An Introduction (?) to Deep Learning
By Arnon Puitrakul - 01 ตุลาคม 2020

หลาย ๆ คนที่เข้ามาอ่านน่าจะเคยได้ยินคำว่า Deep Learning มาผ่าน ๆ แล้วละ แต่อาจจะไม่เคยอ่านมาก่อน วันนี้เราจะมาเล่าเรื่องของ Deep Learning พื้นฐาน (มั่ง) ว่ามันทำงานยังไง ทำไมมันถึงเอามาเป็น Model สำหรับใช้ใน Application ต่าง ๆ ที่เราเห็นในปัจจุบันได้ สำหรับคนที่สนใจ หรืออยากจะอ่านเพื่อเป็นพื้นฐานก่อนที่จะไปอ่านอันที่มันดุดันมากขึ้น
Artificial Neural Network คือพื้นฐานของ Deep Learning
ก่อนที่เราจะไปเข้าใจว่า Deep Learning หน้าตาเป็นยังไง มันคืออะไรกันแน่ เราต้องมาเข้าใจพื้นฐานกันก่อนว่า ใน Deep Learning Model จริง ๆ แล้ว มันเป็นก็คือ Artificial Neural Network (ANN) ที่ต่อกันลึก ๆ หลาย ๆ Layer เยอะ ๆ นั่นเอง Concept ของการทำ ANN นั่นก็มาจากธรรมชาติ เพราะจริง ๆ แล้วในสมองของสิ่งมีชีวิตที่มีสมองนั้นก็มีเซลล์ประสาทที่มีความซับซ้อนสูงมาก มันส่งถ่ายสัญญาณประสาท แล้วแปลผลออกมา เป็นความรู้สึกบ้าง เป็นความคิด ของเราทั้งนั้น
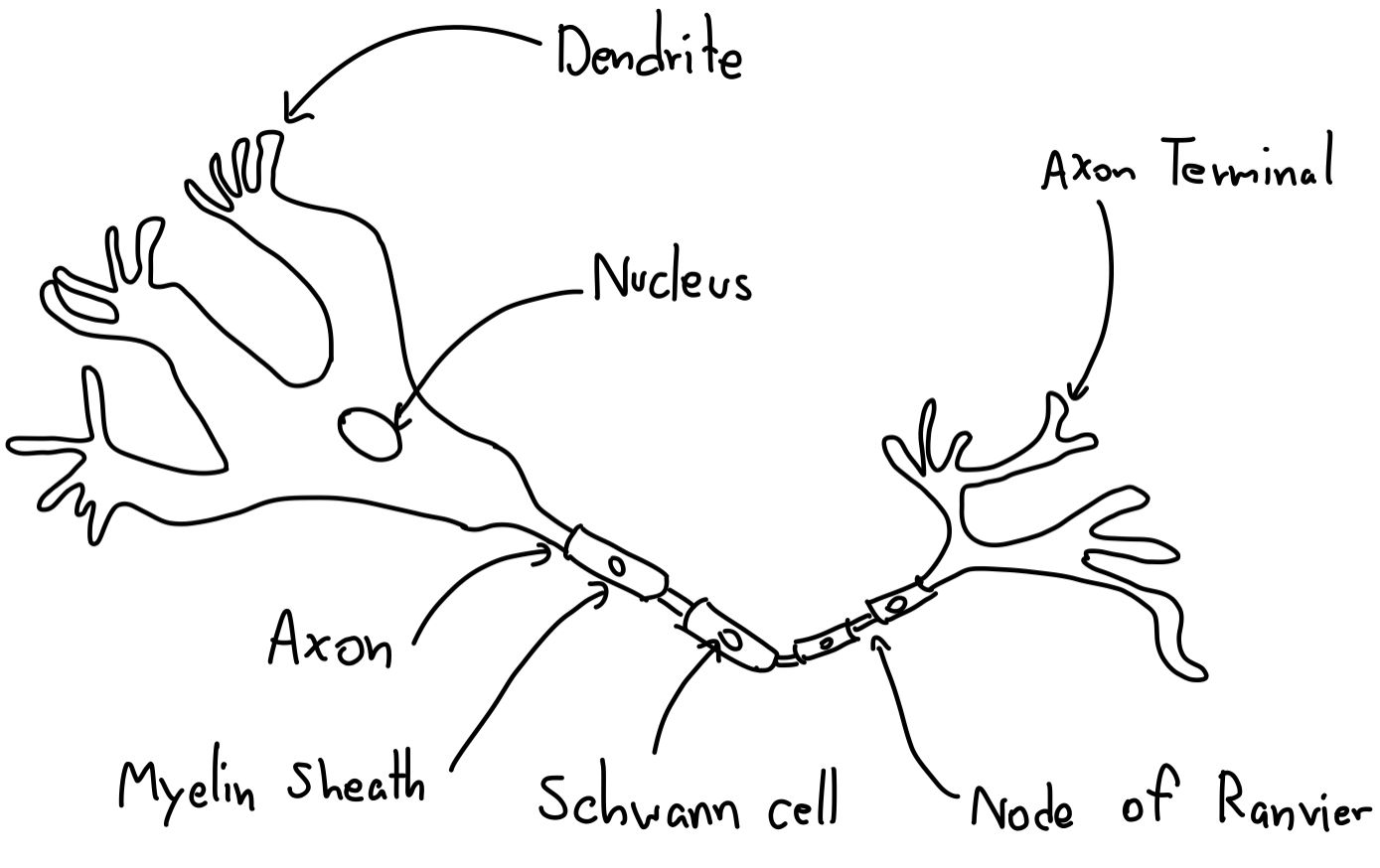
โดยในเซลล์ประสาทของเรา ถ้าเราเรียนกันมาตอนมัธยม อาจจะคุ้นเคย เคยเห็นภาพนี้มาบ้างนี่คือ รูปของเซลล์ประสาท ที่เริ่มจาก Dendrite เหมือนเป็นหัว ที่รับปลายของอีกเซลล์เข้ามา และ วิ่ง ๆ ไปในเซลล์และไปออกที่ปลายอีกด้านคือ Axon Terminal แต่วันนี้เราไม่ได้จะมาพูดถึงเรื่องของเซลล์ประสาท เอาแค่นี้ละกัน
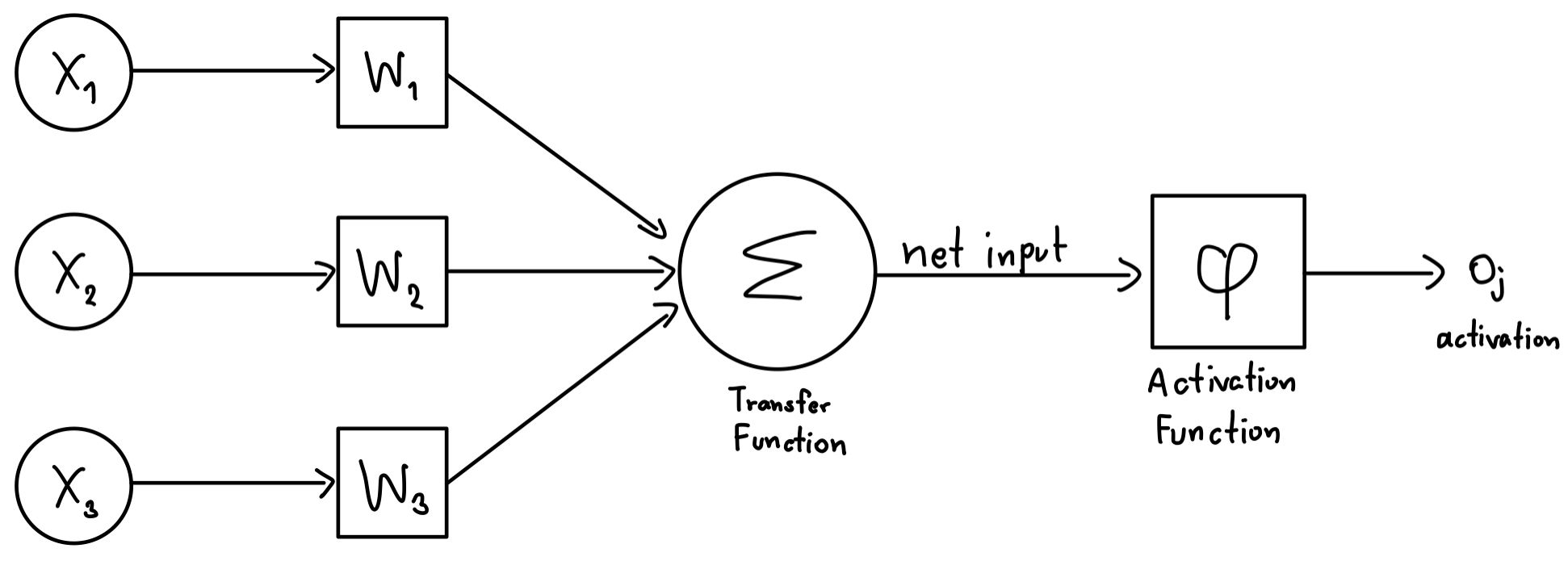
ในโลกของคอมพิวเตอร์ก็มีการเลียนแบบลักษณะการทำงานของเซลล์ประสาทของเราเข้ามาใช้งานด้วยเช่นกัน เราเรียกมันว่า Artificial Neuron หรือถ้าแปลตรง ๆ คือ ประสาทเทียม นั่นเอง ซึ่งใน Artificial Neuron ก็จะทำงานเหมือนเซลล์ประสาทเราเลย
เริ่มจากการรับค่าเข้ามา โดยที่ในแต่ละค่าที่เข้ามา น้องก็จะมีอีกค่าคือ Weight หรือน้ำหนัก หรือถ้าพูดง่าย ๆ คือ ความสำคัญของค่านั้น ๆ ที่เรารับเข้ามา จุดนี้ ก็อาจจะเทียบกับ Dendrite ของเราได้เลย อาจจะ งงไปหน่อยแต่อ่านต่อไปก่อนจะกระจ่างขึ้น
จากนั้น มันก็จะเอาค่ามารวมกันด้วยวิธี ๆ นึง โดยใช้สิ่งที่เรียกว่า Transfer Function และ เอาไปเข้ากับอีกสมการนึงเราเรียกว่า Activation Function และก็พ่นค่าออกไปให้ Neuron ต่อต่อไป เหมือนกับ Axon Terminal ของเซลล์สมองเรานั่นเอง
ทีนี้พอเราเอา Artificial Neuron มาต่อ ๆ กัน เหมือนกับที่สิ่งมีชีวิตเป็น มันก็จะเกิดเป็นเครือข่ายขึ้นมา เราเลยเรียกมันว่า Artifical Nerual Network หรือย่อ ๆ ว่า ANN
เมื่อ ANN ต่อกันไปเรื่อย ๆ
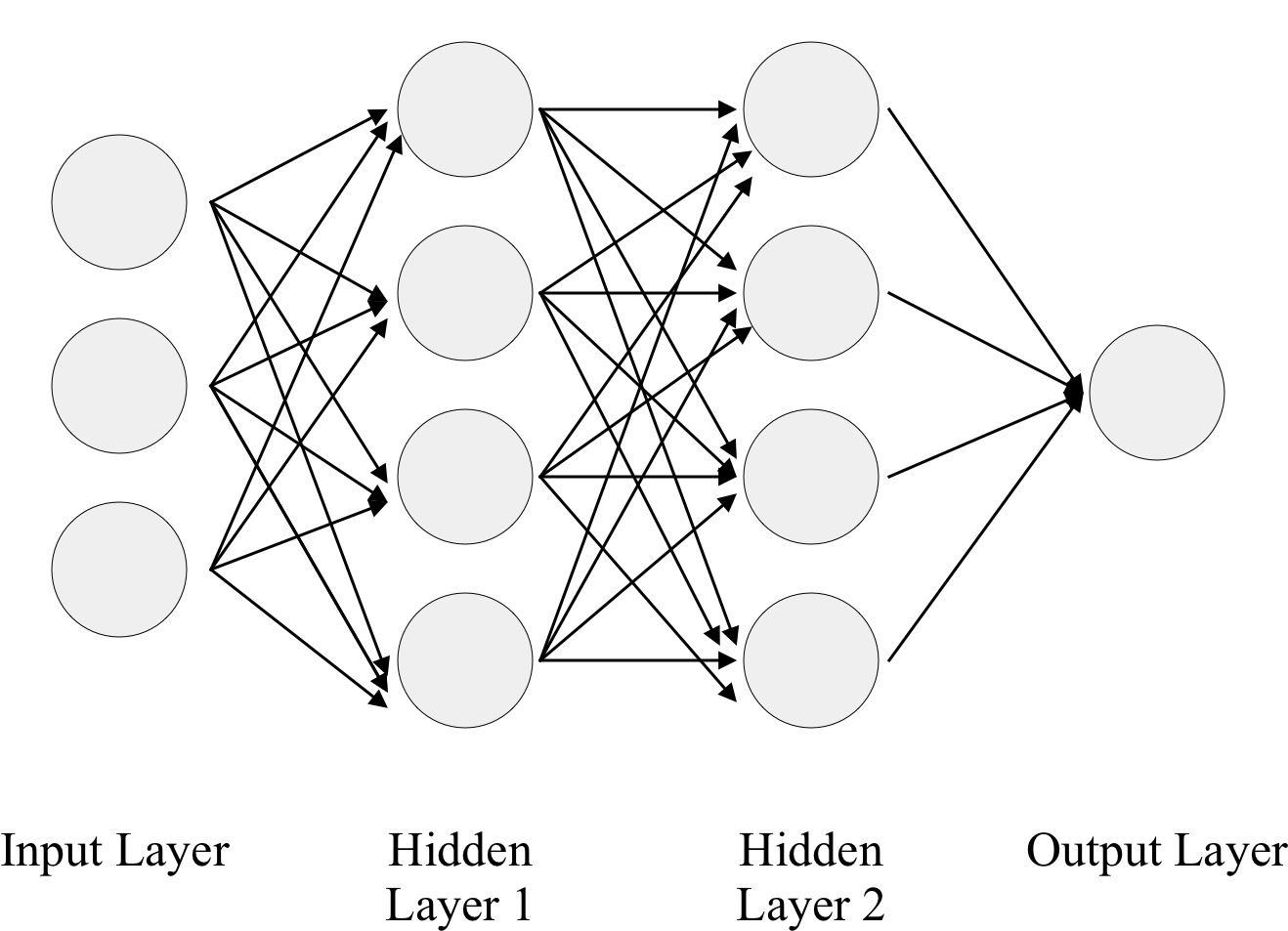
โดยปกติแล้ว ANN เราจะเอามาต่อกันเป็นชั้น ๆ เหมือนภาพที่เราอาจจะเคยเห็นกันบ่อย ๆ หลัก ๆ แล้ว เราจะแบ่ง Network นี้ออกมาเป็น 3 ชั้นด้วยกันคือ Input Layer, Hidden Layer และ Output Layer
โดยที่ Input Layer และ Output Layer ทำหน้าที่ตามชื่อของมันเลยคือ เป็นส่วนที่ใช้รับค่าเข้ามา และ เป็นส่วนที่ใช้พ่นค่าออกมาให้เราใช้งานตามลำดับ ส่วนตัว Hidden Layer เอาง่าย ๆ มันคือ Layer อะไรก็ได้ที่อยู่ระหว่างกลาง Input และ Hidden Layer โดยที่จะมีกี่ชั้นก็มีไป จะมีกี่ Neuron ต่อชั้นก็แล้วแต่เราออกแบบได้หมดเลย
เมื่อเราเอาส่วนประกอบของ ANN มาต่อเข้าไปเรื่อย ๆ เราเอา Input เข้ามาใส่ เอา Output ไว้ปลาย ๆ และตรง Hidden Layer เราใส่ไปหลายชั้นมาก ๆ ถ้าเราดูดี ๆ มันก็คือ Network ของเรามีความลึกมากขึ้นเรื่อย ๆ นั่นแหละทำให้เราชอบเรียกมันว่า Deep Learning ดังนั้นจริง ๆ แล้ว Deep Learning ก็คือ ANN ที่มีขนาดใหญ่นั่นเอง
How to Train Your Model
การเรียนรู้ หรือการ Train Model จริง ๆ แล้วมันเหมือนกับคนเรามาก ๆ เวลาเราเรียนรู้อะไรบางอย่าง โดยเฉพาะตอนเด็ก ๆ ที่เมื่อก่อนเราอาจจะเป็นเจ้าหนูจำไม แม่ ๆ นั่นคืออะไร ? อ่อ นั่นคือรถไงลูก ~ เราก็จะเข้าใจว่า ของหน้าตาแบบนี้มันคือรถนะ พอเราไปเจอกับของที่หน้าตาเหมือนรถ เราก็จะเข้าใจว่า นี่คือรถนะ หรือถ้าเราเห็นของที่คล้าย ๆ รถแล้วเรารู้ว่ามันไม่ใช่รถ เราก็จะจำว่า อ่อ นี่ไม่ใช่รถนะ นี่คืออย่างอื่นอะไรก็ว่าไป ทุกคนเองก็น่าจะผ่านเรื่องอะไรแบบนี้มาจน ทำให้ทุกวันนี้เราเดินผ่าน อ่อ นี่รถ อ่อนี่หมา อ่อนี่กินได้
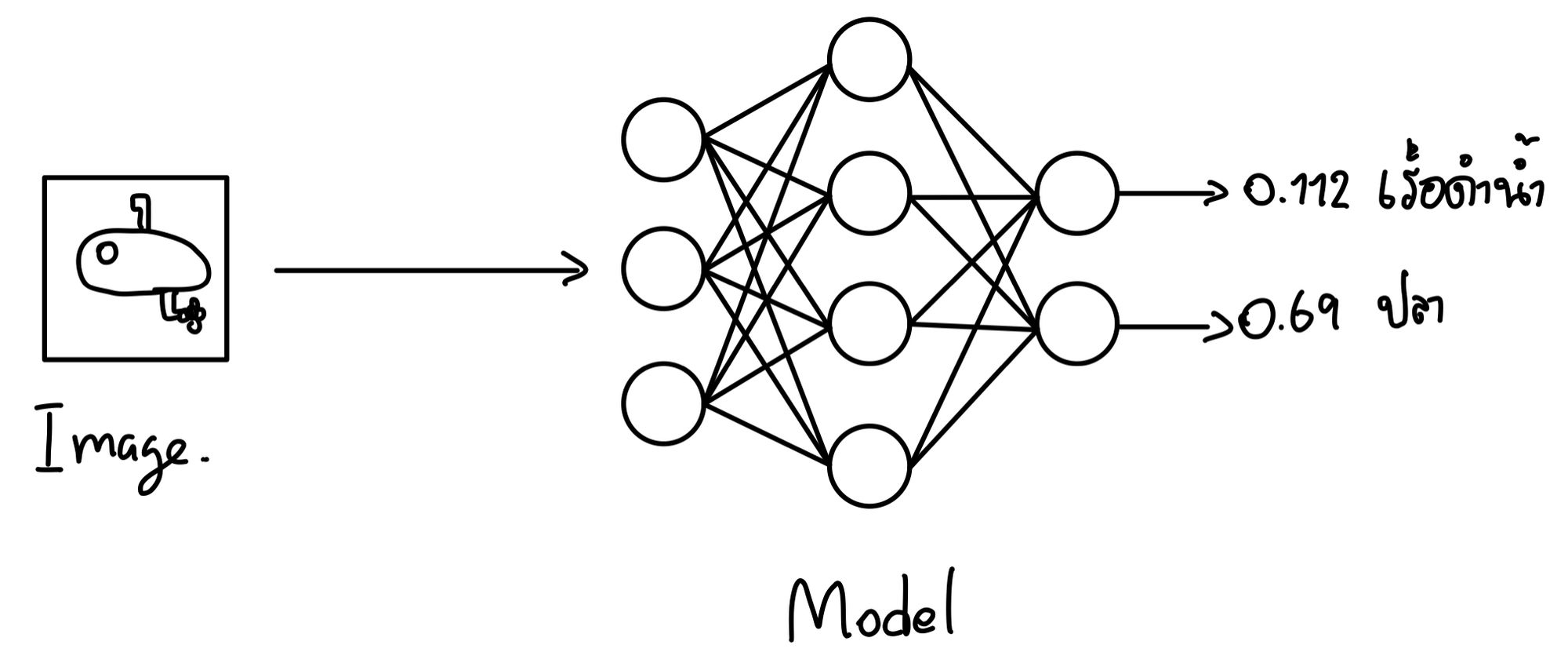
เครื่องก็ไม่ต่างกัน เวลาเรา Train Model เราก็จะป้อนข้อมูลเข้าไปพร้อมกับเฉลย เช่นเราอาจจะอยากให้มันเรียนรู้ว่านี่คือรถ หรือ เรือดำน้ำ จากภาพ เราก็ต้องเอารูปของ ปลา และ เรือดำน้ำ ใส่เข้าไปให้มัน และ ทุก ๆ รูปเราต้องบอกมันด้วยว่า รูปไหนคืออะไร เครื่องจะได้จำถูกว่ามันคืออะไรกันแน่
จริง ๆ หลักการนี้เราเรียกเป็นศัพท์เก๋ ๆ ว่า Supervised Learning จนเมื่อเราเอาภาพใหม่ใส่เข้าไป เครื่องควรจะบอกได้ว่านี่คืออะไร โดยที่ไม่ต้องดูเฉลย นั่นคือ เป้าหมาย ของการ Train Model นั่นเอง
ไหน ๆ ก็พูดถึง Supervised Learning แล้ว มันยังมีอีก 2 คำที่อยู่ด้วยกันคือตรงข้ามกับ Supervised Learning คือ Unsupervised Learning หมายความว่า เราจะไม่ช่วยเครื่องเลย ให้เครื่องมันแยกและเรียนรู้ด้วยตัวเอง และอีกคำคือ Reinforcement Learning ที่เป็นกึ่ง ๆ ของ Supervised และ Unsupervised คือ เราช่วยมันนิดหน่อย แต่มันก็ยังต้องหาเองบ้าง
ตัวอย่างของ Unsupervised Learning ที่น่าสนใจคือ การทำ Customer Segmentation หรือการแบ่งกลุ่มลูกค้า เรามีข้อมูลลูกค้าว่าเป็นใครบ้าง เราแค่บอกเครื่องว่า เราอยากให้เครื่องแยกกลุ่มลูกค้าออกมาให้หน่อย เอาด้วยเงื่อนไขหรืออะไรก็ได้ที่คิดว่าเหมาะสมเอาออกมา แค่นั้นเลย ไม่จำเป็นต้องใช้เฉลย หรือทำอะไรกับมันอีก โดยที่ Model ที่ได้ออกมา อาจจะให้ Insight บางอย่างกับเราก็ได้
ตัวอย่างของ Reinforcement Learning ที่เป็นที่รู้จักกันคือการสอนเครื่องเล่นเกม ในการสอนมันครั้งนี้ เราบอกข้อมูลมันเล็กน้อยเช่นเครื่องมันจะควบคุมเกมได้ยังไง และ เป้าหมายคืออะไร แล้วก็ให้เครื่องคิดเองว่า มันควรจะเล่นยังไงถึงจะได้ผลลัพธ์ที่ดีที่สุด เราไม่ได้บอกว่า ดีที่สุดคือเท่าไหร่
How Deep Learning Model learn through data ?
คำถามต่อไปคือ แล้วจากรูปกลม ๆ ที่เราเห็นกันเวลาเราไปหาคำว่า Deep Learning ใน Google จริง ๆ แล้วมันเกิดอะไรขึ้นกันแน่ ทำไม จากกลม ๆ นั่นผ่านการ Train แล้วมันถึงเอาไปทำนาย หรือทำอะไรได้เยอะแยะไปหมด หรือว่ามันเป็นเวทย์มนต์ จะบอกว่า ไม่เลย จริง ๆ แล้วมันคือ คณิตศาสตร์ ล้วน ๆ เลย แต่เราจะไม่เน้นไปที่ตรงนั้นเท่าไหร่ เราจะเน้นไปที่ Concept เป็นหลัก
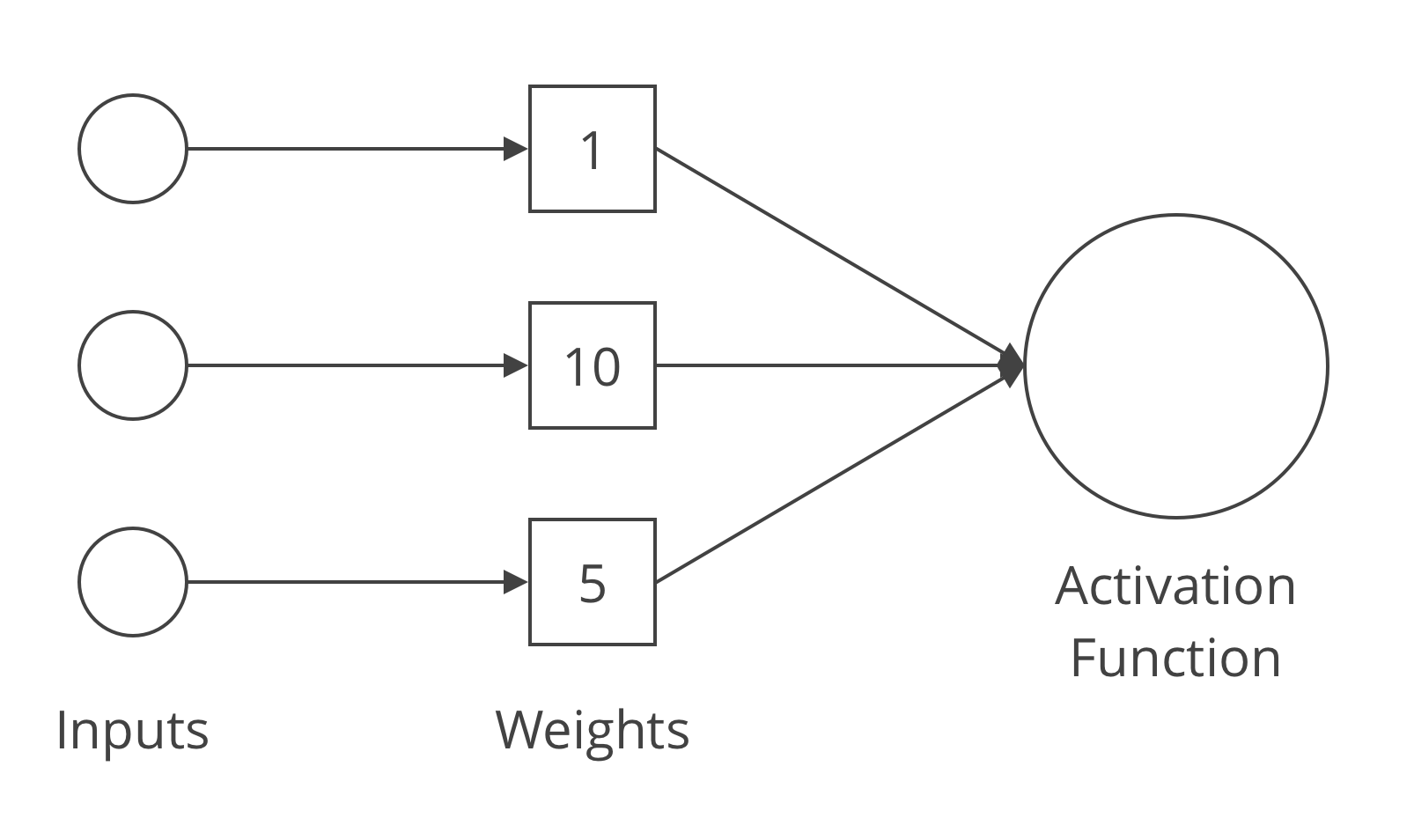
สั้น ๆ ในการเรียนของมันคือ เวลาเราทำ Training มันคือ การเปลี่ยน Weight ของ Artifical Neuron ไปเรื่อย ๆ ตามข้อมูลที่เราใส่เข้าไป ดูเหมือนจะเป็นงานเบา ๆ ไม่น่ามีอะไร ใช่ฮ่ะ ถ้าเรามี Neuron แค่อันเดียว มันก็น่าจะไม่ได้ยากมาก
แต่ถ้าเราบอกว่าเรามี ANN ที่ประกอบด้วย Artifical Neuron หลายสิบ หลายพันตัว แต่ละตัวมี Input มี Weight ไม่ต่ำกว่า 5 อัน ก็ลองคูณกันไปได้ว่ามันต้องหา Combination ของ Weight ในทุก ๆ Neuron ที่ให้ผลลัพธ์ที่ถูกต้องที่สุดได้ยากขนาดไหน มันมีหลาย Combination มาก ๆ
ถามว่า แล้วเวลา Weight มีการเปลี่ยนแปลง แล้วเครื่องจะรู้ได้ยังไงว่า การเปลี่ยนแปลงที่มันทำไป มันทำให้ Model มันดีขึ้น หรือแย่ลง คำตอบคือ Loss Function นั่นเอง
Loss Function เป็น Function ทางคณิตศาสตร์ตัวนึงที่ใช้วัดค่าความผิดพลาดของผลลัพธ์จาก Model ของเรา ตัวอย่างเช่น Mean Squared Error (MSE), Mean Absolute Error (MAE), Mean Absolute Percentage Error (MAPE) และ Root Mean Squared Error (RMSE) ที่เข้ามาวัดค่าความผิดพลาดของ Model เมื่อเทียบกับผลลัพธ์จริง ๆ เพื่อที่มันจะสามารถเอาไปปรับค่า Weight ต่อได้นั่นเอง
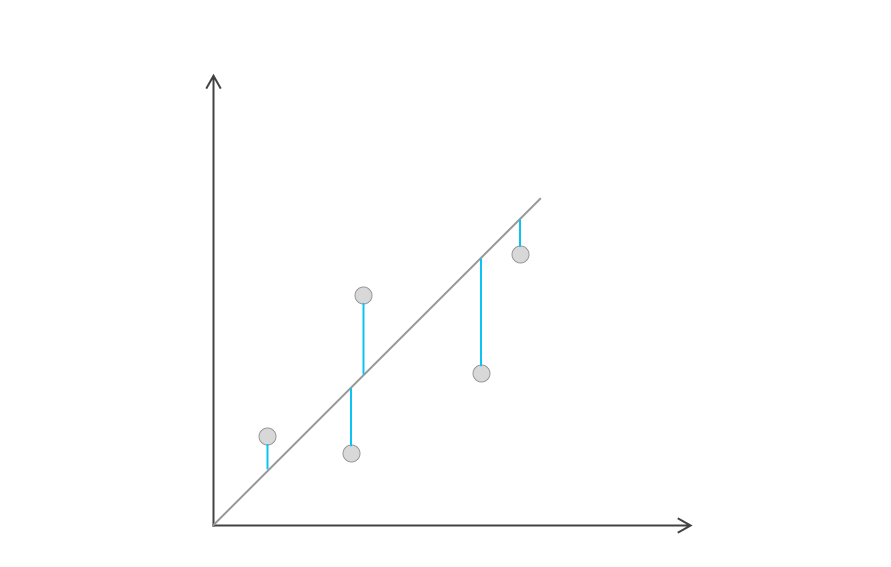
เพื่อให้เข้าใจง่ายยิ่งขึ้น เราขอยกตัวอย่างง่าย ๆ ปลายทางเราบอกว่า เราอยากรู้ว่า Model มันให้ค่าที่ผิดพลาดมากกว่าความเป็นจริงไปแค่ไหน ดังนั้นค่าที่เราต้องเอามาเทียบกัน ก็จะต้องเป็น ค่าจริงจากข้อมูล (Actual) และ ค่าที่ Model มันคิดออกมาให้เรา (Predicted)
ง่ายที่สุด เราอาจจะเอา Actual - Predicted ก็ได้ ก็ทำให้เราเห็นว่า Model มันทำงานผิดไปแค่ไหน โดยที่ค่าในอุดมคติเลย คือ 0 หรือก็คือ Actual = Predicted นั่นเอง หรือถ้าเป็นบวกคือ Model ทำนายออกมาได้น้อยกว่าความเป็นจริง ๆ และ ตรงข้ามคือ ได้ออกมาเป็น ลบ ก็คือ Model ทำนายออกมาได้เยอะกว่าความเป็นจริง แต่เมื่อเราใส่ Absolute ให้มัน เราก็จะได้เป็น Amplitude ของ Error ก็ได้เหมือนกัน
ดังนั้น Model ในอุดมคติ ควรจะ Fit กับข้อมูล แต่ก็ไม่ Fit เกินไป (ไม่งั้นจะเกิด Overfitting) หรือก็คือ มีค่าจาก Loss Function ที่ไม่ได้เยอะเกินไป หรือน้อยเกินไปนั่นเอง เวลาเราทำ Model มันสำคัญมาก ๆ ในการเลือก Component ต่าง ๆ ของ Model ไม่ว่าจะเป็นโครงสร้างของ Model ที่เราจะต่อกี่ Neuron และ กี่ Layer พร้อมกับ Loss Function อีกว่า เราจะนิยามความผิดพลาดว่าอย่างไร
ปัญหาว่า แก้แล้วดี หรือ แย่ลงถูกแก้ไขแล้ว แต่ปัญหาของ Combination ที่โคตรเยอะ ถ้าเราต้องสุ่มไปทุก Combination เลยมันก็จะใช้เวลานานมากเผลอ ๆ ไม่เสร็จเลย ถ้าเราคิดเป็นนักคอมพิวเตอร์หน่อย เราจะเห็นว่า ปัญหานี้มันคือ Searching Problem หรือก็คือการหาว่า Combination ของ Weight ตัวไหนที่ให้ Loss Function ที่ต่ำที่สุดนั่นเอง ถ้าเราบอกว่าการหาทุก Combination มันใช้เวลามากเกินไป
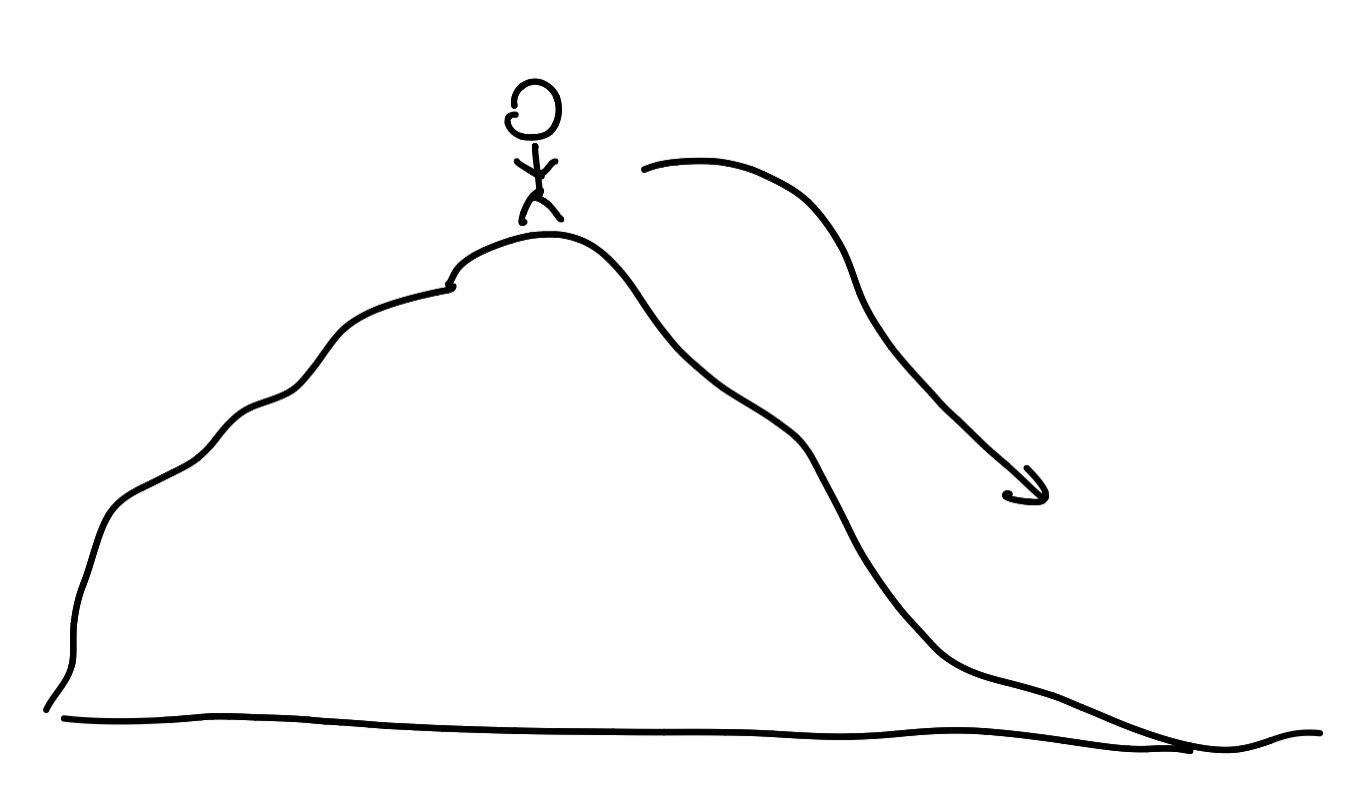
ทำไมเราไม่ลองหาให้เป็นระบบมากขึ้นละ ทำให้สิ่งที่เรียกว่า Gradient Decending มันเข้ามาช่วยเรา ให้เรานึกภาพว่า เรากำลังจะลงจากเขา ความสูงของเขามันก็เหมือนกับค่าจาก Loss Function แหละ เหมือนกับเราต้องการจะลงจากเข้าให้ได้ โดนที่ปลายทางเราต้องการลงไปได้ต่ำที่สุดเท่าที่จะเป็นไปได้
ย้อนกลับไปที่การลงจากเขา เราก็จะค่อย ๆ หาทางจากตรงที่เราอยู่แหละ แล้วพยายามหาทางลงไปเรื่อย ๆ จนเราถึงสุดต่ำสุดของเขานั่นเอง โดยที่เราไม่ต้องเดินผ่านทุกเส้นทาง ทุกความเป็นไปได้ให้เสียเวลานั่นเอง
ทำไม Deep Learning เขาว่า ใช้ GPU มันดีมาก ๆ
เวลาถ้าเราไปคุยกับหลาย ๆ คนที่ทำงานในเรื่องของ Deep Learning มักจะบอกว่า เราอยากได้ GPU มาก ทำไมถึงเป็นแบบนั้น ทำไมเราต้องไปซื้อ GPU มาเพื่อทำ Deep Learning ละ เราใช้ CPU ไม่ได้เหรอ

คำตอบมันอยู่ที่ลักษณะการออกแบบของ GPU ที่มันออกแบบมาให้มีจำนวน Core ที่เยอะมาก ๆ แต่ในแต่ละ Core มันมี Function การทำงานที่น้อยกว่าเมื่อเทียบกับ CPU ที่มี Core น้อย แต่ความสามารถล้นหลาม
ลองนึกภาพดูนะ ถ้าเรามี Neuron หลาย ๆ ตัวแล้วข้อมูลมัน Feed เข้ามาทำให้มันต้องคิดเลขเยอะมาก ไหนจะเอา Input มาคูณกับ Weight ไหนจะเอา Net Weight เข้า Activation Function อีก แต่ความที่มันแบ่งเป็นหลาย ๆ Neuron ต่อ ๆ ไปจำนวนมาก ทำให้ GPU ที่ออกแบบมาให้มีจำนวน Core ที่เยอะกว่า เลยได้เปรียบในการทำ Deep Learning ไปโดยปริยาย มันก็อาจจะแบ่งไปเลยว่า Core ที่ 1-10 รับ Neuron นี้ไป ไปเรื่อย ๆ เลย
กับในปัจจุบันเอง GPU บางรุ่นก็ออกแบบมาเพื่อให้เราทำงานแบบ Deep Learning โดยเฉพาะ อาจจะมีวงจรสำหรับการคำนวณที่เฉพาะกับการทำ Deep Learing ทำให้ความเร็วในการ Train Model หรือ Model Inference ทำได้เร็วขึ้นนั่นเอง
ทำไม Deep Learning ถึงเป็นที่สนใจในปัจจุบัน
เราเดินไปตรงไหน เป็นอะไรกันคือ ทุกคนจะต้องบอกว่าเราใช้ AI เราใช้ Deep Learning ในการทำโน้นนี่นั่นไปหมด จนมันกลายเป็น Buzz Word ใช้กันมั่วซั่วไปหมด แต่การที่มันเกิดแบบนี้ขึ้น แปลว่า มันต้องเป็นเรื่องที่น่าสนใจแน่ ๆ ถามว่า ทำไมละ ทำไมมันน่าสนใจ
เพราะ Deep Learning มันเข้ามาทำให้เครื่องสามารถเรียนรู้เรื่องที่มีความซับซ้อนได้มากขึ้น มันมีการตีความปัญหาที่ซับซ้อน และ ยืดหยุ่นสูงมาก หรือแม้กระทั่งที่เราเห็นใช้กันเยอะ ๆ จะเป็นข้อมูลที่เราเรียกว่า Unstructured Data ก็คือพวกข้อมูลที่มันไม่ได้จัดกลุ่มมา เช่น รูปภาพ เสียง หรือแม้กระทั่งข้อความที่เราพิมพ์คุยกันใน Social Media ต่าง ๆ ได้เลย
จากเดิมที่เราอาจจะต้องเอาข้อมูลเหล่านี้มาทำเป็น Feature ผ่านขั้นตอนที่เรียกว่า Feature Extraction เพื่อให้ได้ Feature ที่มีความสำคัญจริง ๆ ที่ทำให้เครื่องสามารถมองแล้วแยก หรือทำนายได้ ใน Deep Learning เราไม่จำเป็นต้องทำแบบนั้นแล้ว เพราะ Model มันสามารถปรับ Weight ปรับค่าความสำคัญให้เองได้เลย ทำให้เราไม่ต้องมานั่งทำ Feature Extraction มากเหมือนกับวิธีเก่า ๆ แล้ว ส่งผลให้ คนเลยเอา Deep Learning มาใช้กับข้อมูลที่เป็น Unstructured เยอะมาก ๆ
มีข้อดีก็ต้องมีข้อเสียบ้างแหละ
อ่านมาถึงตรงนี้คือกำหมัดง้างแล้วว่าอยากใช้ Deep Learning ใจจะขาดแล้ว แต่ข้อเสียของ พวก ANN คือ มันอธิบายไม่ได้ เพราะทั้งหมดมันเกิดจากการเปลี่ยน Weight ในแต่ละ Neuron ไปเรื่อย ๆ แล้วเราจะตีความจากตรงนั้นยังไงว่า อะไรคือสิ่งที่ทำให้ Model มันตัดสินใจบางอย่างออกมา มันบอกได้ยากมาก ๆ
นอกจากนั้น มันยังต้องการข้อมูลจำนวนมาก ๆ ๆ ในการ Train เลย คิดง่าย ๆ ถ้าเป็น Machine Learning แบบอื่น ๆ เรามีการช่วยมันด้วยการทำ Feature Extraction และ การทำ Feature Engineering ที่อาจจะต้องอาศัยผู้รู้เฉพาะทางมาช่วยเลือก Feature ที่สำคัญออกมา เพื่อให้เครื่องมันทำงานได้ง่ายขึ้นมาก่อนแล้ว แต่ถ้าเป็น ANN เลย มันต้องมานั่งหาความสัมพันธ์ของข้อมูลเอง ทำให้มันต้องใช้ข้อมูลเยอะมาก ๆ เพื่อให้มันมั่นใจว่า เออ นี่นะคือ สิ่งที่ถูก เหมือนกับคนเรียนคณิตศาสตร์ ถ้าเราทำโจทย์ไม่เยอะเวลาเราไปทำโจทย์แบบเดียวกัน เราก็จะไม่มั่นใจว่าจะทำถูกมั้ย แต่ถ้าเราทำมาเยอะมาก ๆ ทำอีกกี่ข้อเราก็จะมั่นใจ เหมือนกันเลย
ตัวอย่างการเอาไปใช้งาน
ตัวอย่าง Classic ของการเอา ANN ไปใช้งาน ที่ดึงความดีงามของ ANN ออกมาได้อย่างดีคือปัญหา Image Recognition หรือ การที่เราทำให้เครื่องสามารถบอกได้ว่า สิ่งที่เห็นในภาพคืออะไร เมื่อก่อนอาจจะเป็นเรื่องยากในการทำสักหน่อย แต่พอเรามี ANN แทนที่เราจะต้องมานั่งทำ Feature ออกมา เป็นอะไรไม่รู้ เราสามารถเอาทั้งรูปนั่นแหละ ที่เป็น RGB ยัดเข้าไปใน Model ได้เลย แล้ว Model มันจะไปหาความสัมพันธ์ออกมา แล้วบอกได้เลยว่าในรูปมันคืออะไร นี่คือตัวอย่างนึง
หรือสำหรับใครที่เล่นเกม ช่วงนี้เทคโนโลยีของ Nvidia ที่กำลังมาแรงและเราโคตร Hype กับมันมากคือ DLSS (Deep Learning Super Sampling) มันเป็นเทคโนโลยีที่ใช้ Deep Learning ในการขยายความละเอียดขึ้นไป เช่นเราอยากได้ภาพที่ความละเอียด 4K เมื่อก่อนเราก็ต้องสั่งให้ GPU วาดภาพที่ความละเอียด 4K ออกมาเลย ซึ่งมันใช้เวลาเยอะ แต่ด้วย DLSS เราสามารถสั่งให้ GPU วาดที่ความละเอียดต่ำกว่านั้นอาจจะสัก 1080p แล้วให้มันขยายความละเอียด
ภาพ มันก็เหมือนกับเกมจิ๊กซอร์ ที่ประกอบด้วยหลาย ๆ ชิ้นมารวมกัน ถ้าวันนึงเราอยากที่จะขยายภาพในจิ๊กซอร์จาก 1.5 นิ้ว เป็น 3 นิ้ว มันก็จะมีชิ้นส่วนที่เรามีอยู่แล้วจาก 1.5 นิ้ว และเราก็ต้องหาชิ้นส่วนอีก 1.5 นิ้วมาเติมเพื่อให้ได้รูปเดิมแต่มีขนาดใหญ่ขึ้น DLSS เขาใช้ Deep Learning นี่แหละเพื่อมาช่วยหาอีก 1.5 นิ้วมาเติม ที่เมื่อรวมกับ Hardware ในตระกูล RTX ทำให้เรา Hype มาก ๆ
สรุป : Deep Learning ไม่ใช่พ่อของทุก Solution ใช้อย่างฉลาด และอย่าอินมาก
วันนี้เราพาไปเริ่มต้นกับ Deep Learning ว่ามันมีพื้นฐานมาจากเซลล์ประสาทของมนุษย์เราเอง มันมีการทำงานเป็นอย่างไร และ การที่เรา Train Model จริง ๆ แล้วไส้ในมันเกิดอะไรขึ้นบ้าง จนไปถึงคำถามที่ว่าทำไมเราต้องใช้ GPU กับข้อดีข้อเสียของ Deep Learning ทั้งหมดที่เราเขียนมา อ่านแล้วอาจจะ งง ไม่เข้าใจอะไรบ้าง ก็ลองเอา Keyword ที่เรามีมาให้ไปใช้ในการศึกษาต่อได้ ถือว่าเป็นจุดเริ่มต้นที่อาจจะ งง ๆ หน่อยละกัน
กับสิ่งที่เราอยากจะบอกคือ ทุกคนต้องใจเย็น ๆ วางถุงกาวลงก่อน ก่อนที่จะ Hype กับความ Deep Learning is EVERYWHERE ก่อนนะ คือ เราจะบอกว่า Deep Learning หรือ ANN เฉย ๆ เองก็เถอะ มันไม่ใช่การแก้ปัญหาสำหรับทุกปัญหา ดังนั้นเวลาโดนขายอะไรพวกนี้ลองคิดดี ๆ ก่อนว่ามันจำเป็นหรือเป็นเรื่องของการค้า
ปล. ถ้าสนใจในความคณิตศาสตร์ของมัน ก็ Comment มาบอกในเพจได้ ถ้ามีคนสนเยอะ ๆ เราจะเขียนตอนที่เจาะลึกออกมาให้อ่านกัน อันนั้นแหละ มันส์จริง
Read Next...

รวม Homebrew Package ที่รักส์
Homebrew เป็นอีกหนึ่งเครื่องมือที่เราชอบมาก ๆ มันทำให้เราสามารถติดตั้งโปรแกรม และเครื่องมือต่าง ๆ ได้เยอะแยะมากมายเต็มไปหมด แต่วันนี้ เราจะมาแนะนำ 5 Homebrew Package ที่เรารักส์และใช้งานบ่อยมาก ๆ กันว่าจะมีตัวไหนกันบ้าง...

รวมวิธีการ Backup ข้อมูลที่ทำได้ง่าย ๆ ที่บ้าน
การสำรองข้อมูลเป็นเรื่องสำคัญมาก ๆ อารมณ์มันเหมือนกับเราซื้อประกันที่เราก็ไม่คาดหวังว่าเราจะได้ใช้มันหรอก แต่ถ้าวันที่เราจำเป็นจะต้องใช้การมีมันย่อมดีกว่าแน่นอน ปัญหาคือเรามีวิธีไหนกันบ้างละที่สามารถสำรองข้อมูลได้ วันนี้เราหยิบยกวิธีง่าย ๆ ที่สามารถทำได้ที่บ้านมานำเสนอกัน...

Trust ความเชื่อมั่น แต่ทำไมวงการ Cyber Security ถึงมูฟออนไป Zero-Trust กัน
คำว่า Zero-Trust น่าจะเป็นคำที่น่าจะเคยผ่านหูผ่านตามาไม่มากก็น้อย หลายคนบอกว่า มันเป็นทางออกสำหรับการบริหาร และจัดการ IT Resource สำหรับการทำงานในปัจจุบันเลยก็ว่าได้ วันนี้เราจะมาเล่าให้อ่านกันว่า มันคืออะไร และ ทำไมหลาย ๆ คนคิดว่า มันเป็นเส้นทางที่ดีที่เราจะมูฟออนกันไปทางนั้น...

แปลงเครื่องคอมเก่าให้กลายเป็น NAS
หลังจากเราลงรีวิว NAS ไป มีคนถามเข้ามาเยอะมากว่า ถ้าเราไม่อยากซื้อเครื่อง NAS สำเร็จรูป เราจะสามารถใช้เครื่องคอมเก่าที่ไม่ได้ใช้แล้วมาเป็นเครื่อง NAS ได้อย่างไรบ้าง มีอุปกรณ์ หรืออะไรที่เราจะต้องติดตั้งเพิ่มเติม วันนี้เราจะมาเล่าให้อ่านกัน...