ทำไม MacBook Pro M1 Max กับงาน Machine Learning ถึงน่าสนใจ ?
By Arnon Puitrakul - 14 ธันวาคม 2021
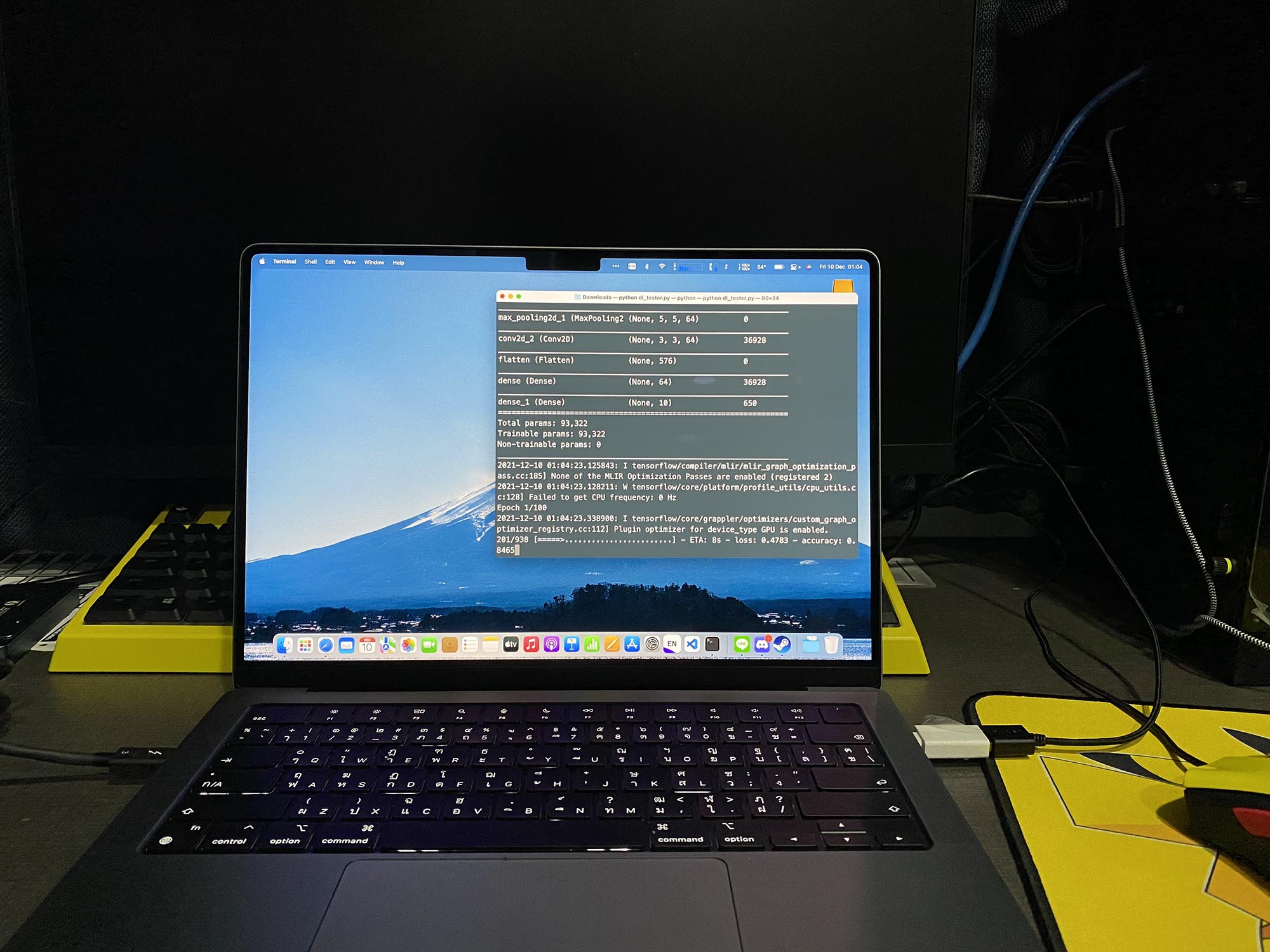
ตอนที่ทำรีวิว Macbook Pro 14-inches M1 Max ไปก่อนหน้านี้ มันมีส่วนที่เราจะทำ Benchmark ที่เป็นงานพวก Machine Learning ในการ Train Model ต่าง ๆ ให้ดูตอนที่นั่งเขียน Benchmark ก็ทำให้นึกได้ว่า เออจริง ๆ แล้ว Macbook Pro M1 Max มันเป็นอะไรที่เจ๋งมาก ๆ เลยนะ สำหรับงานพวก Machine Learning ทำไมถึงเป็นแบบนั้นละ ลองไปดูกัน
อ่อ บอกก่อนนะว่า เราไม่ได้บอกให้เลิกซื้อ Cluster แล้วไปกด M1 Max มานะ เพราะยังไง ๆ เรื่องของ Processing Power ยังไง ๆ มันก็ยังสู้พวก Tesla A100 ไม่ก็พวก Card สำหรับทำ Deep Learning ไม่ได้นะ อย่าลืมนะว่าพวกนั้น มันสเกลคนละเบอร์ !!!
Unified Memory ขนาดใหญ่
ประเด็นแรกที่เป็นประเด็นที่ทำให้เราเขียนบทความนี้ขึ้นมาเลย เหตุคือ Unified Memory Archtecture (UMA) สำหรับคนที่ไม่รู้ มันเป็นวิธีที่ เรารวม Memory ในส่วนของ CPU และ GPU เข้าด้วยกัน เหมือนกับเรามี Memory กองใหญ่ ๆ อยู่กองนึง แล้วใครอยากจะเรียกใช้อะไร ก็ไปเรียกได้เลย ทำให้มันลดเวลาในการ Copy และ เอาไปเขียนที่อีกด้านได้ เช่น จากเดิม เราจะทำงานเราจะต้องดึงข้อมูลจาก RAM เข้าไปใน RAM ของ GPU ถึงจะทำงานได้ ทำให้มันมี Gap เวลาตรงนี้อยู่ แต่ถ้าเราใช้ UMA เวลาตรงนี้มันหายไปเลย เพราะมันอยู่ใน Pool เดียวกันอยู่แล้ว เราก็บอกให้อีกฝั่งมาเอาได้เลย ตัดเวลาไปได้มหาศาลมาก ๆ โดยเฉพาะถ้าเราทำงานกับ Dataset ขนาดใหญ่
จากเดิมตอน M1 เฉย ๆ เราไม่ได้สนใจเรื่องนี้มาก เพราะ Maximum Memory มันได้อยู่ที่ 16 GB ซึ่งถ้าสมมุติว่า เราเอา 16 GB นี้เป็น Graphic Memory 100% เลย (เป็นไปไม่ได้แน่นอน) ตีกว่าทั้ง System ของ Macbook Air เราโดนอยู่ที่ 50k บาท แต่ถ้าเราไปหา GPU ที่มี Memory ใกล้เคียงกัน อะ ตีว่าเอา 3080Ti ที่มี Memory อยู่บน GPU 12 GB ไปเลย ไม่เอาราคาตลาดตอนนี้เลยนะ เอาราคาเปิดตัวเลย มันก็จะอยู่ที่ประมาณ 1,199 USD หรือตก 40k กว่า ๆ บาท แล้วนี่ยังไม่รวม CPU และ RAM และ Storage และอื่น ๆ อีกมากมายเลยนะ ทำให้เราเห็นได้เลย ว่า แค่ 16 GB บน UMA ของ Macbook Air มันถูกกว่ามาก แต่มันก็ยังไม่ได้โอ้โหขนาดนั้น
จน M1 Max ออกมาแล้วบอกว่า ใส่ Unified Memory ได้ถึง 64 GB เลย ถ้าหา GPU สำหรับ Train Model ที่ขนาดสัก 40 GB ก็เอาแรง ๆ ไปเลยอย่าง Nvidia Quadro A6000 มี RAM แบบ GDDR6 ขนาด 48 GB น่าจะมีใบเฉียด ๆ แสนแหละ ยังไม่รวมอย่างอื่นเข้าไปอีกนะ แต่ ๆๆๆๆๆๆ เราต้องยอมรับก่อนนะว่า มันไม่ได้แพงกว่าแล้วโง่กว่านะ เพราะอย่าง Quadro A6000 ยังไง ๆ CUDA Core มันก็ทำงานได้เร็วกว่า GPU 32-Core บน M1 Max นะ แต่เราพูดในเชิงว่า ถ้าเรามองว่า Solution ที่เราไม่ได้ต้องการ Processing Power แต่เราต้องการ Memory ขนาดใหญ่ ๆ เรามองว่า UMA บน Macbook Pro มันเป็นอะไรที่น่าสนใจมาก ๆ มันพอที่จะทำให้เราสามารถ Prelim Model ของเราขำ ๆ ได้ก่อนที่เราจะยัดทั้งหมดลงไปได้ (ถ้าเราไม่รวยจริง ถึงมี A6000 พวกแกก็ต้องต่อคิวใช้กัน ชั้นรู้ !!!)
เร็วมากพอ....
อย่างที่บอกว่า ถึง Memory จะใหญ่ แต่ความเร็วมันก็สู้พวก GPU ตัวใหญ่ ๆ ไม่ได้หรอก แหม่เครื่องแค่นี้จะไปฟัดกับพวก Tesla A100 หรือ Quadro RTX A6000 ฝันไปก่อน แต่พวกนั้น การที่เราจะเข้าถึงและใช้งานได้เป็นปกติ เราบอกเลยว่า ไม่บริษัทที่เราทำงานริชชี่ หรือทำงานทางด้าน AI โดยเฉพาะ หรือไม่ก็อยู่ใน Lab ของมหาลัยที่มีของเล่นพวกนี้ให้ใช้ ถ้าเป็นในเคสปกติที่เราเล่นกันทั่ว ๆ ไป เราก็จะอยู่กับพวก Google Colab ที่ในนั้น ถ้าเราเคยใช้ เราก็จะได้เป็นพวก Tesla K80 ซึ่งมันก็ถือว่าเก่าแล้วละ มันออกตั้งแต่ปี 2014
ซึ่งแน่นอนว่า Macbook Pro M1 Max กิน K80 ขาดเลย ทำให้จริง ๆ แล้ว ถ้าเราทำงานบน Model ที่ไม่ได้มีขนาดใหญ่มาก เพียงพอกับที่ K80 จะรันได้ เรามองว่า การใช้ M1 Max มารัน ก็ล่นเวลาให้เราได้เยอะมาก ๆ ทั้งในเรื่องของการ Uplaod Data ขึ้น Cloud ที่ถ้า Data ขนาดใหญ่ มันก็เสียเวลาในการ Upload อีกสารพัดเลย ทำให้ถ้าเราทำงานกับ Model ขนาดที่ไม่ใหญ่มากบ่อย ๆ การใช้ M1 Max มันช่วยได้เยอะเลย
หรือกระทั่ง เรามีเอาไปทดลองฟาดกับ RTX 3090 ก็ถือว่าห่างกันประมาณเกินครึ่งหน่อย ๆ เรามองว่า เออ เอาจริง ๆ ด้วย Form Factor และการที่เราเอาไปทำงานที่ไหนก็ได้ แลกกัน มันก็โอเคสำหรับการทำงานของเรานะ ทำให้ M1 Max มันเร็วมากพอที่จะทำงาน Machine Learning ในขนาดเล็กจนไปถึงกลาง ๆ ได้สบาย ๆ เลย (ไม่ถึงข้อของพวก Tesla A100 ไม่ก็พวก Quadro A6000 ขนาดนั้น)
Power Efficiency
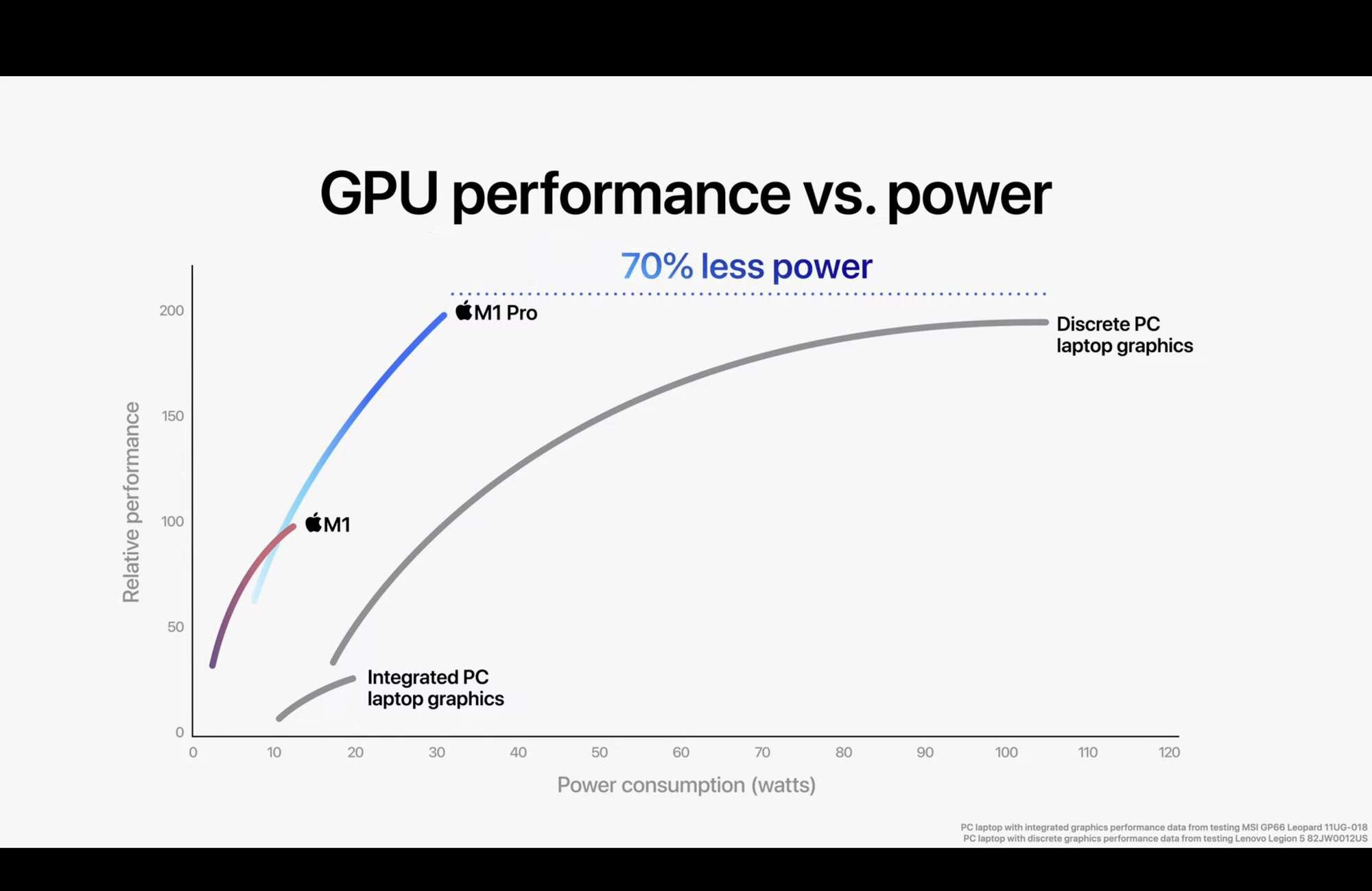
เรื่องที่ Apple ให้เป็น Highlight ของพวก M1 ทั้งหลายคือเรื่อง Performance ต่อการใช้พลังงาน หรือ Power Efficiency นั่นเอง อย่างใน M1 Max บน รุ่น 14 นิ้วที่เราใช้อยู่ ตอนที่ Train Model แล้วรัน GPU Utilisation ที่ 100% เลย ระบบบอกว่าเราใช้ Power อยู่แค่ 24W เท่านั้น แต่ถ้าเราหันไปเล่นกับพวก GPU ขนาดใหญ่ ๆ ก็คือ แค่ GPU เองก็น่าจะมีเกิน 100W แล้วละ ไม่นับพวก GPU ตัวแรง ๆ นะ มีหนักกว่านี้มาก
อย่างงานที่เราทำ เรามีการทำ Model ที่จะต้อง Train เป็น Routine มาก ๆ อย่างการใช้ Data จาก Sensor ในบ้านในการ Train Model 2 วันครั้ง ตอนที่เราใช้ 1070Ti ในการ Train มันกินไฟอยู่เยอะพอตัวเลย หลัก 100 Watts เลยก็ว่าได้ แต่งานนี้คือ มันทำเป็น Background ดังนั้น เรารอได้ ทำให้เราไม่ได้จำเป็นที่จะต้องใช้เครื่องที่กินไฟเยอะ ๆ แล้วทำงานได้เร็ว เรายอมเอาช้าหน่อย แต่ระยะยาวกินไฟน้อยกว่าเราก็โอเคเลย
M1, M1 Pro และ M1 Max เหมาะกับงานส่วนไหน ?
อย่างที่เราบอกคือ GPU บน M1 ทั้งหลาย มันไม่อาจจะไปงัดข้อสู้กับพวก Dedicated GPU ตัวใหญ่ ๆ ได้เลย ทำให้งานที่ M1 ทั้งหลายมันจะเหมาะ มันจะไปได้กับเรื่องของ Model ขนาดเล็ก ๆ จนถึง Model ขนาดกลาง ๆ ที่เราอาจจะรอมันทำงานได้ เวลาไม่ได้เป็นผลอะไรกับเรามาก คือมันรันได้แหละ แต่มันนานเท่านั้นเอง แต่ส่วนของงานที่ทำให้เราไม่คืนเครื่องแล้วกลับไปใช้ Macbook Air คือ มันทำให้เราสามารถทดลอง Model ลอง Train บน Architecture ที่ย่อส่วนลงมาหน่อย หรืออาจจะลดจำนวน Dataset ลงไป เพื่อให้เราสามารถทดลองก่อนที่จะเอาไป Upscale รันจริงบน GPU Server ที่มีพลังเยอะกว่านี้ได้นั่นเอง
M1 vs M1 Max
การทดลองนี้ เราทำเพราะตอนนั้นเราอยากจะคืน Macbook Pro 14-inches M1 Max แล้วใช้ Macbook Air M1 เหมือนเดิม เลยเออ ไหน ๆ ก็ไหน ๆ แล้วลองงานพวก Deep Learning ที่เราทำอยู่ทุก ๆ วันหน่อยว่ามันเร็วขึ้นขนาดไหน ถ้ามันเร็วขึ้นมาก มันก็จะอยู่ต่อ เลยลองเขียน Script ง่าย ๆ ขึ้นมา ใช้ NMIST Dataset ใส่กับ CNN ง่าย ๆ ลงไป ผ่าน Tensorflow ที่รองรับ Metal แล้ว
ในที่นี้ เราใช้ Configuration เหมือนกันบนทั้ง 2 เครื่อง จริง ๆ คือ Code ไฟล์เดียวกันเลย หลัก ๆ ก็คือ 5 Epoch และ Batch Size 32 บน M1 ปกติมันกินใช้เวลาไป 92 วินาที ส่วนบน M1 Max มันใช้เวลาอยู่ 53 วินาที ทำให้มันห่างกันถึง 42.39% เลย ถึง จำนวน GPU Core มันจะต่างกัน 4 เท่า แต่ Performance มันไม่ได้ต่างกันขนาดนั้น เราคิดว่า ถ้าเจอ Model ที่ใหญ่กว่านี้ Margin มันน่าจะใหญ่กว่านี้ เพราะจากประสบกาณ์ที่ใช้ M1 มา ถ้าเราใช้งานมันแล้วมันยังเอาอยู่มันจะเร็วมาก ๆ แต่ถ้ามันเริ่มไม่ไหวแล้ว Performance มันจะหล่นฮวบ ๆ เลย การเปลี่ยนมาใช้ M1 Max อย่างแรกมันขยายสเกลในการทำงานให้เราได้ และ อีกอย่างมันทำให้เราทำงานได้เร็วขึ้น เราเลยยอมใช้เครื่องที่หนักขึ้น แต่ทำงานเสร็จเร็วขึ้นดีกว่า
ส่วน Neural Engine ที่ Apple เคลมว่าเร็วจี๊เลย เอาจริง ๆ คือ ถ้าเราใช้งาน Tensorflow ที่รันผ่าน Metal คือใช้งาน GPU เต็ม ๆ เลยมันจะไม่ได้เข้าไปยุ่งกับ Nerual Engine เลยนะ ถ้าเราต้องการจะใช้ Neural Engine เท่าที่อ่านมา มันจะต้องเอา Model ของเราไป Compile แล้วทำผ่าน coremltools เพื่อแปลง Model ก่อน แต่เรายังไม่แน่ใจว่า ถ้าเราแปลง แล้ว Train แล้วแปลงกลับมาได้มั้ยอะไรแบบนั้น เดาว่ามันอารมณ์คล้าย ๆ กับตอนที่เล่น TensorRT มั้งนะ ฮ่า ๆ เราเลยไม่ไปยุ่งกับพวก Neural Engine ไว้รู้รายละเอียดมากขึ้นแล้วจะมาลองให้ดู
สรุป
Macbook Pro M1 Max เราคิดว่าถ้าใครที่กำลังมองหาเครื่องที่เอามาทำงานพวก Deep Learning แบบสเกลขนาดเล็กถึงปานกลาง แล้วต้องการ Train บนเครื่องของเราเลย พร้อมกับ ความ Mobility ในการเอาเครื่องไปทำงานที่ไหนก็ได้ด้วย เราว่ามันเป็นตัวเลือกที่น่าสนใจมาก ๆ ทั้งในเรื่องของ Unified Memory ที่เร็วและล่นเวลาในการทำงานไปได้พอตัว และพลังที่อย่างน้อยก็เร็วกว่าการที่เราเอาไปรันบน Colab ตัวฟรีแน่ ๆ แต่ถ้าใครที่ทำงานที่ขนาดใหญ่กว่านั้นอีก เรามองว่า เราก็อาจจะเอา M1 Max นี่แหละมาทดลองในสเกลขนาดเล็กก่อน แล้วเราค่อยอัพสเกลไปรันบนพวกเครื่องขนาดใหญ่ ๆ ได้เร็วกว่าเดิมแน่นอน
Related Posts

วิศวกร Safeguard ป้องกัน LLM จากการโดน Jailbreak อย่างไร
13 กรกฎาคม 2026 - 1 min readLLM เก่งขึ้นทุกวัน จนบางทีจะดูเป็นอันตรายมาก ๆ วิศวกร เขามีวิธีการอย่างไรเพื่อป้องกันไม่ให้ Model ตอบคำตอบที่ไม่ควรตอบ วันนี้เราจะมาเล่าให้อ่านกัน...

ทำยังไงถึงจะประหยัดค่า AI ในการทำงานได้
04 กรกฎาคม 2026 - 1 min readเมื่อหลายปีก่อน เราพูดบ่อยมาก ๆ ว่าเราน่าจะประหยัด Token ในการใช้ AI แต่คนก็บอกว่า นี่ เราจะต้องยัด Token เข้าไปเยอะ ๆ ใช้ Reasoning เยอะ ๆ สิมันจะได้ฉลาด แต่วันนี้ราคา Token นับวันยิ่งแพงขึ้นเรื่อย ๆ ทำยังไงกันละ เราถึงจะได้ความฉลาดเท่าเดิม แต่ประหยัดเงินในกระเป๋าของเราได้...

รู้จักกับ NVFP4 มาตรฐานการ Quantised จาก Nvidia
17 มิถุนายน 2026 - 1 min readก่อนหน้านี้ เรารีวิว DGX Spark สำหรับใช้งานในบ้านเราไป เลยทำให้เราได้ไปนั่งหา Model เพื่อมารัน จนอ่านไปเจอกับ NVFP4 ที่เป็น Quantisation ของ Nvidia เอง แล้วมันเป็นอะไรที่เจ๋งมาก ๆ วันนี้เราจะมาเล่าให้อ่านกันว่า ทำไมมันเจ๋ง และ ใครควรจะใช้...

เจาะลึก Vera CPU ไม้ตายใหม่จาก Nvidia งัดมาสู้กับ Agentic AI
14 มิถุนายน 2026 - 1 min readไม่ไหวแล้ววว คอมพิวเตอร์ตอนนี้สู้กับ AI ที่กินทั้ง Memory และ Compute มหาศาลไม่ไหวแล้ว !! เจาะลึก Vera Rubin ที่ Nvidia ออกมาเพื่อแก้ปัญหาที่เจอโดยเฉพาะ เขาทำยังไงอ่านได้ในบทความนี้เลย...