ปั่นความเร็ว Python Script เกือบ 700 เท่าด้วย JIT บน Numba
By Arnon Puitrakul - 24 มีนาคม 2023

Python เป็นภาษาที่เราใช้งานกันอย่างแพร่หลายมาก ๆ โดยเฉพาะเรื่องของการเอาไปทำงานที่ต้องอาศัยการคำนวณเยอะมาก ๆ เพราะเป็นภาษาที่เข้าใจง่าย ค่อนข้าง High-Level ทำให้ผู้เขียนสามารถ Focus กับ Logic และวิธีการคำนวณได้มากขึ้น แต่ปัญหาหลัก ๆ ก็ยังอยู่ที่ตัวภาษา Python เองที่ยังทำงานได้ค่อนข้างช้า เมื่อเทียบกับภาษาอื่น ๆ อย่าง C++ อยู่ แต่วันนี้เราจะมาปั่นความเร็วกันแบบ 300% ด้วย Numba กัน
ทำไม Python เป็นภาษาที่ช้า ?
เราได้ยินมาเยอะมาก ๆ ว่า Python อย่าไปใช้มันนะ มันทำงานได้ช้ามาก ๆ แต่เราจะบอกว่า ถ้าเทียบกับภาษาอื่น ๆ เช่น C++, Go และอื่น ๆ อีกมากมาย มันก็ช้าจริง ๆ แหละ แต่ไม่ได้เป็นเพราะ Python มันออกแบบมาไม่ดีนะ แต่เพราะมันอนุญาติให้มีความยืดหยุ่นในการทำงานที่สูง เลยทำให้ จุดเด่นมาก ๆ ของ Python เป็นดาบสองคมที่ทำให้มันช้ากว่านั่นเอง
ตัวอย่างของความยืดหยุ่นที่เราพูดถึง เช่นพวก การเลือกใช้ Dynamic Type Variable นั่นแปลว่า พวกงานอย่าง Type Safety Check ทั้งหลาย เราจะต้องทำตอน Runtime เท่านั้น ทำให้มันช้าเข้าไปอีก
 Arnon Puitrakul
Arnon Puitrakul
วิธีการที่ทำให้ Python มันทำงานได้ยืดหยุ่นมาก ๆ เป็นเพราะ แทนที่เราจะเอา Code ของเราแปลงเป็น Machine Code ที่เครื่องเข้าใจแล้วรัน ๆ ไปเรื่อย ๆ เหมือนภาษาอื่น ๆ แต่ขาดความยืดหยุ่นในการทำงาน เลยเลือกใช้พวก Interpretator หรือ ให้โปรแกรม Interpretator เข้าไปอ่าน Script ของเรา แล้วทำตามไปเรื่อย ๆ เบื้องหลังของมันก็คือ การแปลง Script ของเราไปเป็น Machine Code เพื่อให้เครื่องเข้าใจทีละบรรทัดแบบนี้ไปเรื่อย ๆ นั่นแปลว่า มันก็จะช้ากว่าภาษาอื่น ๆ ที่เลือกใช้โปรแกรม Compiler ทำการแปลง Source Code หรือ Script ให้กลายเป็น Machine Code อยู่ก่อนแล้ว (ยังไม่นับพวก Type Checking ที่ต้องทำหน้างาน แต่พวกภาษาที่ใช้ Compiler เขาเรียบร้อยตั้งแต่ตอนเรา Compile แล้ว)
เราจะเร่งความเร็วในการทำงานบน Python ได้ยังไงบ้าง ?
ในเมื่อเราบอกว่า Python ช้ากว่าพวกภาษาที่ใช้ Compiler เพราะมันใช้ Interpretator งั้นเอางี้ดีกว่า ในเมื่อข้อดีของ Python มันคือความยืดหยุ่น เพื่อให้เร็วขึ้น เราไม่อยากเสียข้อดีเด่น ๆ ของเราไป งั้นเราเอางี้มั้ย ในเมื่องานบางอย่าง เราทำบ่อย ๆ อยู่แล้ว งั้นเราจัดการทำมันให้เป็น Machine Code ก่อน แล้วเราเขียนเป็นเหมือน API บน Python ให้เข้าไปใช้งานได้ดีมั้ย
Arnon Puitrakul
หลักการนี้แหละ คือ หลักการที่พวก Library หลาย ๆ ตัวที่เราใช้งานบน Python ทำกัน เช่น Numpy ไส้ในของมันก็คือ C++ นี่แหละ เราเคยเล่าไปแล้วในบทความนี้ นั่นทำให้มันทำงานได้โคตรจะเร็วเลย ตราบใดที่เราทำงานอยู่ภายใต้ Numpy อะนะ แล้วถ้าเราเริ่มใช้ตัว Python เสริม ๆ ละ ไม่ต้องลองเลย เราบอกให้เลยนะ ช้ากว่าเขียนใน C แน่นอนแบบไม่ต้องสงสัย
เลยทำให้เกิดคำถามว่า แล้วเราจะทำยังไงให้เรายังเขียน Python ได้อยู่ โดยที่มันทำงานได้เร็วพอ ๆ กับการเขียน C อยู่ดี เรารู้ว่าปัญหามันเกิดจาก Interpretator ใช่ป่ะ งั้นถ้าเราบอกว่า เราสามารถ Compile บางส่วนของ Python เราให้เป็น Machine Code ได้ละ ไม่ผ่าน Interpretator แล้ว โดยเฉพาะส่วนที่เราเรียกบ่อย ๆ แปลว่า ถ้าเราแปลงส่วนนึงของโปรแกรมเราเป็น Machine Code ไปแล้ว เราเรียกซ้ำ ก็จะเร็วได้พอ ๆ กับเราเรียก Machine Code ที่ผ่าน C Compiler มาเลยใช่ป่ะ
เกริ่นมาตั้งนาน นี่แหละคือหลักการของ Library ที่ชื่อว่า Numba
Numba ทำงานยังไง ?
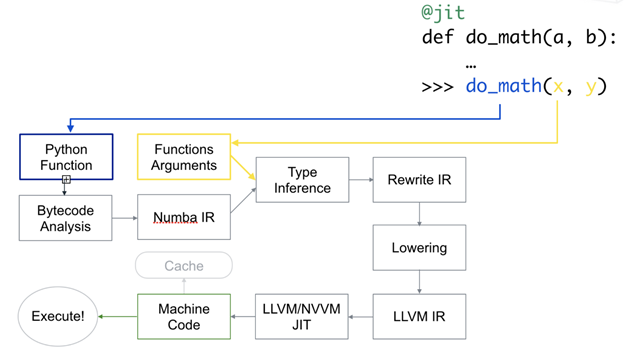
สิ่งที่ Numba มันทำคือ มันจะใช้ JIT (Just-in-Time) Compiler ในการช่วยแปลงให้เป็น Machine Code ที่ทำให้เราไม่ต้องทำงานผ่าน Interpretator เลย สิ่งที่มันทำคือ มันจะแยกส่วนการทำงานกันนะ ระหว่าง Function และ Argument โดยที่พวก Function มันจะแปลงออกมาเป็น รูปแบบที่ Numba เข้าใช้ หรือ Numba IR (Intermediate Representation) ส่วนตัว Argument ที่ยัดเข้ามา มันก็จะเอาเข้าไปจัดการเรื่อง Data Type แล้วเอามารวมกันเป็น IR ตัวใหม่ แต่ Numba ไม่ใช้ Compiler ของตัวเอง ไปเลือก LLVM ที่โหดเอาเรื่อง
ปัญหาคือ LLVM อ่าน Numba IR ไม่รู้เรื่อง คนทำ Numba เลยต้องเขียนตัวแปลง ให้กลายเป็น LLVM IR เพื่อให้ LLVM ที่เป็น Compiler อ่านรู้เรื่อง แล้วเอาเข้า Compiler อย่าง LLVM เราก็จะได้ Machine Code ออกมา แล้วถึงจะเอามาทำงานได้ นี่แหละ คือหลักการของ Numba ว่ามันทำงานยังไง
เมื่อมันใช้ LLVM ที่ใช้งานกันอย่างกว้างขวาง เราบอกเลยว่า มันทำให้ Numba มันพาความอร่อยหอมกลิ่นการ์ดจอมาด้วย เพราะ Nvidia เอง พวก Compiler สำหรับ Nvidia GPU เอง เขาก็ใช้ LLVM แปลว่า ถ้าเราเปลี่ยน Compiler ไปใช้ Nvidia LLVM เราก็สามารถ Compile แล้วเอาไปรันบน GPU ได้ด้วย แน่นอนว่า ถ้าใครที่รู้ก็คือ มองเห็นความเร็วแบบพระเจ้าแล้วใช่มั้ย ยิ่งถ้าเราทำงานกับพวก Numpy Array มันสามารถกระจายแต่ละ Element ไปตาม GPU Core แล้ว Apply Function ลงไปได้เลย ทำให้ความเร็วมันโหดขึ้นแบบ ซวดยอดไปเล้ยยยยย
นั่นแปลว่า การที่เราจะต้องใช้พวก CUDA API หรือพวกการเขียนโปรแกรมพิเศษที่เข้าถึงพวก Core บน Nvidia GPU บน C ที่มันแอบยุ่ง ๆ เราสามารถใช้เจ้านี่แทนได้เลย โดยเฉพาะการคำนวณขนาดใหญ่ ๆ เยอะ ๆ มันช่วยได้แบบ สุด ๆ อะบอกเลย เพราะงานที่เราทำทาง Bioinformatics ที่คำนวณหนักมาก ๆ อย่างพวก Genome Assembly ก็พึ่งการใช้งานพวกนี้แหละในการ Accelerate Computation
Let's Benchmark
Arnon Puitrakulเพื่อความง่าย เราจะใช้โจทย์เดิม จากบทความที่เราทดสอบการทำงานของ Python เทียบกับ C ด้านบนนี้เลย คือ เราจะให้มันหาค่าเฉลี่ยจากตัวเลขที่ Random ขึ้นมา ทั้งหมด 10 ล้านตัวด้วยกัน วิธีการคือ เราก็วน Loop Random แล้วเอามาบวกกันเก็บไว้ สุดท้าย เราก็จะเอามาหารด้วย 10 ล้าน ก็จะได้คำตอบออกมา Simple เรียบง่ายเนอะ
import numpy as np
def random_mean (num_size:int) :
sum = 0
for _ in range(num_size) :
sum += np.random.randint(1,1_000)
return sum / num_sizeดังนั้น Function มันก็จะออกมาหน้าตาแบบนี้เลย คือ ธรรมดา ทำตามที่เราเล่าไปใช่ป่ะ
from numba import int32, jit
@jit (int32(int32))
def random_mean_jit (num_size:int) :
sum = 0
for _ in range(num_size) :
sum += np.random.randint(1,1_000)
return sum / num_sizeส่วนของ JIT ใน Numba เราสามารถใช้งาน JIT ได้ง่าย ๆ เลยโดยการที่เรา Import Decorator ชื่อว่า jit เข้ามา แล้วก็ใช้งานได้เลย แต่ใน Numba ด้วยความที่มันจะต้องแปลงเป็น Machine Code ทำให้เรื่อง Data Type สำคัญมาก ๆ ถ้าเราไม่ใส่เลย มันจะต้องมาหาเอง ทำให้เราจะบอกมันด้วยว่า สิ่งที่เรา Return กลับมา และ Argument ที่เราจะยัดเข้าไปมันเป็น Data Type อะไร ในที่นี้ด้วยความที่มันเป็นตัวเลขปกติ เราเลยเลือกใช้เป็น 32-bits Integer นั่นเอง
np.random.randint(1000, size=10_000_000).mean()และสุดท้าย พ่อทุกสถาบัน Numpy แบบเพียว ๆ เลย เราขอเรียกว่า Vanilla Numpy ละกัน อันนี้ทำเหมือนกับ Function ก่อนหน้าที่เราเขียนกันเลย แต่มันมี Built-in ใน Numpy มาให้ เราก็เรียกใช้งานมันตรง ๆ เลย
JIT Elapsed 0.016052208000000012 sec(s)
Vanilla Numpy Elapsed 0.039746375 sec(s)
Normal Elapsed 11.520809667 sec(s)ผลออกมา บอกตรง ๆ ว่า ตกใจเหมือนกันนะ เริ่มจาก ตัว JIT กับ ปกติก่อน อันนี้เราคาดหวังแล้วละว่า ยังไง ๆ JIT เร็วกว่าเห็น ๆ อยู่แล้ว แต่ก็คือความเร็วห่างกันเกือบ ๆ 700 เท่าได้เลย แต่อันที่ผิดคาดมาก ๆ คือ Numpy เราคิดว่า มันน่าจะเร็วกว่า JIT ปรากฏว่า JIT เร็วกว่าไปเลย 3 เท่าตัว
คู่แรกคือ คู่ของ JIT และตัวปกติ ที่มันเร็วกว่า จริง ๆ ก็ต้องขอบคุณ JIT ที่ทำให้ Script ที่เราเขียนมันไม่ต้องผ่าน Interpretator ที่เป็นส่วนสำคัญที่ทำให้มันทำงานได้ช้า ประกอบกับ Script ตัวนี้ ถ้าเราสังเกตการทำงานของมัน มันจะมี Loop ถ้าเราคิดจากการทำงานของ Interpretator เราจะเดาได้ไม่ยากเลยว่า Interpretator แพ้ Loop ยิ่ง Loop รอบเยอะเท่าไหร่ยิ่งช้ากว่ามากเท่านั้น ซึ่งตัวอย่างนี้ เราจะเห็นเลยว่า เรา Loop ไป 10 ล้านรอบอะ ทำให้ความห่างชั้นมันเห็นขนาดนี้ไปเลย ซึ่งถามว่าในการใช้งานจริง มันใช้แบบนี้มั้ย เราต้องบอกเลยว่ามันมีอยู่จริง ๆ โดยเฉพาะการคำนวณทาง Numerical Method ที่เราอาจจะจำเป็นต้องวน ๆ หลาย ๆ Iteration เพื่อให้ได้ผลลัพธ์ที่ดีที่สุด อันนี้ก็คือ กินขาดไปเลย ระเบิดเวลาอ๊ากกกกกก ไปอีก
แต่เมื่อเราเอา JIT มาเทียบกับ Numpy เอง เราจะเห็นว่า ใช่ Numpy ช้ากว่า แต่ไม่ได้เป็นเพราะ Numpy กาก เขียนมาไม่ดีนะ แต่เป็นเพราะยังไง ๆ เราก็เข้าถึง Numpy ด้วย Python Interpretator อยู่ดี แค่ว่า ส่วนที่เราประมวลผลเยอะ ๆ เรายกไปทำงานใน C เท่านั้นเอง ทำให้สุดท้ายแล้วยังไงก็ช้ากว่า การที่เราโยน JIT เข้าไปแล้วแปลงเป็น Machine Code แล้วโลดแล่นอยู่ดี วิธีที่จะเร็วสู้และอาจจะเร็วกว่า ก็คือ การเอา API บน C ของ Numpy มารันสู้ อาจจะได้ก็ได้นะ
เร็วขนาดนี้ ใช้กับอะไรไม่ได้บ้างละ
อย่างที่เราบอกไปว่า Numba ชอบอะไรที่ซ้ำ ๆ Premitive หน่อย ๆ โดยเฉพาะ Numpy Array มันรักส์เลยละ แต่ถ้าเราเริ่มใช้กับงานที่มันไม่ได้รัน Loop ซ้ำ ๆ อย่างการคำนวณครั้งเดียวจบ อันนี้ JIT จะเริ่มไม่ตอบโจทย์ละ อันนั้นเราว่า เขียนปกติ เร็วกว่า ง่ายกว่าเยอะ
ส่วนพวกอะไรที่มันไม่ Premitive หรือก็คืออะไรที่มันไม่มีใน C อะ เช่น Pandas Dataframe พวกนี้มันจะแปลงออกไปไม่ได้ ทำให้มันจะทำการ Fallback ไปทำงานผ่าน Interpretator เหมือนเดิม ทำให้ Performance ที่ควรจะดีขึ้นกลับเท่าเดิมหรือแย่กว่าเดิมด้วยซ้ำ เพราะ Numba มันก็มี Overhead ของมันอยู่ดังในขั้นตอนการทำงานที่เราเล่าไปก่อนหน้า
สรุป
Interpretator ที่เป็นข้อดีของ Python ในการสร้างความยืดหยุ่น และความง่ายในเรียนรู้ แต่มันก็เป็นข้อเสียเมื่อเราต้องการ Performance มันโหด ๆ ต้องการทำ Number Cruncher แบบดุ ๆ เดือด ๆ วิธีนึงที่เราแนะนำในวันนี้คือ การใช้ JIT (Just-in-Time) Compiler ที่ Numba นำเสนอมาให้เรา จากการ Benchmark เราจะเห็นได้เลยว่า มันทำงานได้เร็วมาก ๆ เร็วกว่า การเรียก Numpy ที่เบื้องหลังการทำงานเป็น C ซะอีก ทำให้ ถ้าเราต้องเขียนอะไรที่เรามีการเรียกพวก Loop เยอะ ๆ อันนี้แหละ จะเป็นวิธีที่ดีมาก ๆ ในการเร่งความเร็วการทำงานให้เร็วขึ้นไปอีก หรือกระทั่ง เราสามารถใช้มันเป็นสะพานเชื่อมเราให้ไปทำงานบน Nvidia GPU ได้อีกด้วย ทำให้การทำงานมันเร็วขึ้นทวีคูณเข้าไปอีกด้วย บอกเลยว่า ถ้าใครทำงานที่ต้องคำนวณตัวเลขเยอะ ๆ เป็นอะไรที่น่าทดลองใช้เอามาก ๆ เลยละ
Related Posts

วิธีการและเทคนิคการ Capture เรื่องราวด้วย Obsidian
01 พฤษภาคม 2026 - 2 min readหนึ่งขั้นตอน Workflow ของ PKM ที่เป็นเหมือนการนำเข้าวัตถุดิบมาปรุงเป็นไอเดียดี ๆ ในอนาคต คือ การ Capture สิ่งที่เราได้เรียนรู้ หรือได้รับฟัง ดู อ่าน เข้ามา วันนี้เราจะมาเล่าวิธีการที่เราใช้กับ Obsidian กันว่า เราทำอย่างไร เพื่อให้ Workflow นี้ง่าย และเหมาะกับการใช้งานของเราที่สุด...

สร้าง WebAssembly Module แรกกันเถอะ
21 เมษายน 2026 - 2 min readจากบทความที่แล้ว ที่มาแนะนำ WebAssembly ไปว่า มันเป็นอะไรที่ค่อนข้างน่าสนใจ และน่าเรียนรู้เอาไว้มาก ๆ วันนี้เราจะมาพาทุกคนไปสร้าง WebAssembly Module แรกกัน และเทียบกันไปเลยว่า Performance ในงานที่ CPU Bound มาก ๆ มันจะห่างกันขนาดไหน...

Self-Hosted Service บน Home Lab จัดการอย่างไรให้ปลอดภัย
16 เมษายน 2026 - 3 min readช่วงหลัง ๆ กระแสการทำ Home Lab ฮิตขึ้นมาก ๆ ในประเทศไทยเรา มีคนถามเข้ามาเยอะมากว่า แล้วเราจะจัดการอย่างไรให้ระบบของเราปลอดภัยมากที่สุด วันนี้เราจะมารวบรวมวิธีคิดการวางสถาปัตยกรรมแบบ Defense-in-Depth สำหรับงาน Self-Hosting ง่าย ๆ กัน...

Functional Programming คืออะไร ? ทำไมมันถึงเป็นเรื่องที่น่าสนใจในยุคใหม่
11 เมษายน 2026 - 2 min readก่อนหน้านี้ไม่ค่อยได้สนใจการเอา Functional Programming มาใช้ในงานเท่าไหร่ แต่พอได้ลิ้มรสเท่านั้นแหละ มันเหมือนโลกใหม่มาก ๆ เข้ามาแก้ปัญหาหลาย ๆ อย่างที่เคยได้เจอมา วันนี้เราจะมาเล่ากันว่า มันคืออะไร และ มันน่าจะเหมาะกับงานไหนกัน...