Ensemble Learning คืออะไร
By Arnon Puitrakul - 29 ตุลาคม 2020
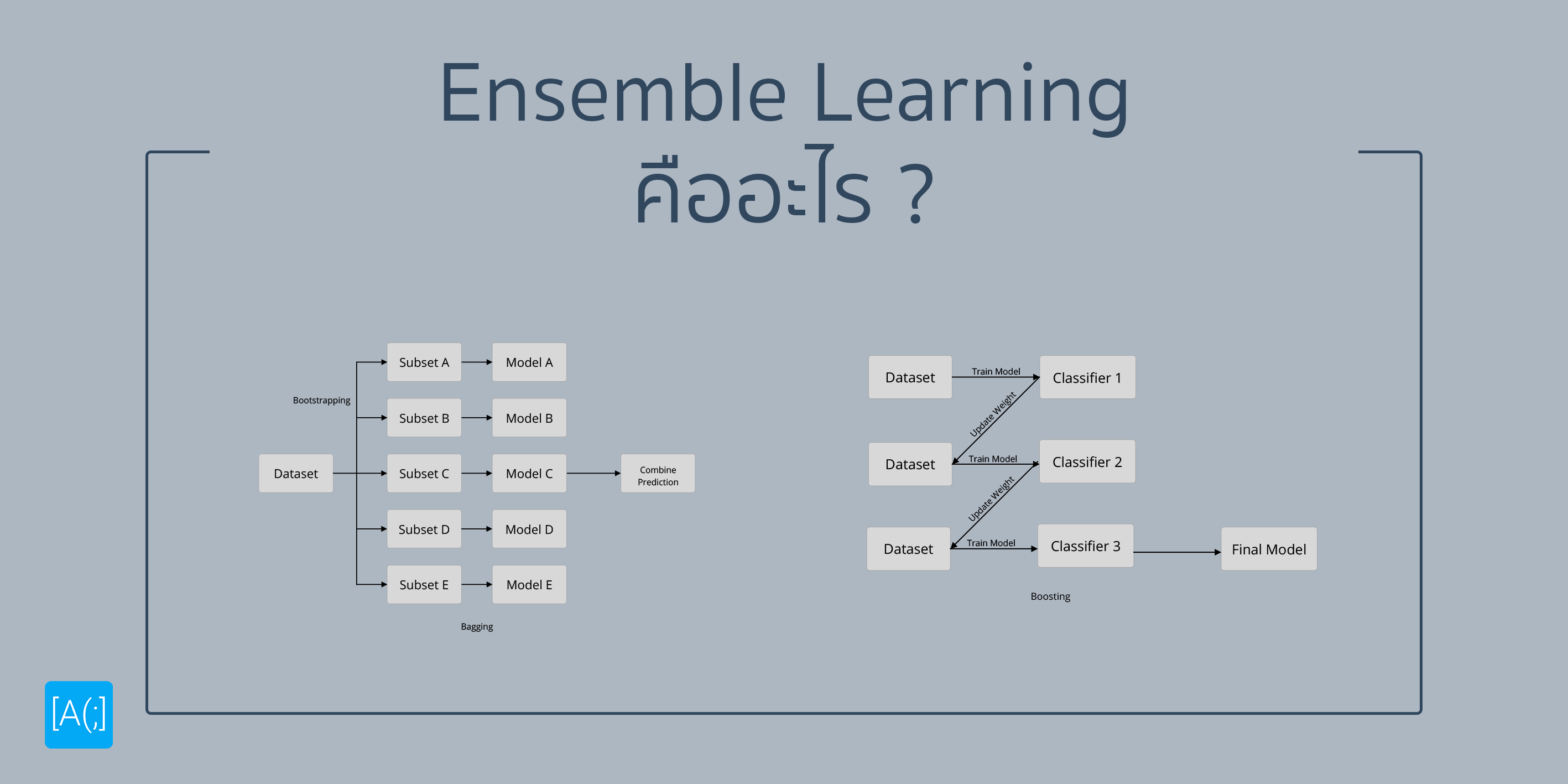
Ensemble Learning เป็นเทคนิคที่ถูกนำมาใช้ในการทำ Model ที่มีประสิทธิภาพหลายตัวมามาก เพราะเป้าหมายของมันคือการเพิ่ม Performance ให้กับ Model เป็นหลัก ซึ่งหลัก ๆ ที่เรานิยมกัน ก็จะมี Bagging และ Boosting เป็นหลัก วันนี้เราจะมาทำความเข้าใจกันว่ามันคืออะไรกันแน่
Ensemble Learning คืออะไร
เพื่อให้เข้าใจง่าย ๆ เราอยากจะยกตัวอย่างเหตุการณ์สมมุติใกล้ตัวละกัน เราเอง เราเขียน บทความขึ้นมา เราอยากจะรู้ว่า เราเขียนแล้วอ่านรู้เรื่องมั้ย วิธีแรก เราก็อาจจะส่งไปให้เพื่อนเราช่วยอ่าน เพื่อนเราก็จะให้ข้อคิดเห็นกลับมาว่า มันยังไง ว่าซั่น แต่ก็นะ ถ้าเราเลือกเพื่อนที่ Expert มาก ๆ มาอ่าน ก็จะบอกว่า อ่านรู้เรื่อง แต่พอเอาเข้าจริง อ้าว คนอื่นอ่านไม่รู้เรื่อง แบบนี้ก็แย่เลย นี่คือตัวอย่างของการทำ Model ปกติ
ดูท่าจะยาก เอาใหม่ ๆ งั้นเราเขียนแล้ว ลงบทความเลยละกัน แล้วบอกว่า เออ ช่วย Comment มาหน่อยว่าอ่านรู้เรื่องมั้ย (Comment มาด้วย จะดีมากฮ่า ๆ) จากเดิมที่เพื่อนเราคนเดียวช่วยอ่าน ก็จะมีหลายพันคนเข้ามาช่วยกันอ่าน เราจะได้ความเห็นที่หลากหลายมากขึ้น จากตรงนี้ทำให้เราเห็นว่า การที่คนช่วยกันอ่านมากขึ้น มันก็ทำให้การทำงานได้ดีขึ้นนั่นเอง
ในเชิงของ Machine Learning ก็เช่นเดียวกัน ปกติ ถ้าเราสร้าง Model เดียว มันก็เหมือนกับ เราเอาไปถามเพื่อนคนเดียวแหละ อาจจะ Expert มาก จนอ่านรู้เรื่องไปหมด หรือ อาจจะไม่กล้าให้คำตอบจริง ๆ กับเรา แต่ Ensemble Learning เป็นการใช้หลาย ๆ Model ในการทำงาน เพื่อให้ได้ประสิทธิภาพที่ดีขึ้นนั่นเอง
ที่นิยมทั่วไป เราจะใช้เทคนิคการทำ Ensemble Learning อยู่ 2 เทคนิคด้วยกันคือ Bagging และ Boosting ที่จะมีความแตกต่างในการทำงานพอตัว
Bagging
เริ่มจาก Bagging กันก่อน ในเทคนิคนี้ มันเหมือนกับเราเอาบทความของเราไปถามคนพันคนพร้อม ๆ กันเลยว่าอ่านรู้เรื่องมั้ย (เชื่อว่าคนที่อ่านมาถึงตอนนี้ก็คือ กำหมัดบอกว่า ไม่รู้เรื่อง ไปแล้ว) ในโลกแห่งความเป็นจริง มันเป็นวิธีที่เวลาเราเอาไปใช้จริงมันไม่น่ามีปัญหา เว้นแต่เราจะหาคนไม่ได้นั่นอีกเรื่อง
แต่ในเครื่องคอมพิวเตอร์ คน ที่เราเอามาเทียบ มันก็คือ Model ทีนี้ ถ้าเราบอกว่า เราอยากจะที่จะให้หลาย ๆ Model มาช่วยกันตัดสินใจออกมา และเราใช้ Model ที่สร้างจาก Parameter และ ข้อมูลเดียวกัน มันก็ไม่แปลกอะไรเลยที่มันจะได้ผลลัพธ์เหมือนกัน ดังนั้น สิ่งสำคัญมาก ๆ คือ Model จะต้องไม่เหมือนกัน ถ้าเอาง่ายแบบไม่คิดอะไรเลย เราก็จับมัน Random แล้วเราก็แบ่งเป็นชุด ๆ แล้วเอาไปทำ Model ก็น่าจะออกมาไม่เหมือนกันละ แต่แหม่ Random มันก็ทำให้ผลที่ได้มันก็ Random ไปด้วยแหละ เพื่อให้มันออกมาไม่ Random มากเราก็อาจจะใช้เทคนิคที่เรียกว่า Bootstrapping ได้ เพื่อให้แต่ละส่วนของ Dataset ที่แบ่งออกมา มีความคล้ายกับ Dataset เต็ม ๆ
หลังจากที่เราได้ Data หลาย ๆ ชุดมาแล้ว เราก็เอามันไปทำออกมาเป็น Model และให้พวกนี้แหละตัดสินใจร่วมกัน แล้วมันจะตัดสินใจร่วมกันอย่างไรละ ? เอาง่าย ๆ เลย มันก็จะมีอยู่ 2 วิธีด้วยกันคือ Averaging และ Voting ก็ตามชื่อเลยคือ การหาค่าเฉลี่ยออกมา และ การโหวต เพื่อให้มันได้ผลสุดท้ายออกมานั่นเอง
การทำแบบนี้มีข้อดีอย่างนึงคือ เราสามารถที่จะ Parallel การทำงานได้ง่ายมาก ๆ เพราะหลักการจริง ๆ มันคือการสร้าง Model หลาย ๆ ตัวที่มันไม่เหมือนกัน เราก็จับ Parallel ได้ง่ายกว่าเยอะ
Boosting
ส่วน Boosting จะเหมือนกับเราเขียนแล้วเอาไปคนนึงอ่านแล้วกลับไปแก้ แล้วให้อีกคนอ่าน ไปเรื่อย ๆ ไส้ในของมันคือ การที่เราเอา Dataset ของเรามา และ เริ่มต้นให้มันมี Weight เท่ากันก่อน เอาไปสร้างเป็น Model และ ปรับน้ำหนักจากผลของ Model ทำแบบนี้ไปเรื่อย ๆ มันก็จะทำให้ Model ของเราทำงานได้ดีขึ้นเรื่อย ๆ
เล่าให้ง่ายขึ้นคือ Model ตัวต่อไป มันก็จะพยายามแก้ปัญหาของ Model เก่าไปเรื่อย ๆ ถ้าเราเอา Model ตัวสุดท้ายมาใช้เลยมันก็ไม่น่าจะมีปัญหาใช่ม่ะ ผิด!! นึกถึงตัวเราเอา ที่แก้ A แล้ว B ก็ผิด พอแก้ B เอ้า A ก็กลับมาผิดอีก นั่นแปลว่า Model แต่ละตัว ก็จะมีความเก่าไม่เหมือนกัน ดังนั้นสิ่งที่ Boosting ทำก็คือ เอาทั้งหมดนั่นแหละ มาใช้ มันก็จะทำให้ประสิทธิภาพมันดีขึ้นแน่ ๆ
วิธีนี้เป็นที่นิยมในการทำงานมาก เพราะมันเป็นวิธีที่ค่อนข้างยืดหยุ่น และ สามารถใช้ได้กับ Learning Method ที่ค่อนข้างหลากหลาย ในขณะที่ปรับลด Bias ของ Model ได้ดีมาก
ใช้ Bagging หรือ Boosting อันไหนดีกว่ากัน ?
โห ถามมาแบบนี้ ตอบยากเลย เอาจริง ๆ เราว่ามันไม่มีวิธีไหนใน 2 อย่างนี้ที่ดีกว่ากันหรอก มันต้องเอาไปปรับใช้กับข้อมูลของเรา บางทีข้อมูลของเรามันอาจจะชอบ Bagging หรือ Boosting ก็ได้
แต่สำหรับเราเอง ถ้าเราอยู่หน้างาน แล้วเราต้องเลือกจริง ๆ เราจะเลือกลอง Bagging ก่อน เพราะมันทำงานเป็น Parallel ทำให้เราได้ผลน่าจะเร็วกว่าการทำงานแบบ Sequential อย่าง Boosting แน่ ๆ ก็ต้องลองเลือก ๆ ใช้กันดู
สรุป : ลองใช้ดู ไม่เสียหาย
Ensemble Learning คือ เทคนิคที่นำหลาย ๆ Model มาทำงานร่วมกัน เพื่อให้ได้ประสิทธิภาพสูงที่สุดเราอาจจะนำ Model ที่สร้างจากหลาย ๆ วิธีมาช่วยกันก็ได้ วันนี้เรามาเล่าเรื่อง Bagging และ Boosting ที่เป็น 2 วิธีในการที่เราทำ Ensemble Learning ก็น่าจะทำให้หลาย ๆ คนเห็นภาพได้ดีขึ้น ส่วนถ้าอยากได้ที่เป็น Math เลย ก็ต้องลองไปหาอ่านเพิ่มดู วันนี้เรามาเป็นพื้นฐานให้เฉย ๆ
Related Posts

วิธีการและเทคนิคการ Capture เรื่องราวด้วย Obsidian
01 พฤษภาคม 2026 - 2 min readหนึ่งขั้นตอน Workflow ของ PKM ที่เป็นเหมือนการนำเข้าวัตถุดิบมาปรุงเป็นไอเดียดี ๆ ในอนาคต คือ การ Capture สิ่งที่เราได้เรียนรู้ หรือได้รับฟัง ดู อ่าน เข้ามา วันนี้เราจะมาเล่าวิธีการที่เราใช้กับ Obsidian กันว่า เราทำอย่างไร เพื่อให้ Workflow นี้ง่าย และเหมาะกับการใช้งานของเราที่สุด...

สร้าง WebAssembly Module แรกกันเถอะ
21 เมษายน 2026 - 2 min readจากบทความที่แล้ว ที่มาแนะนำ WebAssembly ไปว่า มันเป็นอะไรที่ค่อนข้างน่าสนใจ และน่าเรียนรู้เอาไว้มาก ๆ วันนี้เราจะมาพาทุกคนไปสร้าง WebAssembly Module แรกกัน และเทียบกันไปเลยว่า Performance ในงานที่ CPU Bound มาก ๆ มันจะห่างกันขนาดไหน...

Self-Hosted Service บน Home Lab จัดการอย่างไรให้ปลอดภัย
16 เมษายน 2026 - 3 min readช่วงหลัง ๆ กระแสการทำ Home Lab ฮิตขึ้นมาก ๆ ในประเทศไทยเรา มีคนถามเข้ามาเยอะมากว่า แล้วเราจะจัดการอย่างไรให้ระบบของเราปลอดภัยมากที่สุด วันนี้เราจะมารวบรวมวิธีคิดการวางสถาปัตยกรรมแบบ Defense-in-Depth สำหรับงาน Self-Hosting ง่าย ๆ กัน...

Functional Programming คืออะไร ? ทำไมมันถึงเป็นเรื่องที่น่าสนใจในยุคใหม่
11 เมษายน 2026 - 2 min readก่อนหน้านี้ไม่ค่อยได้สนใจการเอา Functional Programming มาใช้ในงานเท่าไหร่ แต่พอได้ลิ้มรสเท่านั้นแหละ มันเหมือนโลกใหม่มาก ๆ เข้ามาแก้ปัญหาหลาย ๆ อย่างที่เคยได้เจอมา วันนี้เราจะมาเล่ากันว่า มันคืออะไร และ มันน่าจะเหมาะกับงานไหนกัน...