๊ว่า ใน Field ที่เราเอา Data มาทำ บอกว่า Feature ไหนสำคัญบ้าง หรือถ้าเราไม่รู้อะไรเลย การใช้ความรู้ทางสถิติมาช่วย ก็ทำได้เหมือนกัน
เท่าไหร่เรียกว่า เยอะ หรือ น้อยไป
อื้ม... อีกคำถามที่มักจะตามมา เวลาเราพูดถึง Feature Selection ก็คือ แล้วเราจะต้องใช้จำนวน Feature เท่าไหร่ดีละ... จริง ๆ มันก็ไม่ได้มี Magic Number ตายตัวอะไรแบบนั้น
เราเคยเขียนเรื่องนี้ไว้ใน Blog เราก่อนหน้านี้แล้ว ลองเข้าไปอ่านได้ที่นี่เลย Machine Learning The Series 🤖 : How to get started ? ในส่วนของ Feature Selection
แล้วมันมีวิธีอะไรบ้างละ ?
วิธีการในการเลือกมันมีเยอะมาก ๆ เลยละ แต่ถ้าเราแบ่งออกมาใหญ่ ๆ เราจะแบ่งได้ 3 วิธีใหญ่ ๆ ดังนี้
- Filter Method
- Wrapper Method (Forward & Backward Stepwise)
- Embedded Method
วันนี้เราจะมาเล่าทั้งหมดนี่กันว่า เราจะสามารถทำมันได้ยังไงบ้าง อาจจะมีบาง Part ที่เป็นสูตร หรืออะไรที่ดูน่ากลัว ก็ถ้าใครใคร่อ่านก็เชิญตามสบาย หรือถ้าใครใคร่ไม่ก็เชิญข้ามได้เช่นกันไม่ว่ากันฮ่ะ
ปล. ที่เราจะเล่าต่อไปนี้ จะไม่นับพวกการเลือกจาก Missing Data นะ ตอนนี้เราจะถือว่า การตัด Feature บางอันทิ้ง หรือเก็บมาแล้ว Impute Data ถูกทำมาจาก Data Preparation แล้วนะ
Filter Method
ไปที่วิธีที่น่าจะง่ายที่สุดอย่าง Filter กันก่อน หลักการง่าย ๆ ของการ Filter คือการ กรอง เอิ่ม.... ช่วยได้มากจริง ๆ โอ๊ยยย แต่เราจะกรองมันอย่างมีหลักการนิดนึง
Goal ของการสร้าง Model ที่แหล่มแมวคือ การที่เครื่องมันสามารถแยกของออกจากกันได้ใช่ม่ะ ไม่ใช่ว่า ใส่ส้มไป ได้มะนาวบ้างแหละ ได้ ข่าบ้างแหละ และในขณะเดียวกันต้องทำให้ Model มีความซับซ้อนน้อยที่สุดด้วย
ดังนั้น ถ้าเราเอาข้อมูลเรามาทำ Scatter Plot สิ่งที่เราอยากได้คือ ของแต่ละอย่างถูกแยกกันอย่างชัดเจน มากกว่าอยู่ชิด ๆ มั่ว ๆ กันใช่ม่ะ
Key ของ Filter Method คือ การหา Predictive Power หรือ พลังในการทำนาย ออกมาให้ได้ พูดง่าย ๆ คือ ความสามารถในการแยกข้อมูลออกจากกัน แล้วเราก็เลือกอันที่มันมีพลังเยอะ ๆ เข้าไปใช้ เราก็คาดหวังว่า เออ เมื่อมันมาอยู่ด้วยกันแล้วมันจะแหล่มสุด
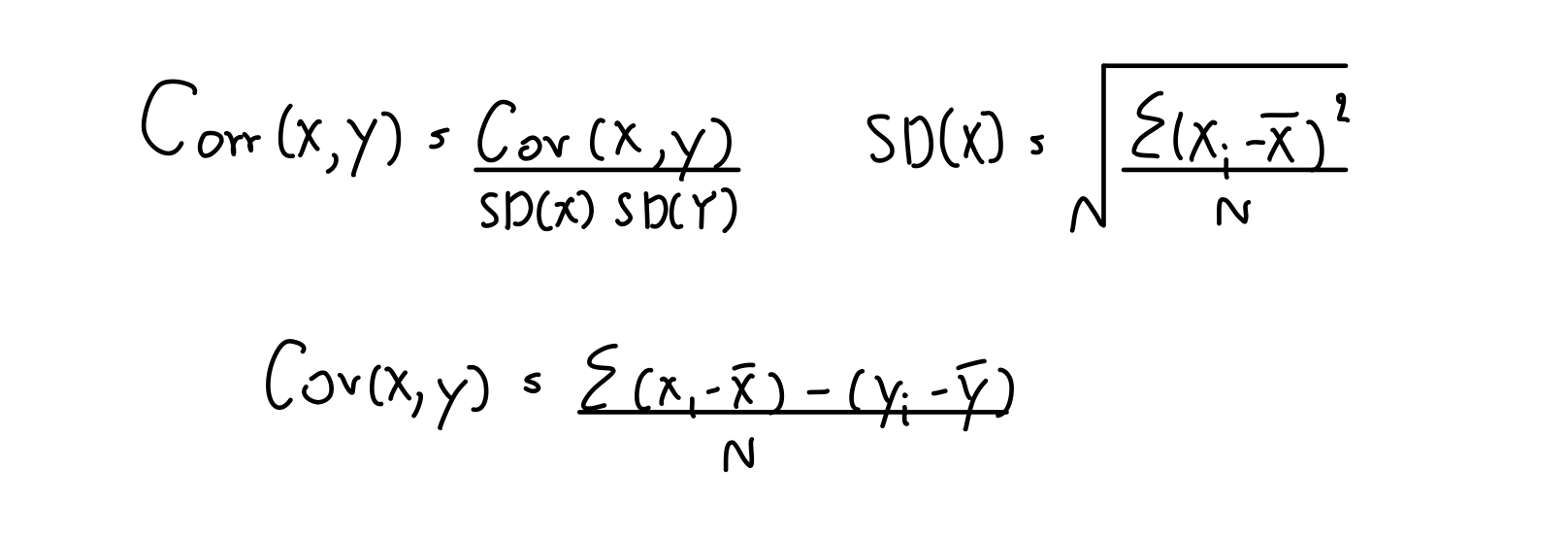
สูตรการหา Correlation น่าจะหาได้กันทุกคนนะ จริง ๆ Correlation มันต้องย่อเป็น Cor นะ เราเขียนเกินเป็น Corr เฉย
วิธีนึงที่เราว่าง่ายที่สุดคือ การดู Correlation ภาษาไทยเราไม่รู้มันเรียกอะไร เรียกเป็นภาษาอังกฤษไปละกันนะ ถามว่ามันคืออะไร มันคือ ความเหนียวแน่นระหว่างของ 2 อย่าง งง อะ ดิ เออ เราก็ งง ถถถถถถ เอาเป็นว่า เข้าใจไปแบบนี้ละกัน ถ้าค่ายิ่งเยอะแปลว่า Y เนี่ยขึ้นกับ X มากเท่านั้น
ถ้าเราเอา Feature นั้น ๆ มาหา Correlation คู่กับ Y ในที่นี้คือ Target ของเรา ผลออกมา ถ้าเยอะก็คือ Target ของเราขึ้นกับ Feature นั้น ๆ มากขึ้น อะไรแบบนั้น ซึ่งเห็นสูตรอะไรเยอะขนาดนี้ เราก็ไม่ต้องเขียนเองก็ได้ ใน Pandas เวลาเรา Import ข้อมูลมาเป็น DataFrame เราสามารถหาได้จาก Method ที่ชื่อว่า corr และเราสามารถใช้ Seaborn ในการ Plot ได้เลย
corr = dataset.corr()
sns.heatmap(round(corr,2), annot=True)
plt.show()
สิ่งที่เราจะได้ก็จะเป็น Heatmap แสดงว่า ระหว่าง Feature ไหนที่มี Correlation มาก ในทีนี้เราอยากให้ดูที่ ระหว่าง Feature กับ Target ของเราว่าอันไหนเยอะ
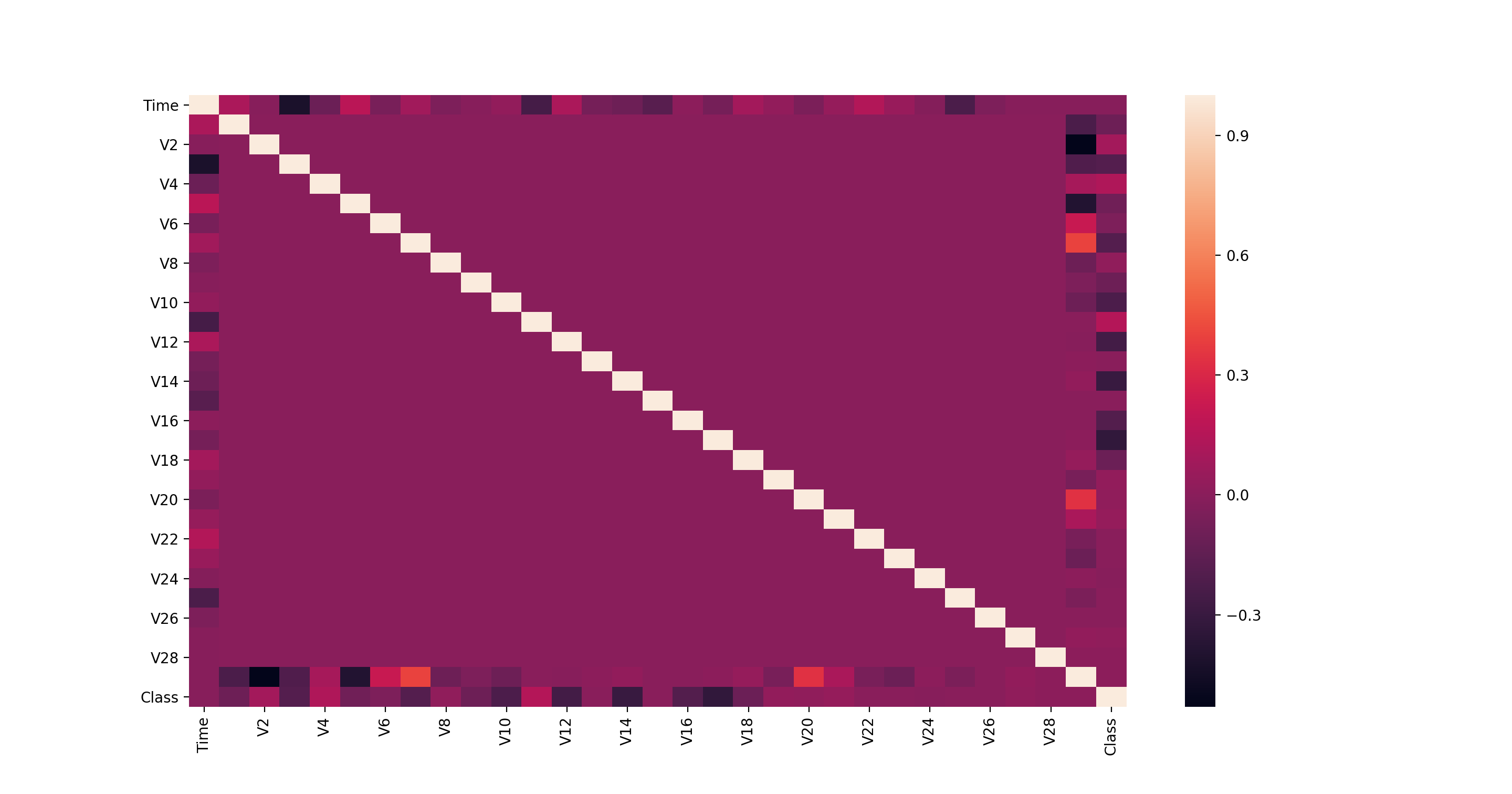
ในที่นี้ Target ของเราชื่อ Class คือ อันสุดท้ายนั่นเอง เวลาดู ก็คือ เราก็ต้องดูว่า ใน Column สุดท้าย มี Feature อะไรบ้างที่ Correlated กับ Class เยอะมาก ๆ แล้วเราก็ลองเลือกมาทำ Model ได้เลย
แต่ Correlation มันใช้ได้กับ Feature และ Target ที่เป็นค่า Continuous (เป็นตัวเลข เช่น ส่วนสูง) อย่างเดียว ถ้า Data ของเรา เป็น Categorical (เป็นประเภท เช่น ชอบไม่ชอบ) เราอาจจะต้องพิจารณาในการใช้สถิติอื่น ๆ อย่าง ANOVA และ Chi-Square Statistics เข้ามาช่วยแทน
อีกวิธีที่น่าสนใจสำหรับ Categorical Data คือการใช้ Information Gain (IG) แต่ก่อนเราจะไปคำนวณ IG ได้ เราจะต้องไปรู้จักกับสิ่งที่เรียกกว่า Entropy กันก่อน
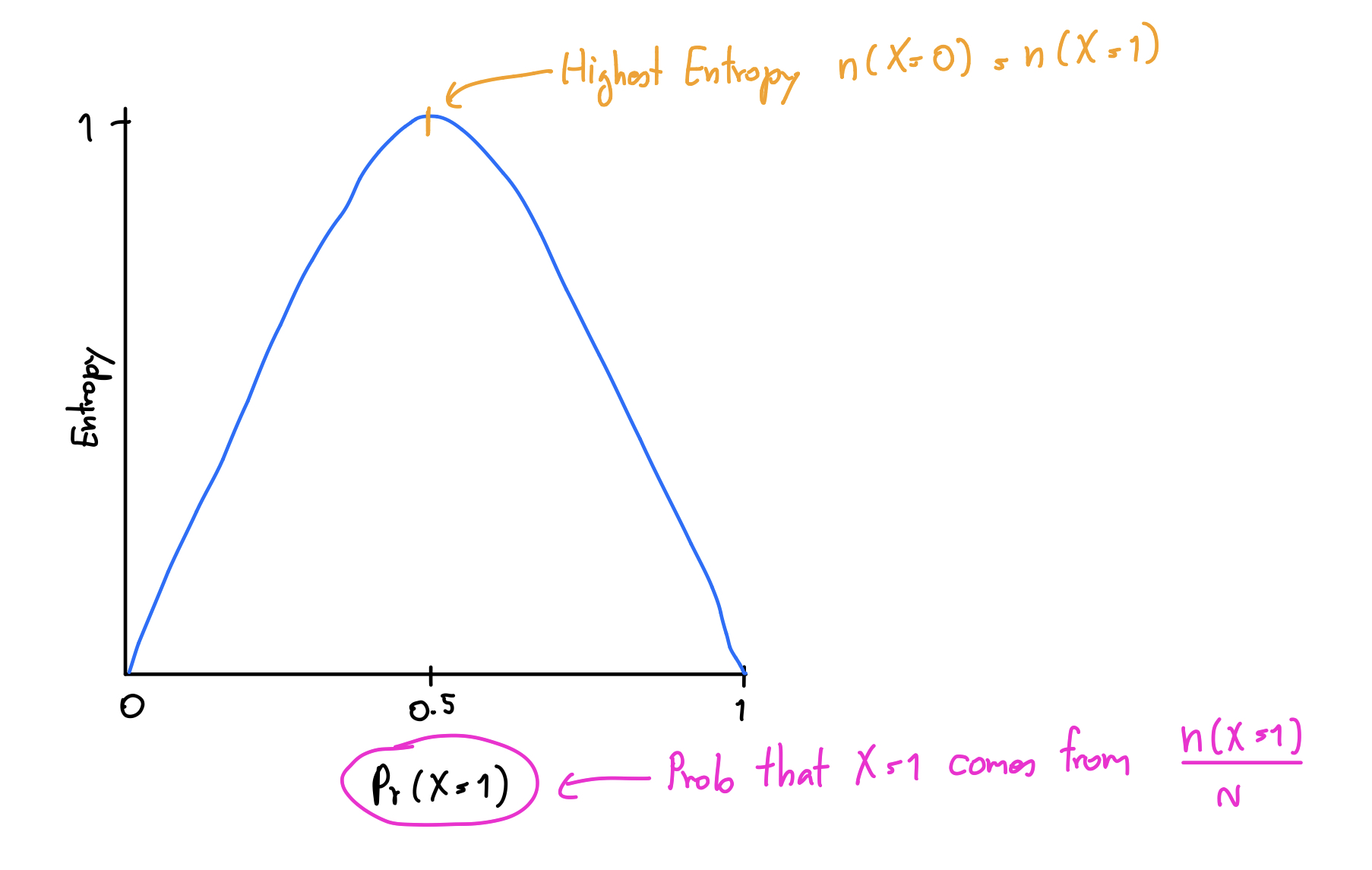
Entropy เป็นค่าที่ใช้วัดความต่าง การกระจายตัว ของข้อมูล ถ้าข้อมูลนั้นมีการกระจายตัวมาก Entropy ก็จะสูง กลับกัน ถ้าข้อมูลมันชิดกันมาก ๆ Entropy ก็จะต่ำนั่นเอง ในที่นี้เราพูดถึงจำนวนนะ ดูอย่างในภาพเลยละกัน แกนตั้งเราแทนด้วยค่า Entropy และแกนนอนเราจะแทนด้วย Pr(X=1) หมายความว่า ค่าความเป็นไปได้ที่ X จะเป็น 1 อาจจะสมมุติว่าเป็น การทอยเหรียญ แล้วออกหัวละกัน ซึ่งก็จะมาจาก จำนวนครั้งที่เราทอยแล้วออกหัวหารด้วยจำนวนครั้งที่เราทอยเหรียญทั้งหมดนั่นเอง
จะเห็นว่าค่า Entropy จะสูงที่สุดเมื่อ Pr(X=1) = 0.5 นั่นคือ Entropy คือการวัดความเรียบร้อยไปในทางเดียวกันของข้อมูลนั่นเอง เพราะค่ามันจะขึ้นสูงเมื่อ เราทดลองออกมาแล้ว จำนวนครั้งที่ทอยเหรียญทั้งหัวและก้อย โอกาสออกเท่ากันนั่นเอง
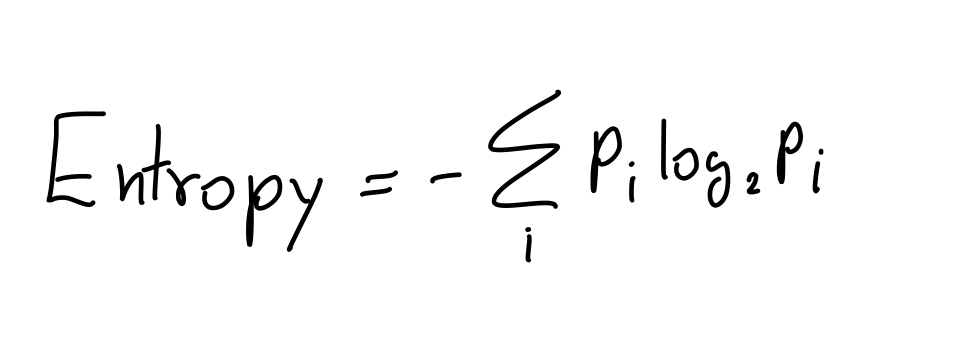
สูตรของมันก็ช่างเรียบง่ายมาก ก็คือ เราจับแต่ละเคส มาหาความน่าจะเป็นที่จะเกิดเคสนั้น แล้วคูณด้วยความน่าจะเป็นที่เราพึ่งหาไป แล้วก็จับทั้งหมดบวกกันเป็นอันเรียบร้อย
ถามว่า แล้วมันมาวัดยังไง อ่าาาห์ น่าสนใจ ลองคิดถึง การเกิดไข้หวัดในหน้าหนาวละกัน ถ้าสมมุติว่า เราหว่านข้อมูลมา สัก 100 คนของคนที่เป็นหวัด ถ้าหวยออกว่าข้อมูลที่เราได้มาคือ คนที่เป็นหวัด และ เป็นผู้ชายมี 80 คน และ คนที่เป็นหวัด และ เป็นผู้หญิงคือมี 20 คน ถ้าเราเอาไปคิด Entropy ค่าของมันก็น่าจะออกมา ต่ำ ใช่ม่ะ ถ้าคิดอีกแง่ละ คิดว่า อื้ม.. โอกาสการเป็นหวัดในหน้าหนาว ผู้ชายจะมีโอกาสเป็นได้มากกว่า อื้ม... ข้อมูลตรงนี้ก็น่าจะช่วยให้ Model แยกของออกจากกันได้ใช่ม่ะ แน่นอนว่า เราไม่ต้องทำทั้งหมดเองเลย ใน Python ก็มีคนเขียนไว้ให้เราแล้ว ใน Package ที่ชื่อว่า scipy
from scipy import stats
stats.entropy(dataset.x1)
มันก็จะให้ Entropy ของ Column ที่ชื่อว่า x1 ออกมาให้เรา ง่ายมาก ๆ เอาหล่ะ ทีนี้ลองไปอีก Step กับ Information Gain กันเลย
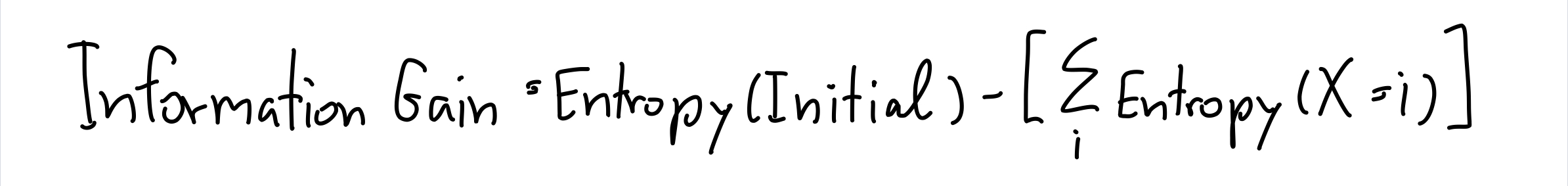
Information Gain มันคือค่าที่บอกว่า เรามีข้อมูลมากขึ้นเท่าไหร่ จากการ รู้ค่าของ Feature นั้น ๆ งงใช่ม่ะ เรายัง งง เลย ง่าย ๆ คือ ยิ่ง Information Gain สูงยิ่งดีน่าเลือกนั่นแหละ ซึ่งมันสามารถคำนวณจากสูตรด้านบนเลย
ง่ายมาก ๆ อีกเหมือนกัน นั่นคือ เราก็หา Entropy ของข้อมูลทั้งหมดออกมาก่อน แล้วก็ลบกับ Entropy ของแต่ละเคส ตัวอย่างเช่น ถ้าเราเอาเพศ กับ การเป็นหวัดในหน้าหนาวมาคิด
เราก็ต้องเริ่มจากหา Entropy ของทั้งหมดก่อน แล้ว ลบด้วยผลรวมของ Entropy ของคนที่เป็นผู้ชาย และ ผู้หญิงเข้าไป ก็จะได้ Information Gain ของเพศกับการเป็นหวัดในหน้าหนาวออกมาแล้ว
ส่วนใหญ่วิธีการหา Information Gain จะเอามาใช้ในการสร้าง Tree เลยว่า จะเอา Criteria อะไรขึ้นมาก่อน ซึ่งถ้าเราเอาง่าย ๆ เลยนะ เราก็อาจจะเอาข้อมูลทั้งหมดทุก Feature ไปสร้าง Tree ก่อน แล้วมาดู Tree ว่ามันเอาอะไรขึ้นก่อน เราก็ไล่จาก Root ลงไปด้านล่างมันก็คือเรียง IG จากมากไปน้อยนั่นเอง เพราะสุดท้ายแล้วการใช้ IG ในการสร้าง Tree เป้าหมายของมันคือการ Minimise จำนวนชั้นความลึกของ Tree นั่นเอง ทำให้มันเลยต้องพยายามให้ Feature ที่แยกข้อมูลออกจากกันได้มากที่สุดก่อนนั่นเอง
ทั้ง 2 วิธีนี้เป็นเพียง วิธีง่าย ๆ ในการที่เราจะใช้ Filter Method ในการทำ Feature Selection สำหรับทั้ง Continuous และ Categorical Data วิธีอื่น ๆ อย่างการใช้ ANOVA และ Chi-Square Statistics ก็สามารถเอามาใช้ แต่ต้องดูข้อมูลด้วยนะว่า มันเป็นประเภทไหน แล้วเลือกใช้ให้ถูก
Wrapper Method
Wrapper Method เป็นวิธีที่เราว่ามันโคตรเท่ เราเรียนครั้งแรกในวิชาสถิติเลย หลักการของมันคือ การหาพลังในการทำนายเหมือนกับวิธีก่อนหน้านี้เลย แต่แทนที่จะใช้แค่ Feature เดียว ไม่ ! ใน Wrapper Method เราจะใช้หลาย ๆ Feature เข้ามาวัดกันไปเลยว่า เมื่อ Feature พวกนี้เข้ามาอยู่รวมกัน อันไหนจะแหล่มแมวสุด
ถ้าเราเรียนคณิตศาสตร์มา เราจะรู้ว่า ถ้าเรามี N Features และเราต้องมานั่งหาว่า Feature ไหนเมื่ออยู่ด้วยกัน กี่ตัวไม่รู้ จะให้ Predictive Power ที่มากที่สุด เครื่องต้องเลือกและสร้าง Model ทั้งหมด 2^N Model ก็คือ เอา หรือ ไม่เอา นั่นเอง แต่ว่า เข้ !!! อย่างเยอะ ชาตินี้จะทำเสร็จมั้ยถาม !!!
ถ้าทำทั้งหมดนั่น ก็เหนื่อยตายแน่ ๆ ทำให้เราต้องหาวิธีใหม่มาเพื่อให้มันเร็วขึ้น วิธีที่ใช้กันก็จะเป็น Forward และ Backward Stepwise
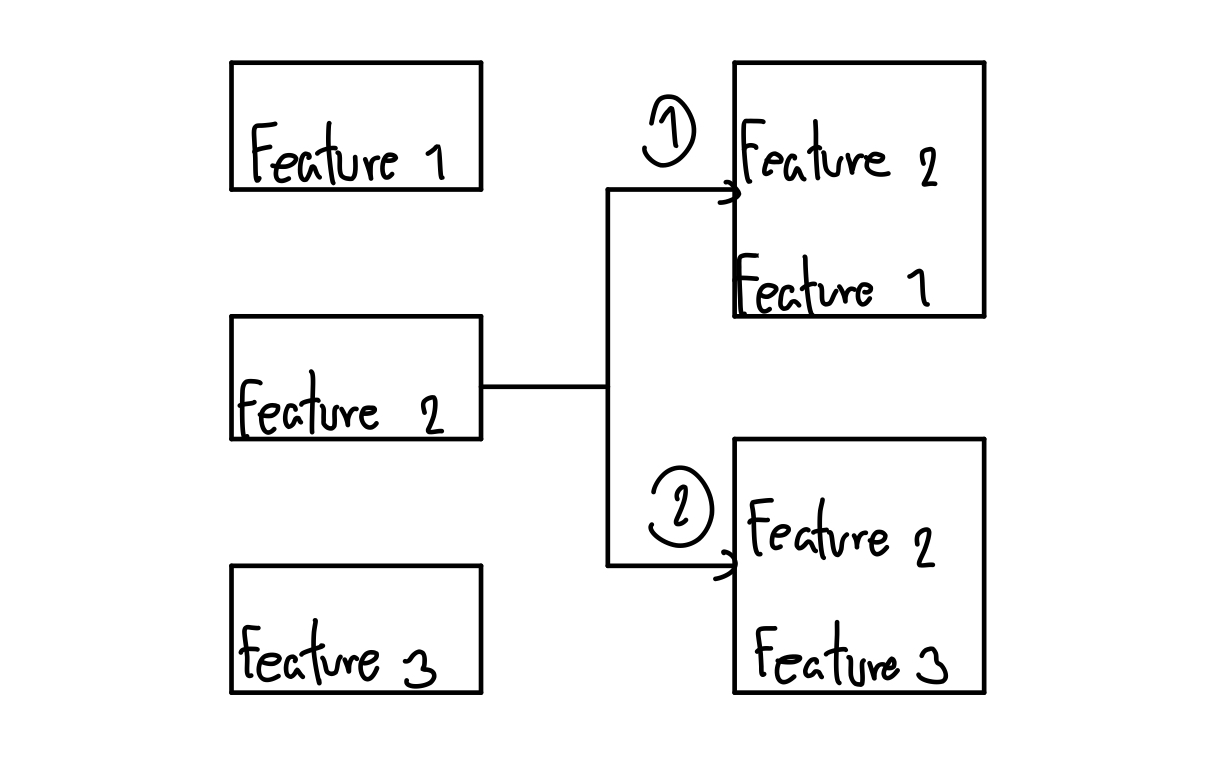
มาที่ Forward กันก่อน วิธีของมันคือ การที่เราเริ่มจาก Model เปล่า ๆ ก่อน แล้วค่อย ๆ ลองเติม Feature เพิ่มทีละอัน แล้ววัดผลออกมาดูว่าเป็นอย่างไร แล้วก็เลือกอันที่ดีที่สุดใส่เข้าไป ทำแบบนี้ไปเรื่อย ๆ จนครบจำนวน Feature ที่เรากำหนดไว้
จากรูปภาพเราจะเห็นว่า มันจะเริ่มจาก Model เปล่า แล้วเลือก ระหว่าง Feature 1-3 ก่อน สมมุติว่า เราเลือก Feature 2 มา ถัดไป มันก็จะลองเลือก Feature 1 (อันที่ 1) หรือ 3 (อันที่ 2) เข้ามา ทีละรอบ แล้ววัดผล อันไหนดีกว่ามันก็เอาอันนั้นมา แล้วก็จบ (ที่ทำแค่ 2 รอบเพราะในตัวอย่างนี้เราเลือกมาแค่ 2 อันที่มันคิดว่าดีที่สุดจากวิธีนี้)
นั่นทำให้ จำนวนที่มันต้องหาจะอยู่ที่ 1+N(N+1)/2 เท่านั้น ซึ่งต่างจากที่เราลองมันทุกอันที่ต้องใช้ทั้งหมด 2^N ไปลิบลับ
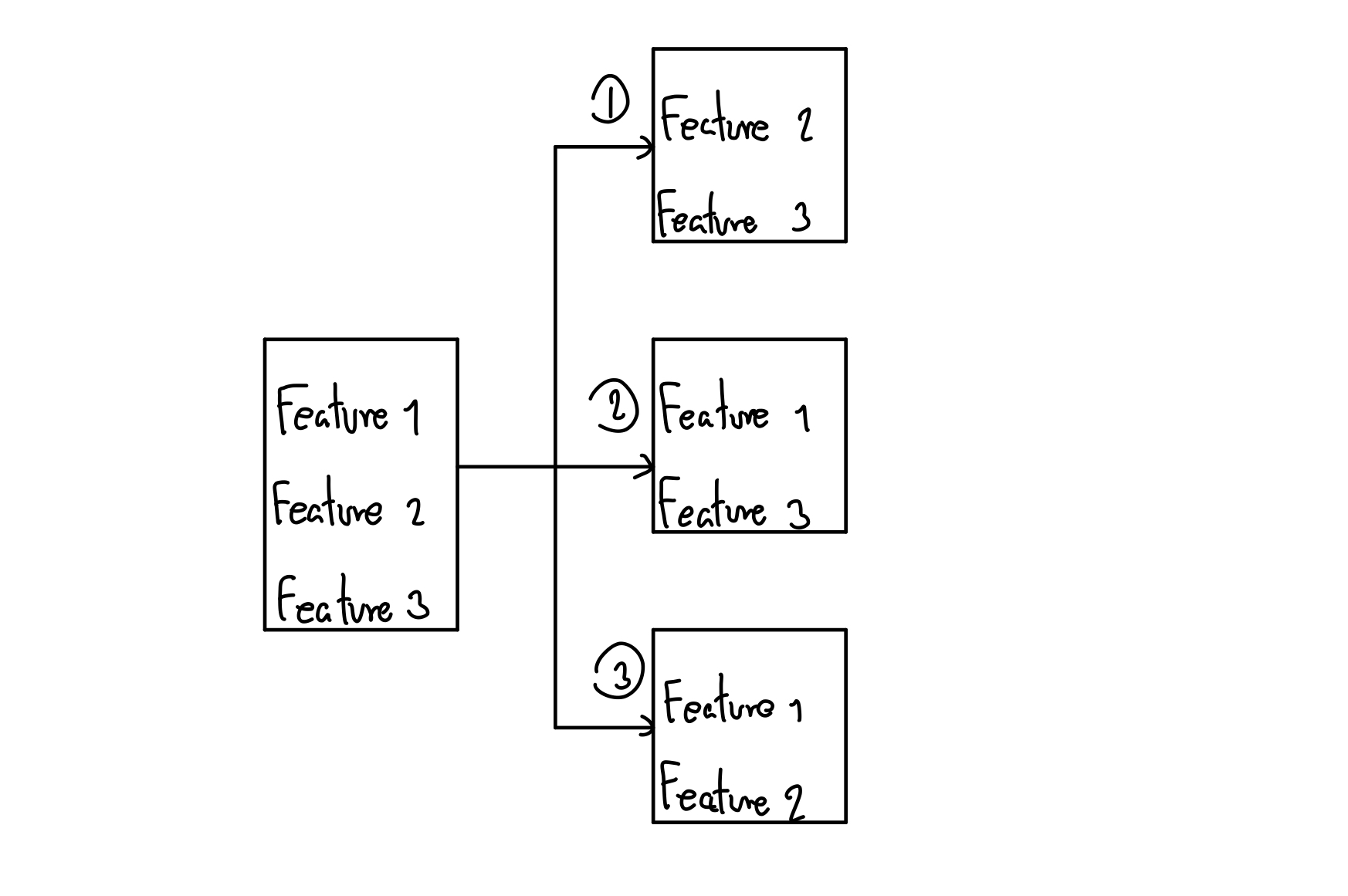
และ Backward ก็จะทำงานกลับกันคือ เราเลือกทั้งหมดตั้งแต่แรกเลย แล้วสิ่งที่เราต้องทำแทนที่จะเอา Feature มาใส่ เราก็โยนทิ้งแทน ก็คือ โยนอันไหนแล้วดีกว่า ก็โยนอันนั้นออกไป เหมือนโยนขี้นั่นแหละ 💩 จากตัวอย่างในภาพข้างบนเราจะเห็นว่า Feature ทั้งหมดถูกเลือกเข้ามาแต่แรก ขั้นตอนต่อไปก็คือ การเอา Feature ออกตัวนึง มันก็ต้องมาเลือกระหว่าง Model ที่ 1-3 ละว่า อันนี้ดีกว่าก็เอา Feature ที่เลือกมาไปสร้าง Model ต่อไป
นอกจากนั้น เอาให้พีคจาก Forward และ Backward เข้าไปอีกด้วย Recursive Feature Elimination (RFE) อันนี้มีใน Scikit-learn ด้วยนะ คือ แทนที่เราจะเอาเข้า หรือ เอาออกอย่างใดอย่างนึง เราไม่อยากเลือก เอาก็ทำมันทั้งคู่นั่นแหละ ทำให้มันสามารถ Explore ความเป็นไปได้มากขึ้น
Embedded Method
เพิ่มดีกรีความเหี้ยมโหดเข้าไปอีก จากวิธีแรกเราเลือกจากดู Feature เดียว ๆ พอมาาวิธีที่ 2 เราค่อย ๆ จับหยิบ ๆ ใส่ ๆ มาใน Embedded Method เราบอกว่า ไม่เอาแล้ว เราไม่ทำแบบนั้นละ เลือก ๆ อะไรเสียเวลา ไม่เอา
หลักการของ Embedded Method คือ การที่เราหยิบมันมาให้หมดนั่นแหละ แต่เราจะให้น้ำหนักของแต่ละ Feature ไม่เท่ากัน บาง Feature คำนวณออกมา อาจจะทำให้ Weight เป็น 0 เลยก็มีเหมือนกัน (ง่าย ๆ คือ แก โดน ทิ้ง ว้ายย นก !) วิธีนี้เราเรียกว่า การทำ Regularisation
ที่เราใช้ ๆ กันก็จะเป็น LASSO (L1), Ridge Regression (L2) และ เอาให้มันส์เข้าไปอีกด้วย Elastic Net ที่จะใช้ค่าของทั้ง L1 และ L2 เข้ามา Predict ร่วมกัน เราขอไม่ลงไปเล่าละกันว่า มันอะไรยังไงคือเลขเยอะมาก ถ้าไม่ได้คิดอะไรมาก ใน scikit-learn ได้ Implement มาให้เราเรียกใช้ได้เลยนะ
ใช้วิธีไหนดี ?
จริง ๆ ก็ตอบยากนะว่า ควรจะใช้วิธีไหนดี เพราะแต่ละวิธีนางก็มีความดีในตัวอยู่ อย่าง Filter Method นางก็จะค่อนข้างเลือก Feature ที่ความ Overfit ต่ำกว่าอีก 2 วิธีที่เหลือ เพราะนางใช้ความสถิติในการเลือก แต่กลับกัน เพราะแบบนั้นแหละ มันเลยทำให้เวลาเราจะตีความต่าง ๆ มันก็ยาก ออกมาบางทีคือแบบ Feature ที่เลือกมา ไม่มีบ้าอะไรเกี่ยวกันเลย งงไปหมด
หรือถ้าจะเป็น Wrapper Method มันก็จะได้ Feature ที่น่าจะตีความได้ง่ายกว่า แต่ ๆๆ ความเกิด Overfitting ก็คือเยอะอยู่เหมือนกัน นอกจากนั้น กว่าจะได้คือ นางก็ต้องลอง ๆ เพิ่ม ๆ ตัด ๆ ไปเรื่อยซึ่งมันก็กินเวลานานมาก
ทำให้วิธีสุดท้ายคือ Embedded Method ก็เข้ามาช่วย หลัก ๆ มันก็ทำให้เราได้ Feature ที่พอจะตีความเล่าเรื่องโม้เหม็นได้แหละ แต่ Overfitting ก็ไม่ต่างจาก Wrapper เท่าไหร่ แต่ความเร็วก็ต่างเลยละ เพราะมันไม่ได้มานั่งลอง ๆ หลาย ๆ รอบอย่าง Wrapper Method
ถ้าถามเราว่า เราจะแนะนำวิธีไหน ส่วนใหญ่ เราจะใช้ทั้ง Filter และ Wrapper เลย คือ เราจะ Filter Feature ที่มันไม่น่ารอดออกไปก่อน คือขนาดเราทำ Univariate แล้วมันไม่น่ารอดหนัก ๆ เลย Multivariate ก็น่าจะรอดยาก จากนั้นเราก็เอาที่รอดจากการ Filter มาทำ Wrapper ต่ออีกทอดถ้า Feature ยังมีจำนวนเยอะอยู่ ส่วน Embedded เราไม่ค่อยได้ใช้เท่าไหร่ เพราะเรารู้สึกว่าวิธีที่เราว่ามันก็ทำให้เราได้ Feature เพียงพอตามที่ต้องการ และให้ Statistical Power ต่อจำนวน Feature และ ข้อมูล มากพอที่เราต้องการแล้ว
สรุป
Feature Selection เป็นเทคนิคในการลดจำนวน Feature ลงเพื่อให้เวลาเราเอาไปสร้าง Model แล้วมันจะไม่ตาย ไม่ก็ Overfitting เพราะ จำนวน Dimension ที่มากเกินไป
ทั้งหมดที่เราเล่าไปก็เป็นวิธีเบื้องต้นในการเลือก Feature จริง ๆ มันยังมีอีกหลายวิธีในการเลือกที่เราไม่ได้เอามาเล่าอย่าง Boruta และ Simulated Annealing (ยังไม่เคยเอามาทำ Feature Selection เหมือนกัน ได้ยินมาจากคนอื่นอีกที) หรือ เผลอ ๆ เราสามารถสร้าง Feature ใหม่จาก Feature ที่มีอยู่แล้วก็อาจจะทำได้เหมือนกัน หรือถ้าเรามีความรู้ในข้อมูลที่เราทำอยู่แล้ว เราก็อาจจะใช้ความรู้นั้นในการบอกว่า อันไหนสำคัญ หรืออันไหนไม่สำคัญ (ถ้าในเชิงวิชาการก็คือ ให้แกไปทำ Literature Review มาก่อนนั่นแหละ)
เราอาจจะไม่ได้เข้าไปเล่าในเชิงลึกถึงสมการอะไรมาก เพราะอยากให้ย่อยข้อมูลได้ง่ายที่สุด ถ้าอยากให้เราลงลึกก็ Comment มาให้เพจได้ ถ้ามีเยอะ เราจะเขียนให้เป็นอีกตอน จริง ๆ อยากเขียนมาก แต่กลัวว่ามันจะย่อยยากเลย เห้อออ...
Related Posts

วิธีการและเทคนิคการ Capture เรื่องราวด้วย Obsidian
01 พฤษภาคม 2026 - 2 min readหนึ่งขั้นตอน Workflow ของ PKM ที่เป็นเหมือนการนำเข้าวัตถุดิบมาปรุงเป็นไอเดียดี ๆ ในอนาคต คือ การ Capture สิ่งที่เราได้เรียนรู้ หรือได้รับฟัง ดู อ่าน เข้ามา วันนี้เราจะมาเล่าวิธีการที่เราใช้กับ Obsidian กันว่า เราทำอย่างไร เพื่อให้ Workflow นี้ง่าย และเหมาะกับการใช้งานของเราที่สุด...

สร้าง WebAssembly Module แรกกันเถอะ
21 เมษายน 2026 - 2 min readจากบทความที่แล้ว ที่มาแนะนำ WebAssembly ไปว่า มันเป็นอะไรที่ค่อนข้างน่าสนใจ และน่าเรียนรู้เอาไว้มาก ๆ วันนี้เราจะมาพาทุกคนไปสร้าง WebAssembly Module แรกกัน และเทียบกันไปเลยว่า Performance ในงานที่ CPU Bound มาก ๆ มันจะห่างกันขนาดไหน...

Self-Hosted Service บน Home Lab จัดการอย่างไรให้ปลอดภัย
16 เมษายน 2026 - 3 min readช่วงหลัง ๆ กระแสการทำ Home Lab ฮิตขึ้นมาก ๆ ในประเทศไทยเรา มีคนถามเข้ามาเยอะมากว่า แล้วเราจะจัดการอย่างไรให้ระบบของเราปลอดภัยมากที่สุด วันนี้เราจะมารวบรวมวิธีคิดการวางสถาปัตยกรรมแบบ Defense-in-Depth สำหรับงาน Self-Hosting ง่าย ๆ กัน...

Functional Programming คืออะไร ? ทำไมมันถึงเป็นเรื่องที่น่าสนใจในยุคใหม่
11 เมษายน 2026 - 2 min readก่อนหน้านี้ไม่ค่อยได้สนใจการเอา Functional Programming มาใช้ในงานเท่าไหร่ แต่พอได้ลิ้มรสเท่านั้นแหละ มันเหมือนโลกใหม่มาก ๆ เข้ามาแก้ปัญหาหลาย ๆ อย่างที่เคยได้เจอมา วันนี้เราจะมาเล่ากันว่า มันคืออะไร และ มันน่าจะเหมาะกับงานไหนกัน...